CTF-Misc Guide
 Lunatic
Lunatic最开始接触CTF时,学的最多的就是Misc,各种编码与加密还有各种软件的使用等等
但Misc涉及的范围实在太广了,于是就想着一边学习一边记录,因而就有了这篇文章
最开始接触CTF时,学的最多的就是Misc,各种编码与加密还有各种软件的使用等等
但Misc涉及的范围实在太广了,于是就想着一边学习一边记录,因而就有了这篇文章。
一些奇奇怪怪的经历:
1、一段字符串,用base64异或脚本跑,找正常的字符串
2、rockstar 编程语言,在github上面可以找到,然后在本地用pip安装库,把rock文件转换为py文件,运行即可得到flag
3、给你一个.exe安装包文件,flag藏在安装之前的一大串协议中
4、实在做不出来的时候,可以把flag的格式转其他的编码和题目中的信息比对找规律
5、给你一个gpx文件,在线网站https://www.gpsvisualizer.com/map_input解密,然后地名的首字母连起来就是flag
CTF中的常用关键词
|
|
查找的Python代码:
|
|
|
|
各种文件头/尾:
这里要注意,出题人可能会把文件头的小写字母偷偷改成大写,例如:Rar -> RAR
|
|
各种加密/编码:
base家族
详细请看:https://www.cnblogs.com/0yst3r-2046/p/11962942.html
|
|
base64还可以换表(表中的字符要求不重复)编码,例如
|
|
Tips:base64可以与其他文件格式互相转换(比如图片[会有很多行的base64]),使用在线网站或者随波逐流转换即可 如果出现了很多层乱七八糟的base编码,连CyberChef都识别不出来的话,可以试试用BaseCrack这个开源工具 输入 python basecrack.py -m 运行即可
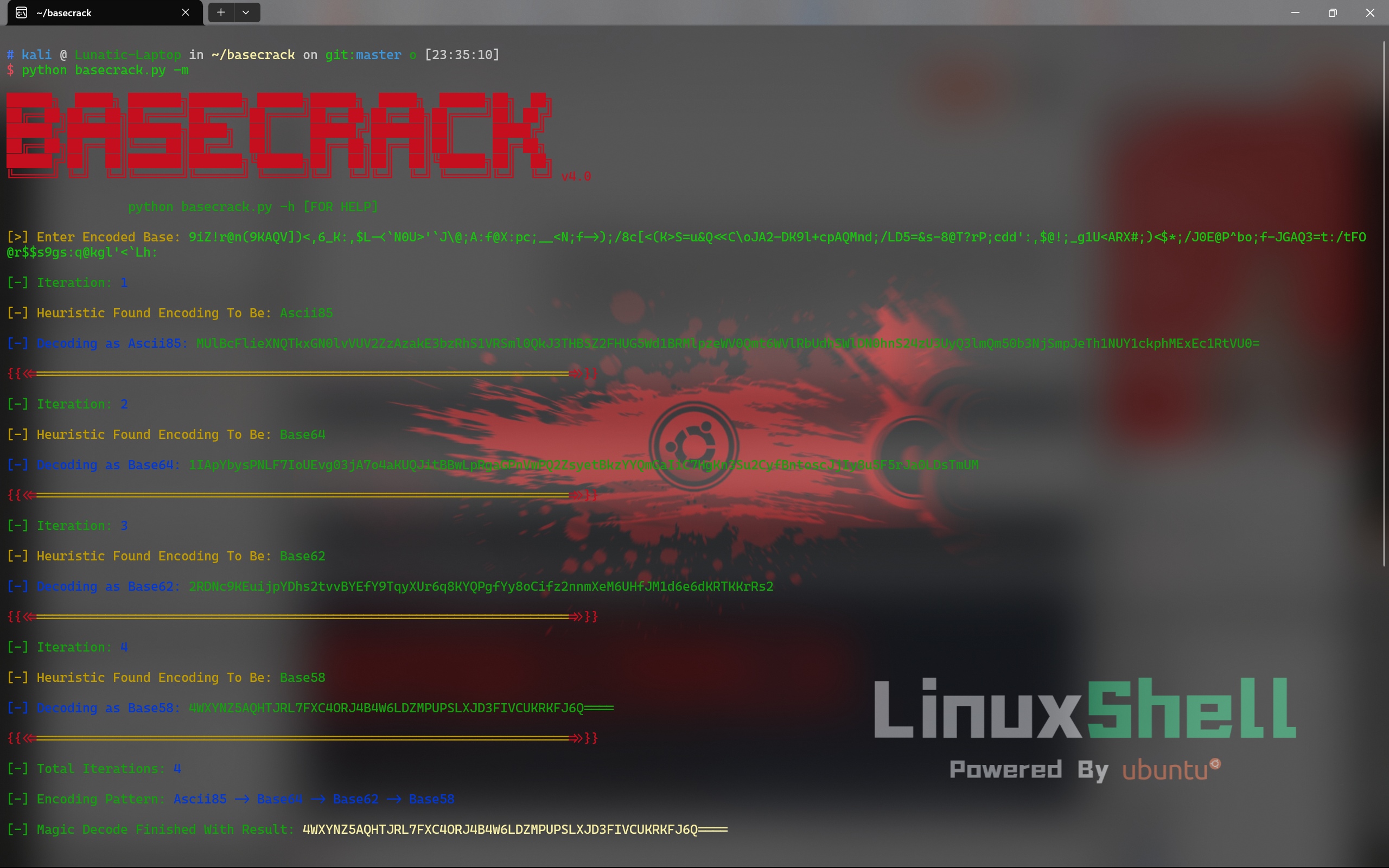
base64隐写:
可以使用以下脚本解密
|
|
|
|
或者直接使用PuzzleSolver解密
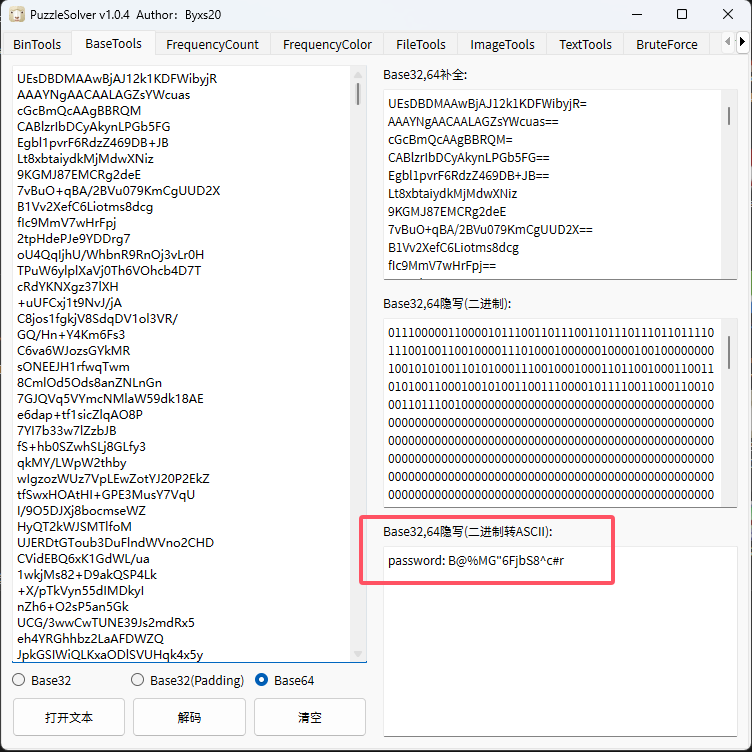
这里要注意多行base64编码可能会出现需要我们自己补全=的情况(例题-攻防世界 MISC - tunnel)
可以使用下面的脚本补全,也可以直接用上面那个工具补全
|
|
MD5加密
|
|
MD5 加密后的密文都是十六进制字符
emoji-aes加密:
密文由一大串emoji表情组成,解密需要密钥
例如已知key:th1sisKey,直接使用在线网站解密即可,也可以下载源码然后本地解密
|
|
词频分析:
给一段字符串,看着什么编码都不像然后也没啥规律的,可能是词频爆破
可以尝试用在线网站quipquip进行词频爆破
这个的爆破原理就是,我们平常可读的字符串中,某些字母出现的频率是差不多的
当我们在解某段密文时不知道具体单表替换的表,也可以尝试直接词频爆破
例题1-2025SUCTF-SU_forensics
字频分析:
直接用随波逐流CTF编码工具统计每个字母出现的次数就行
摩斯电码:
从原理上来说,只要是三种字符构成的编码都有可能是摩斯电码
用 空格 或者 / 做分隔符,然后字符可以用 0和1 或者 .和-
下面举几个典型例子:
|
|
|
|
|
|
vigenere(维吉尼亚)密码:
1、给了密文和密钥:
可以用cyberchef或者在线网站解密
2、给了密文,没给密钥:
可以尝试用在线网站爆破
3、给了密文,没给密钥,但是知道明文的前几位:
可以根据对照表,手搓密钥的前几位,说不定就找到规律直接解出来了
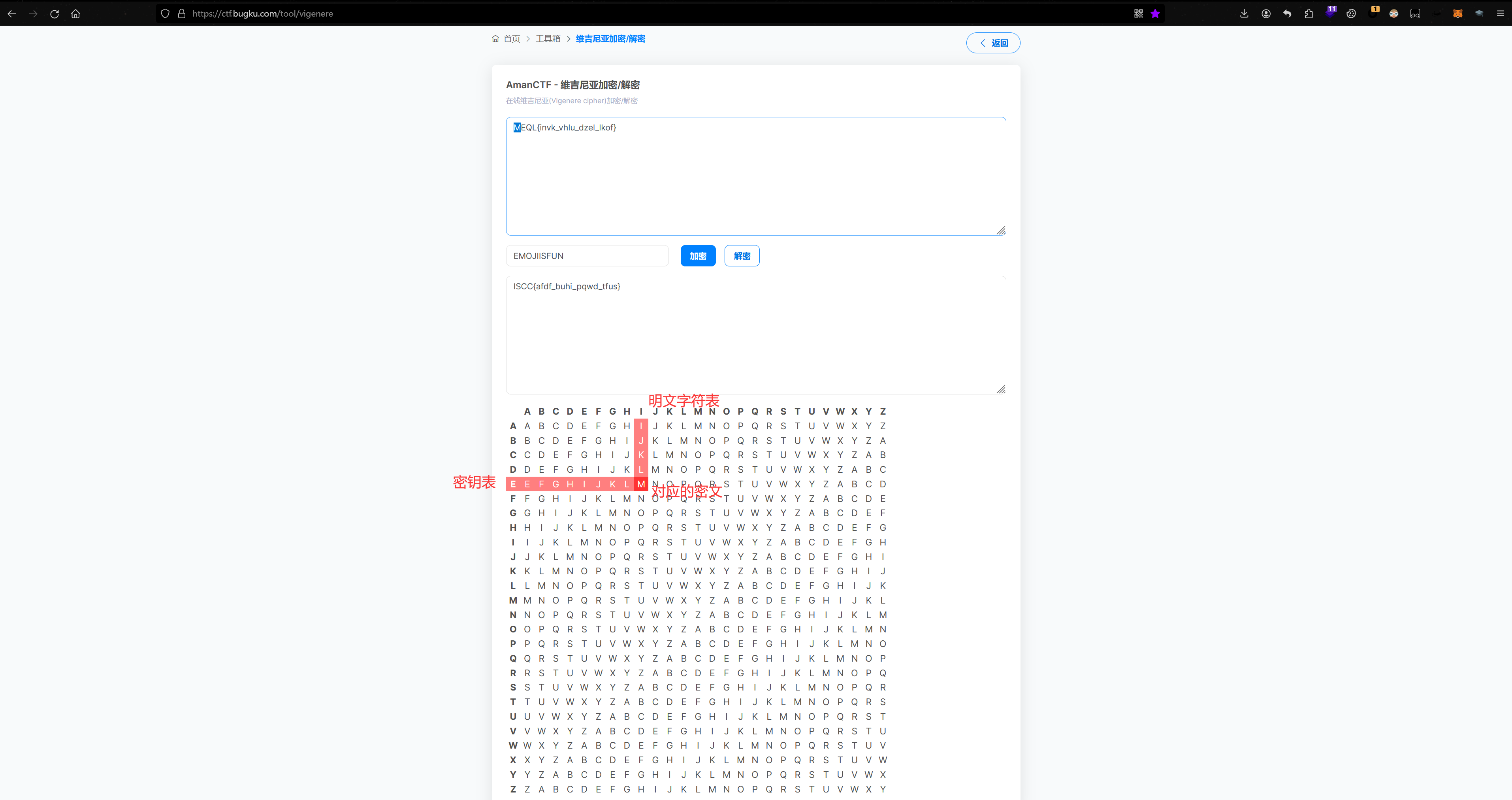 4、给了密钥字典,直接写脚本爆破
4、给了密钥字典,直接写脚本爆破
|
|
希尔密码:
解密网站:http://www.metools.info/code/hillcipher243.html
已知密文和密钥,并且密钥(key)是一个网址,如http://www.verymuch.net
已知密文和密钥,并且密钥是四个数字
|
|
Rabbit加密:
通常题目会提示是用Rabbit加密,然后密文通常以U2FsdGVkX1开头,其实就是Salted加盐了
直接在线网站解密即可
云影密码:
特征是:密文只由01248组成
用随波逐流CTF编码工具解密或者用下面的脚本解密
云影密码的原理就是:以0作为分隔符分组,然后把每组数字相加得到一个数字,这个数字对应的就是26字母中的下标
|
|
曼彻斯特与差分曼彻斯特编码:
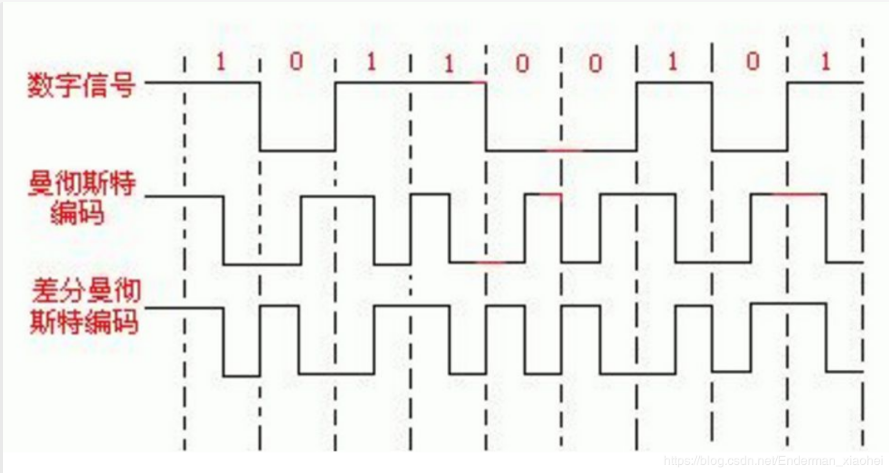
- 曼彻斯特码:从高到低表示 1,从低到高表示 0
- 差分曼彻斯特码:在每个时钟周期的起始处(虚线处)有跳变表示 0;无跳变则表示1。
可以直接使用 曼彻斯特编码 转换工具转换
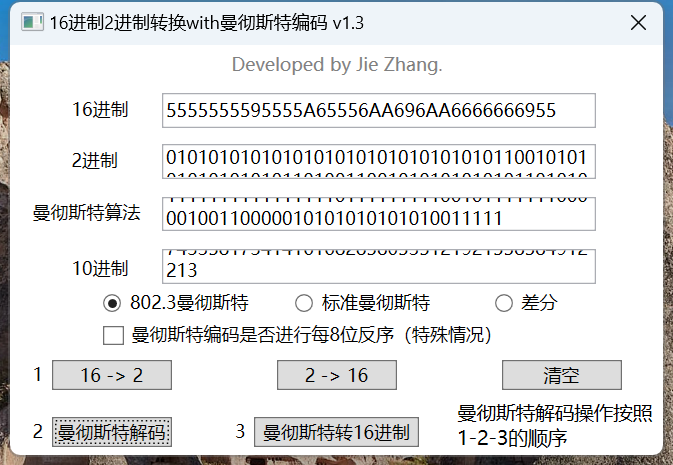
例题1 2016CISCN-传感器1
5555555595555A65556AA696AA6666666955
这是某压力传感器无线数据包解调后但未解码的报文(hex)
已知其ID为0xFED31F,请继续将报文完整解码,提交hex。
提示1:曼联
|
|
例题2 2016CISCN-传感器2
现有某ID为0xFED31F的压力传感器,已知测得
压力为45psi时的未解码报文为:5555555595555A65556A5A96AA666666A955
压力为30psi时的未解码报文为:5555555595555A65556A9AA6AA6666665665
请给出ID为0xFEB757的传感器在压力为25psi时的解码后报文
和上面那题的思路一样,就是最后多了一步压力位算法和校验位算法猜测
压力位算法:压力每增加5psi压力值增加11
校验位算法:校验值为从ID开始每字节相加的和模256的十六进制值即为校验值
例题3 2017CISCN-传感器1
已知ID为0x8893CA58的温度传感器的未解码报文为:3EAAAAA56A69AA55A95995A569AA95565556
此时有另一个相同型号的传感器,其未解码报文为:3EAAAAA56A69AA556A965A5999596AA95656
请解出其ID,提交flag{不含0x的hex值}
开头的3E提示了差分曼彻斯特编码,就是根据上图中的跳变位置解码
|
|
例题4 2017CISCN-传感器2
已知ID为0x8893CA58的温度传感器未解码报文为:3EAAAAA56A69AA55A95995A569AA95565556
为伪造该类型传感器的报文ID(其他报文内容不变),请给出ID为0xDEADBEEF的传感器1的报文校验位(解码后hex)以及ID为0xBAADA555的传感器2的报文校验位(解码后hex),并组合作为flag提交。
例如,若传感器1的校验位为0x123456,传感器2的校验位为0xABCDEF,则flag为flag{123456ABCDEF}。
解码步骤和上题一样,就是多考察了一个校验位算法(CRC8)
在最后的结果前面补一个0,然后再计算 CRC8 即可
社会主义核心价值观密码:
密文由社会主义核心价值观种的词语构成
直接用在线网站或者随波逐流CTF编码工具解密即可
当然也可以写Python脚本调用第三方模块解密
音乐符号加密:
Tips:这里要注意,加密的密文一定是以 = 结尾的,有时候需要自己把=加上
eg:♭♯♪‖¶♬♭♭♪♭‖‖♭♭♬‖♫♪‖♩♬‖♬♬♭♭♫‖♩♫‖♬♪♭♭♭‖¶∮‖‖‖‖♩♬‖♬♪‖♩♫♭♭♭♭♭§‖♩♩♭♭♫♭♭♭‖♬♭‖¶§♭♭♯‖♫∮‖♬¶‖¶∮‖♬♫‖♫♬‖♫♫§=
直接用在线网站解密即可:https://www.qqxiuzi.cn/bianma/wenbenjiami.php?s=yinyue
敲击码:

|
|
Polybius密码(波利比奥斯方针密码)
类似于11,22,11,24这样的
逗号改成空格,拉入随波逐流CTF编码工具直接解密即可
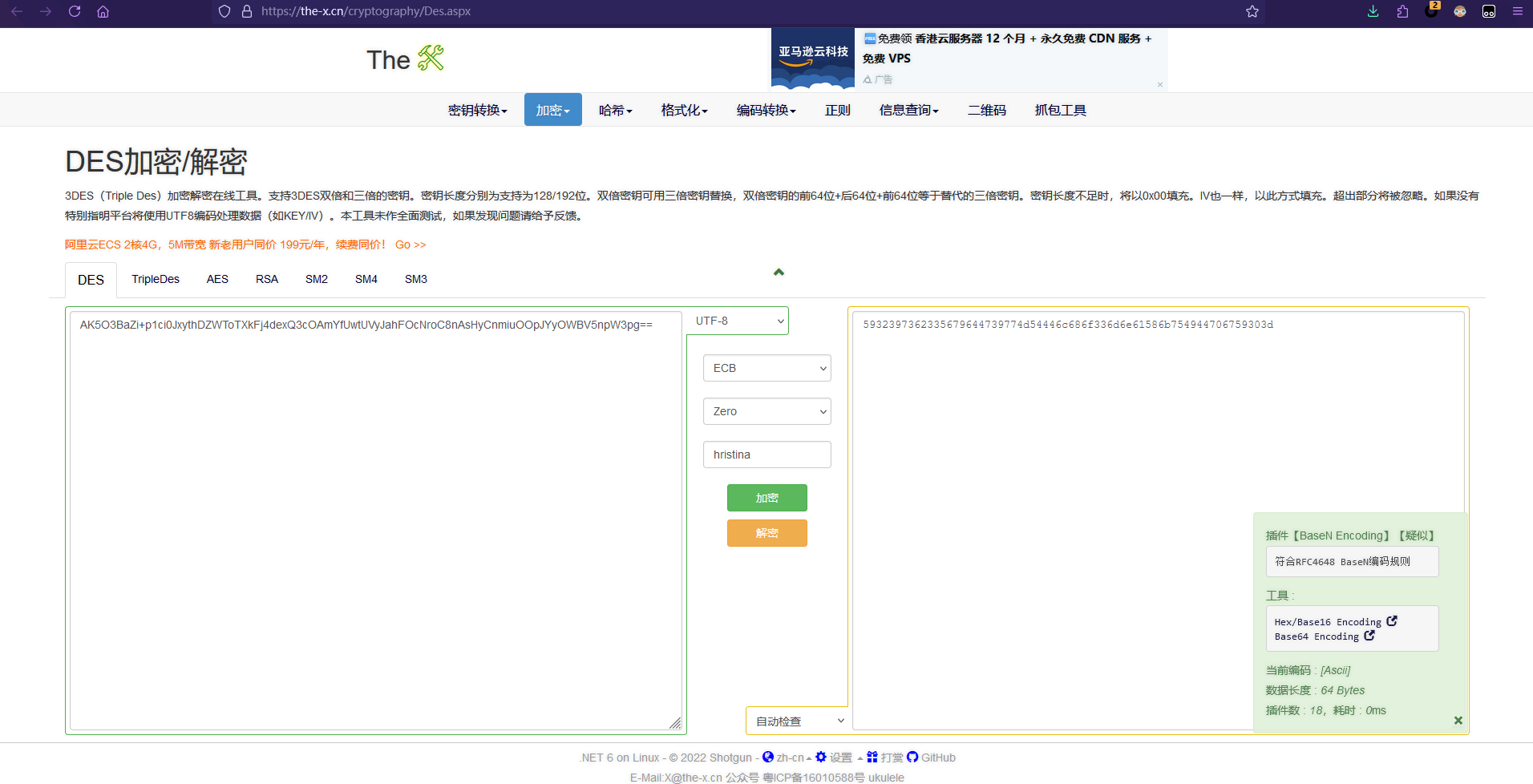
DES加密
例子:
|
|
直接用在线网站解密即可
AES加密算法
可以尝试用CyberChef或者在线网站解密:
|
|
AES-ECB(不需要IV)
如果 key 不足16字节可以尝试在后面补0
AES-CBC(需要IV)
Tips: CBC模式下key的长度必须是16bytes的整数倍,但是IV不一定
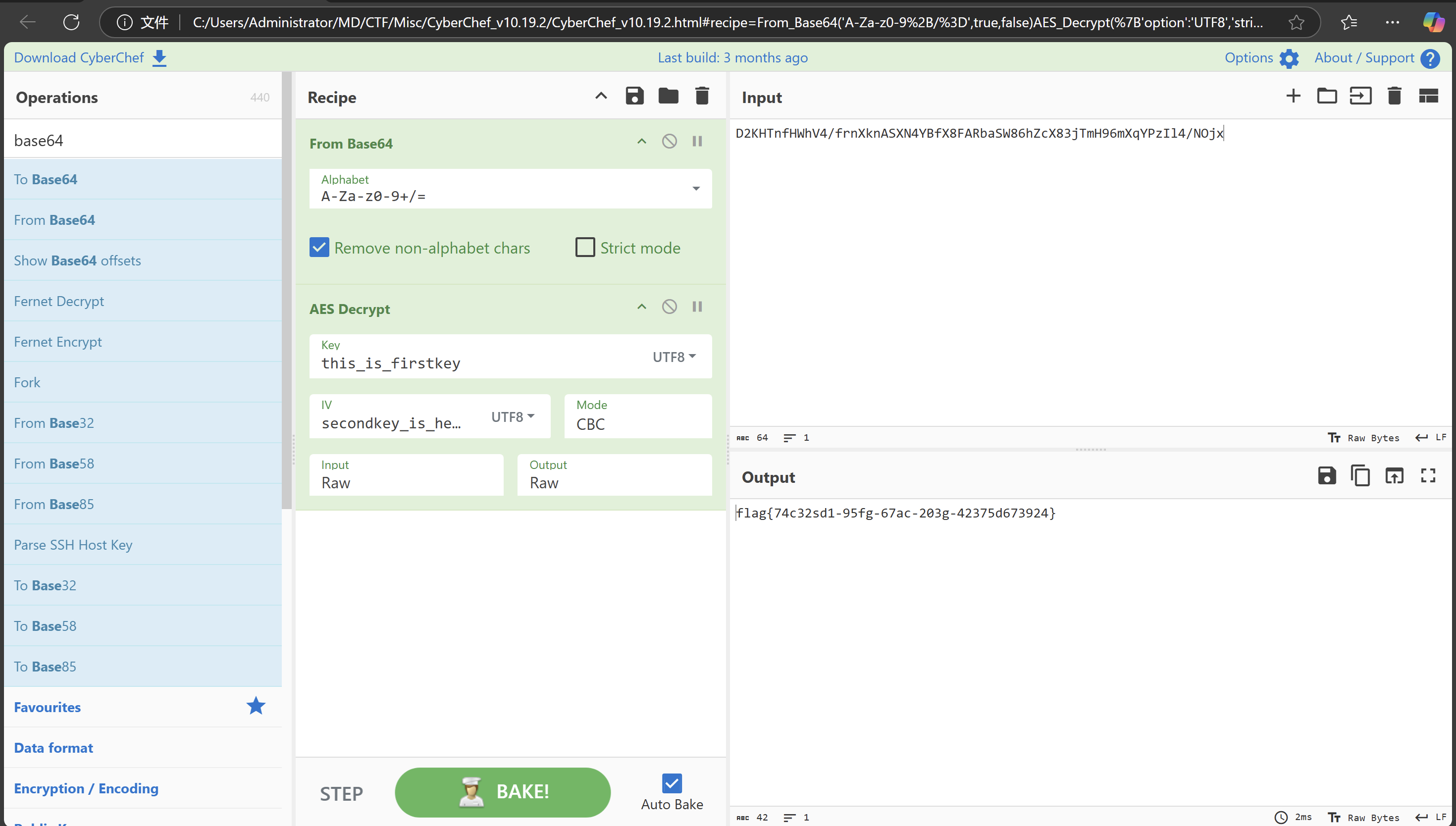
密钥不足16字节时需要padding补齐16字节
可以使用能自动补齐的在线网站解密 https://www.sojson.com/encrypt_aes.html
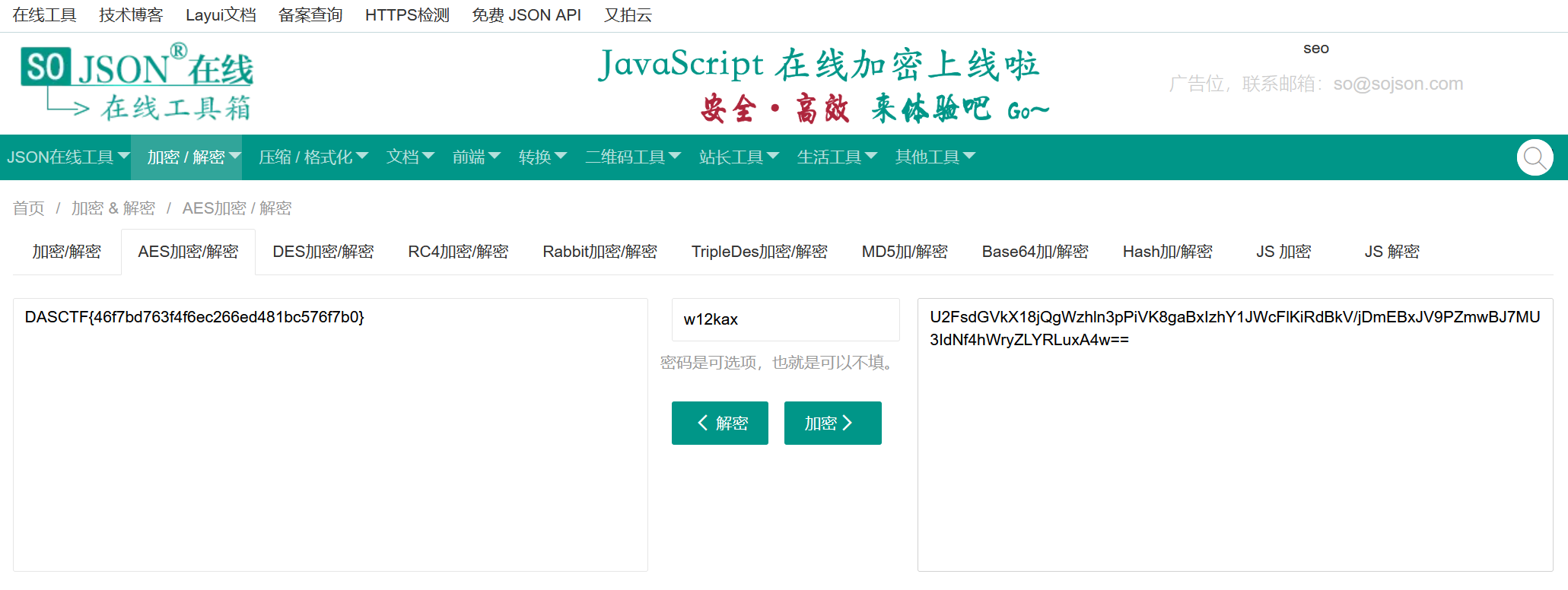
也可以用CaptfEncoder-win-x64-1.3.0解密
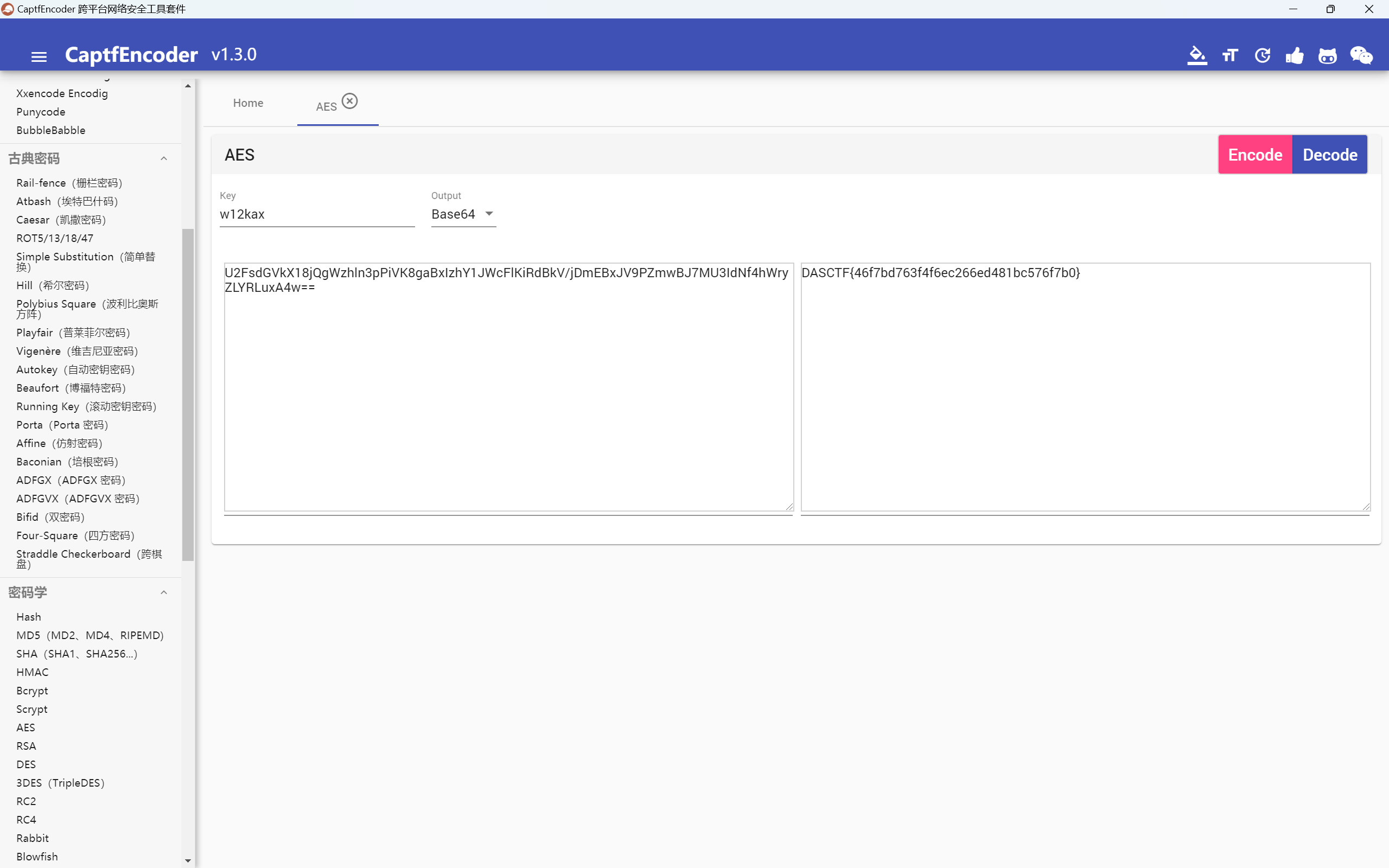
使用openssl进行加解密
|
|
埃特巴什码(Atbash)
例如下面这段密文
|
|
直接用CyberChef或者随波逐流CTF编码工具解密即可
|
|
DNA编码
|
|
1、使用CTFD中的DNAcode脚本解密
https://github.com/omemishra/DNA-Genetic-Python-Scripts-CTF
2、网上找的脚本(红明谷杯2023——hacker)
|
|
3、使用在线网站解密(例题-BUGKU-粉色的猫)
DNA编码在线解密:https://earthsciweb.org/js/bio/dna-writer/
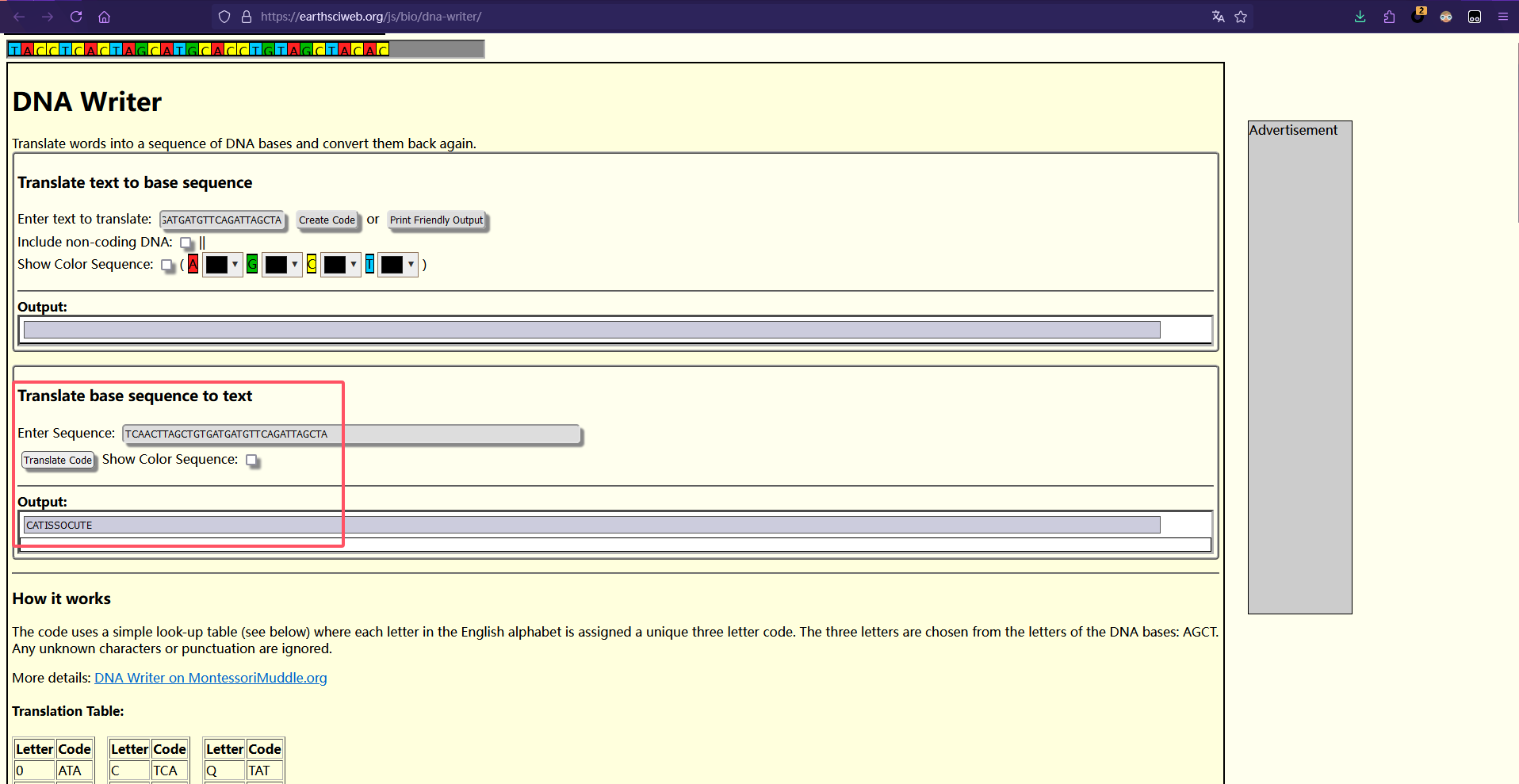
金笛短信PDU编码
直接使用在线网站解码:http://www.sendsms.cn/pdu/ (特别注意:需要一行一行地解码)
形如下面这串数字
|
|
一行一行解码后可以得到
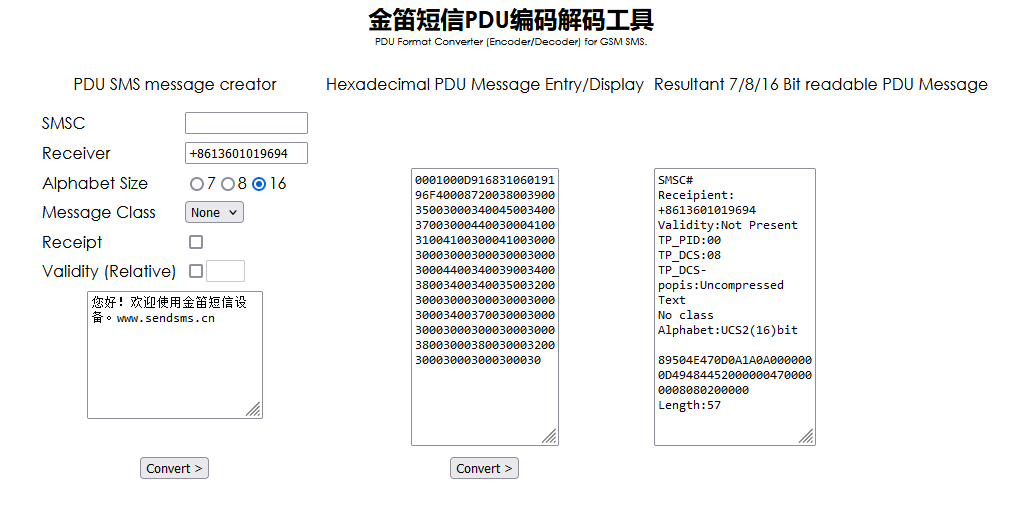
|
|
例题-BUGKU-粉色的猫
Text Encoding Brute Force
如果赛博厨子转完两次Hex后依然是乱码,可以用Text Encoding Brute Force爆破试试看
例子:红明谷杯2023——阿尼亚
Decabit编码
正常的 Decabit编码 是十个字符一组的,如果不是十个一组,就很可能不是 Decabit编码
|
|
直接使用 在线网站 解密即可
如果不是Decabit编码,可以试试看把+-分别用01替换 (例题1-2023楚慧杯-Easy_zip)
仿射密码
密钥有两个参数a和b,a为必须是1,3,5,7,9,11,15,17,19,21,23,25中的一个(与26互质)
b可以是0到25之间的任意整数
可以使用在线网站或者随波逐流CTF编码工具解密
|
|
Brainfuck和Ook!编码
可以直接用以下几个在线网站解密:
https://www.splitbrain.org/services/ook
https://www.geocachingtoolbox.com/index.php?lang=en&page=brainfuckOok
https://www.cachesleuth.com/bfook.html
Brainfuck
|
|
Ook!
|
|
short Ook!
|
|
有时候flag可能会被删去,导致直接在线网站解密看不到flag,需要我们到内存中查看被删除的内容
因此可以用下面这个代码输出之前放在内存中的内容
|
|
Gronsfeld密码
1、可以直接使用这个在线网站解密或爆破
2、也可以写Python脚本解密
|
|
UUencode编码
看起来有点像base85编码,可以直接使用在线网站或者随波逐流CTF编码工具解密
|
|
AAencode编码
可以直接使用在线网站或者随波逐流CTF编码工具解密
XXencode编码
可以直接使用在线网站或者随波逐流CTF编码工具解密
例题1-2023浙江省赛决赛-签到
无字天书(whitespace)或者snow隐写
一个文件打开都是空白字符
whitespace可以使用在线网站解密,复制进去直接run即可
snow隐写可以下载源码,然后到根目录下运行 SNOW.EXE -C -p password flag.txt 命令即可
Tips:snow隐写有时候可以不全是空白字符,然后也可以无密码,如果懒得敲命令行可以直接用下面这个工具
零宽字符隐写
可以用在线网站解密,也可以用PuzzleSolver解密
|
|
中文电报(中文电码)
类似于下面这种四位数一组的编码,直接在线网站或随波逐流CTF编码工具解码即可
|
|
|
|
Quote-Printable编码
类似于下面这样的编码,直接使用 在线网站 或随波逐流CTF编码工具解密即可
|
|
Unicode编码
这个编码有很多种格式,比如+U、\u、\x、&#啥的
可以使用这个在线网站解码:https://r12a.github.io/app-conversion/
中文ascii码
|
|
加上&#和分号,直接CyberChef或者 在线网站 解密即可
|
|
培根密码
密文由ab或者AB或者01组成,密文中只有两种字符,可以直接使用随波逐流CTF编码工具解密
Tips:CyberChef 的培根密码解密可能会有点问题,这里建议用随波逐流解密
锟斤拷
这个东西的成因是Unicode的替换字符与UTF-8编码下的结果EF BF BD重复
然后这几个字符在GBK编码中被解码为汉字 “锟斤拷”(EF BF BD EF BF BD)
|
|
电脑键盘密码
电脑键盘坐标密码
|
|
例题-i春秋-misc3
|
|
电脑键盘QWE加密

|
|
电脑键盘位移加密
|
|
手机键盘密码
26键键盘密码
字母对应上档的数字
|
|
然后数字对应九键上的按键,出现次数对应第几个字母
|
|
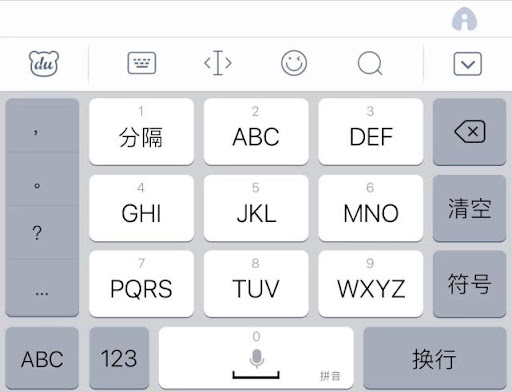
九宫格键盘密码
第一种
参考链接:https://blog.csdn.net/qq_55011640/article/details/123626280
对照表如下:
| 密码 | 明文 | 密码 | 明文 |
|---|---|---|---|
| 11 | : | 61 | m |
| 12 | _ | 62 | n |
| 13 | - | 63 | o |
| 21 | a | 71 | p |
| 22 | b | 72 | q |
| 23 | c | 73 | r |
| 31 | d | 74 | s |
| 32 | e | 81 | t |
| 33 | f | 82 | u |
| 41 | g | 83 | v |
| 42 | h | 91 | w |
| 43 | i | 92 | x |
| 51 | j | 93 | y |
| 52 | k | 94 | z |
| 53 | l |
举个栗子就理解了:
|
|
第二种
仔细看看就会发现其实和上面那种是一样的,就是这种情况下是用数字出现的次数表示方格中的位置
| 密码 | 明文 | 密码 | 明文 |
|---|---|---|---|
| 111 | : | 666 | m |
| 11 | _ | 66 | n |
| 1 | - | 6 | o |
| 222 | a | 7777 | p |
| 22 | b | 777 | q |
| 2 | c | 77 | r |
| 333 | d | 7 | s |
| 33 | e | 888 | t |
| 3 | f | 88 | u |
| 444 | g | 8 | v |
| 44 | h | 9999 | w |
| 4 | i | 999 | x |
| 555 | j | 99 | y |
| 55 | k | 9 | z |
| 5 | l |
不同键盘布局的编码
Qwerty

Qwertz
Azerty

Dvorak(德沃夏克键盘)


Colemak

例题-2023台州市赛初赛-Black Mamba
棋盘密码(ADFGVX,ADFGX,Polybius)

直接使用CaptfEncoder或者随波逐流等工具输入密文和密钥解密即可
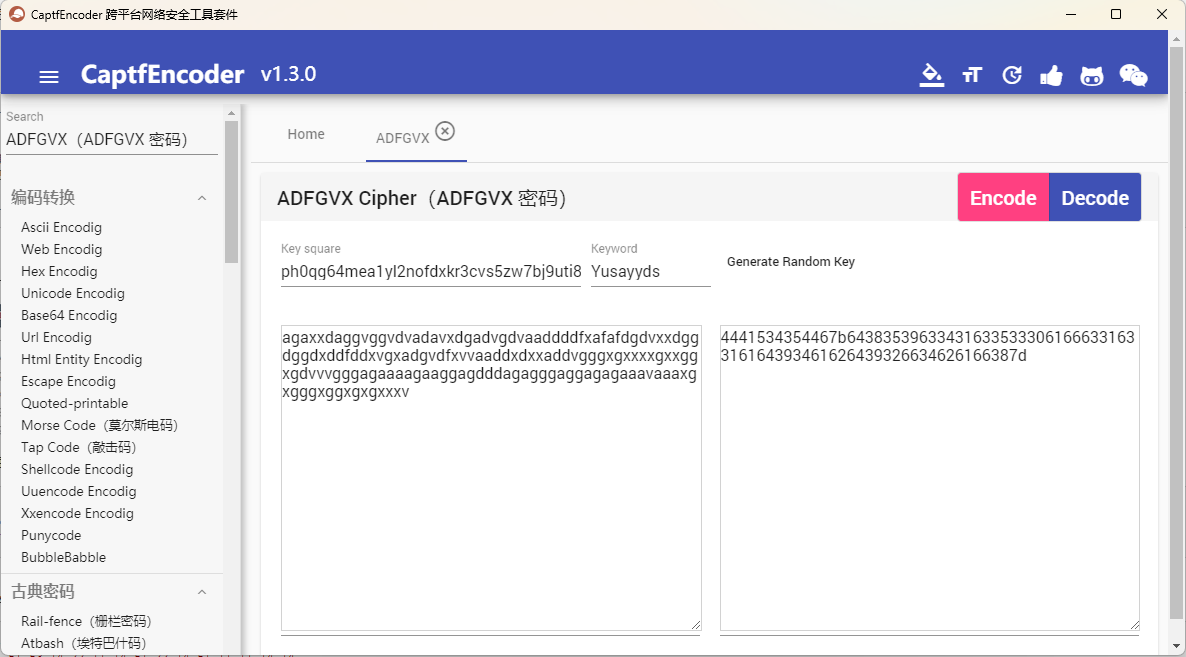
ADFGVX密码 默认棋盘:ph0qg64mea1yl2nofdxkr3cvs5zw7bj9uti8 默认密钥:german
ADFGX密码 默认棋盘:phqgmeaynofdxkrcvszwbutil 默认密钥:german
波利比奥斯方阵密码 密钥:随机 默认密文字符:ABCDE
利用编程代码画图
1、LOGO编程语言【例题-RCTF2019-draw】
在线编译器:https://www.calormen.com/jslogo/
2、CFRS编程语言【例题-2024宁波市赛初赛-Misc2】
在线画图网站:https://susam.net/cfrs.html
通过拼音和声调进行编码
例题-惠州学院红帽协会CTF招新赛-Crypto-xuanxue
|
|
|
|
当铺密码
当铺密码就是一种将中文和数字进行转化的密码:
当前汉字有多少笔画出头,就是转化成数字几
|
|
简/繁体汉字笔画编码
|
|
PGP词汇表加密
密文格式大致如下:
例题1
endow gremlin indulge bison flatfoot fallout goldfish bison hockey fracture fracture bison goggles jawbone bison flatfoot gremlin glucose glucose fracture flatfoot indoors gazelle gremlin goldfish bison guidance indulge keyboard keyboard glucose fracture hockey bison gazelle goldfish bison cement frighten gazelle goldfish indoors buzzard highchair fallout highchair bison fallout goldfish flytrap bison fallout goldfish gremlin indoors frighten fracture highchair bison cement fracture goldfish flatfoot gremlin flytrap fracture buzzard guidance goldfish freedom buzzard allow crowfoot jawbone bison indoors frighten fracture bison involve fallout jawbone Burbank indoors frighten fracture bison guidance gazelle flatfoot indoors indulge highchair fracture bison hockey frighten gremlin indulge flytrap bison flagpole fracture bison indulge hockey fracture flytrap bison allow blockade endow indulge hockey fallout blockade bison gazelle hockey bison inverse fracture highchair jawbone bison gazelle goggles guidance gremlin highchair indoors fallout goldfish indoors bison gazelle goldfish bison indoors frighten gazelle hockey bison flatfoot frighten fallout glucose glucose fracture goldfish freedom fracture blackjack blackjack
例题2-2024国城杯-Tr4ffIc_w1th_Ste90
I randomly found a word list to encrypt the flag. I only remember that Wikipedia said this word list is similar to the NATO phonetic alphabet.
crumpled chairlift freedom chisel island dashboard crucial kickoff crucial chairlift drifter classroom highchair cranky clamshell edict drainage fallout clamshell chatter chairlift goldfish chopper eyetooth endow chairlift edict eyetooth deadbolt fallout egghead chisel eyetooth cranky crucial deadbolt chatter chisel egghead chisel crumpled eyetooth clamshell deadbolt chatter chopper eyetooth classroom chairlift fallout drainage klaxon
解密脚本:
|
|
VBS加密
例题1-2024国城杯-Just_F0r3n51Cs
enc.vbe内容如下
|
|
直接使用在线网站解密为vbs即可
日历密码
例题1-QHCTF For Year 2025

Twitter Secret Messages
特点就是密文中有很多Unicode字符,直接用在线网站解密即可:https://holloway.nz/steg/
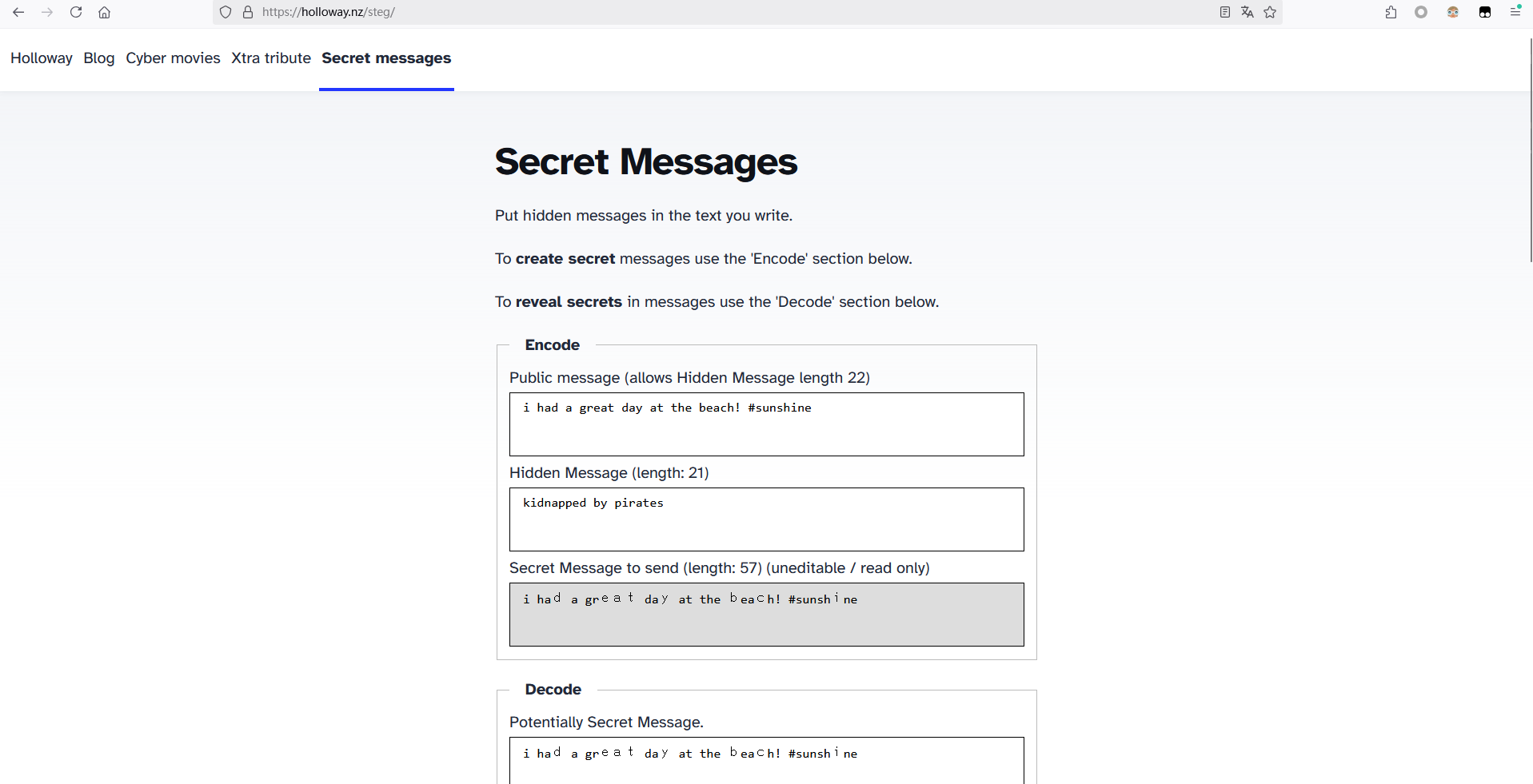
盲文

瓦坎达文字对照表

喜羊羊与灰太狼-羊文对照表

旗语
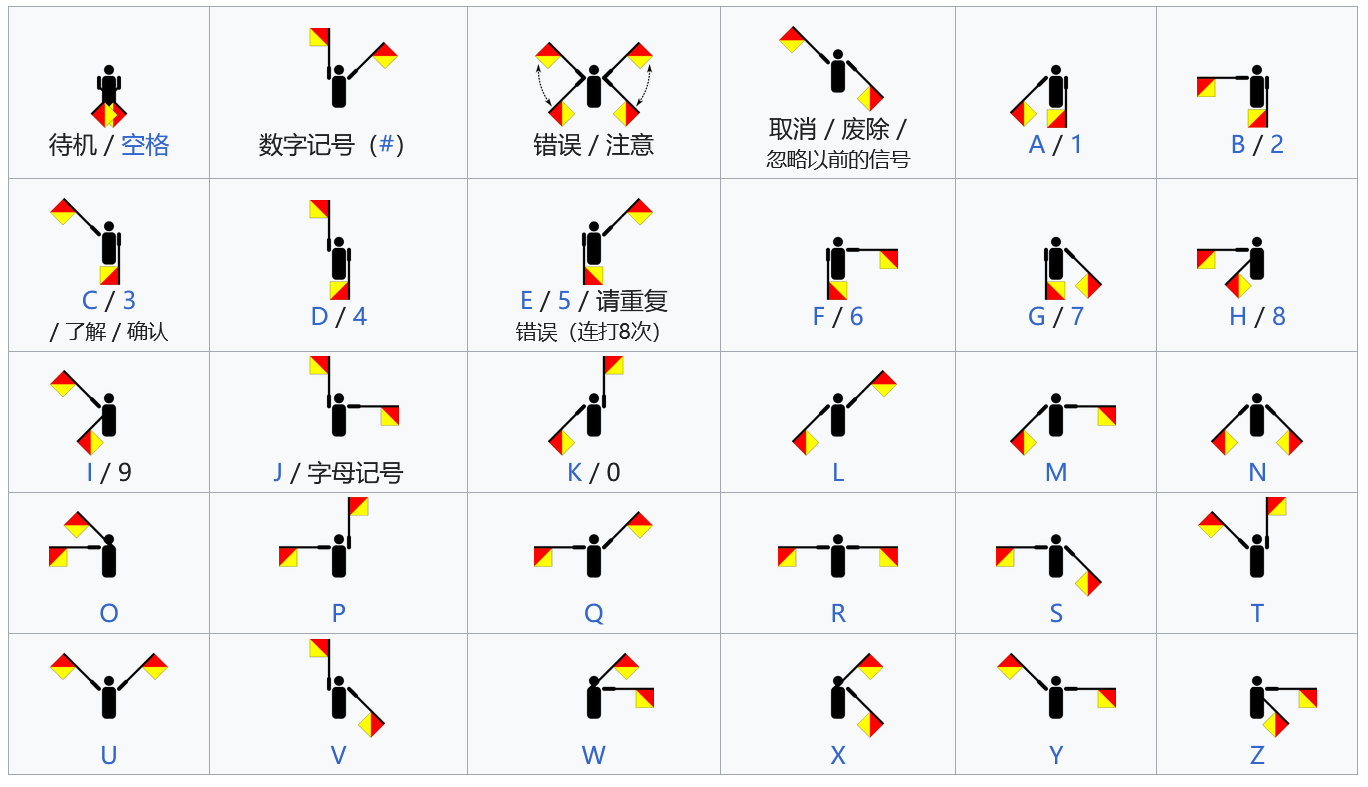
博多码
|
|
直接用随波逐流CTF编码工具解密即可
Misc——流量分析
详见作者博客中的 Network Traffic Analysis 这篇文章
MIsc——图片题思路:
Tips:
1.各种隐写可以先拉入一键梭哈网站解析一下:https://aperisolve.fr/
2.各种乱七八糟的隐写可以先看看这个UP主的视频:https://space.bilibili.com/39665558
通用思路
1、查看图片属性的详细信息(可能关键信息就在里面)
2、拉入010,查看文件头尾
3、foremost 或者 binwalk
如果foremost没有提取出东西,可以用binwalk试一下,可能binwalk可以提取出东西
例题-i春秋CTF-Misc-class10
4、盲水印隐写(可能是一张图片或者两张图片)
可以直接用PuzzleSolver处理
一张图片的情况
可以使用隐形水印工具V1.2或者WaterMark工具来提取水印
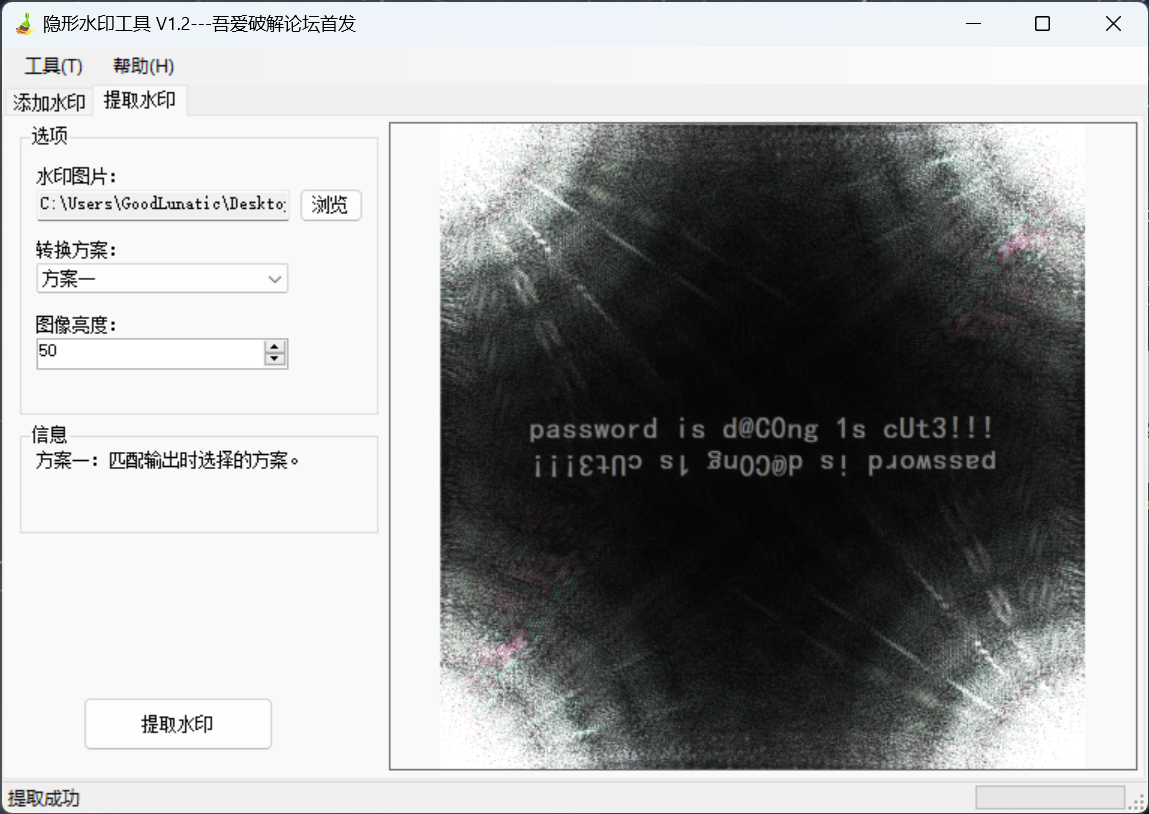
两张图片的情况
|
|
5、图片的分离和拼接
(1)可以用kali的convert分离和montage拼接命令
|
|
(2)使用在线网站分解:https://tu.sioe.cn/gj/fenjie/
(3)用Python脚本跑
|
|
6、Image conbiner(两张图片)
两张图片可能有部分残缺(可以互补)
给了两张图片时,用Stegsolve打开其中一张,
然后再Analyze-Image conbiner打开另一张图片
还有可能是给了两张二维码,需要两个二维码每个像素亦或
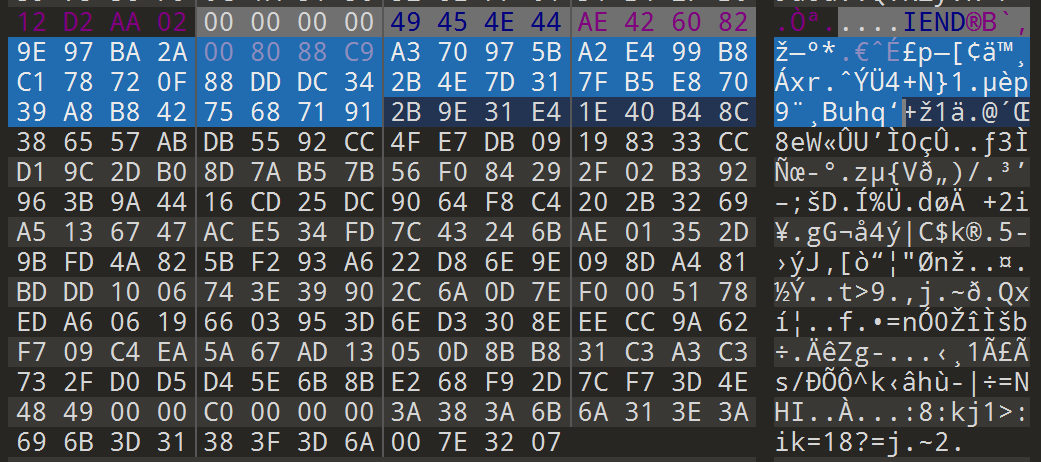
7、OurSecret隐写(可以无密码)
拉入OurSecret,输入密码(也可以无密码)解密,得到隐藏文件
OurSecret隐写的特征非常明显,如下图中标蓝的那40字节
|
|
8、拼图题
碎图片合成一张图片
|
|
|
|
然后把上面合成好的图片使用 Puzzle-Merak 工具进行智能拼图

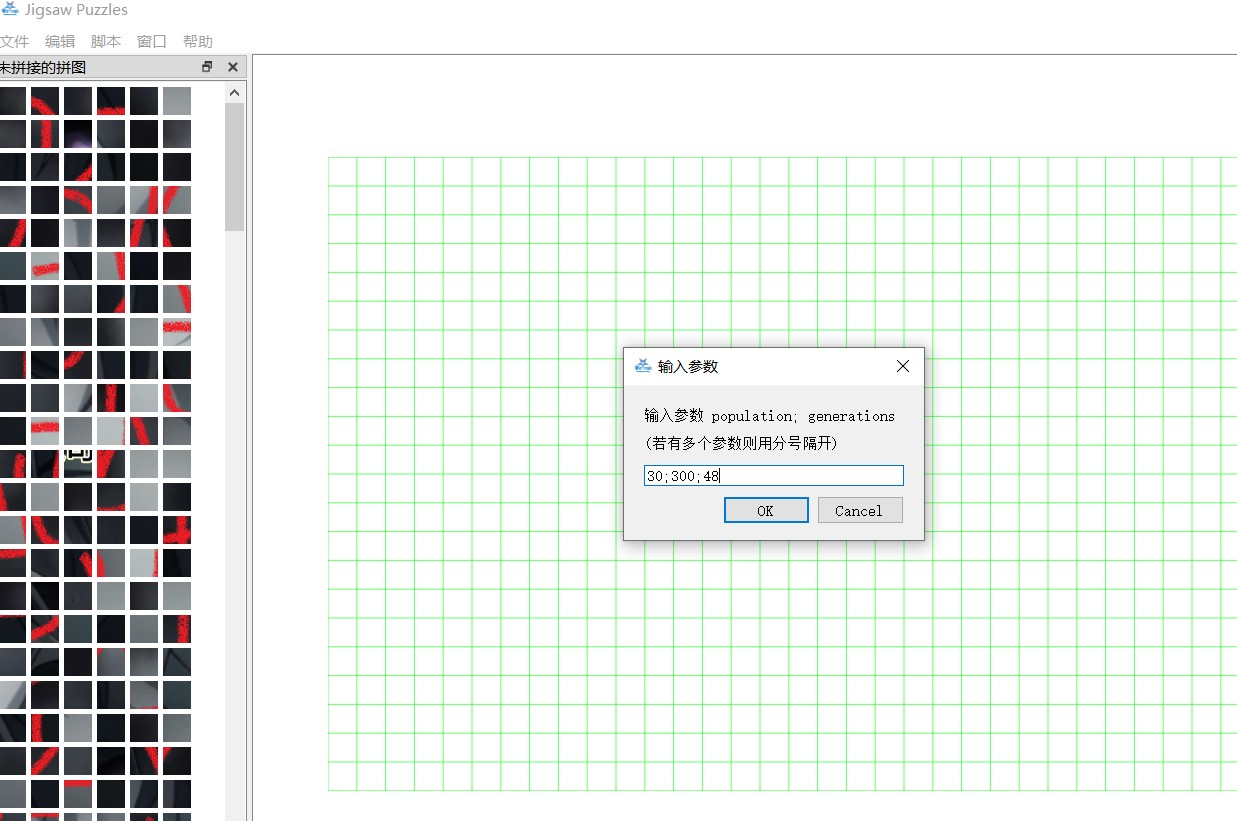
这里只需要输入 generation、population、size 并用分号分开即可开始自动拼图
也可以使用gaps智能拼图(在kali和wsl里使用都可以)
|
|
|
|
9、提取图中等距像素点/近邻法缩放图片
参考链接:
https://www.bilibili.com/video/BV1Lf4y1r7dZ/?spm_id_from=333.999.0.0
例题-2024浙江省赛决赛-天命人
拿下面这张图片举个栗子

方法一:直接在PS中将宽高都缩小为原来的十分之一,并选择邻近硬边缘即可直接得到隐藏的图片
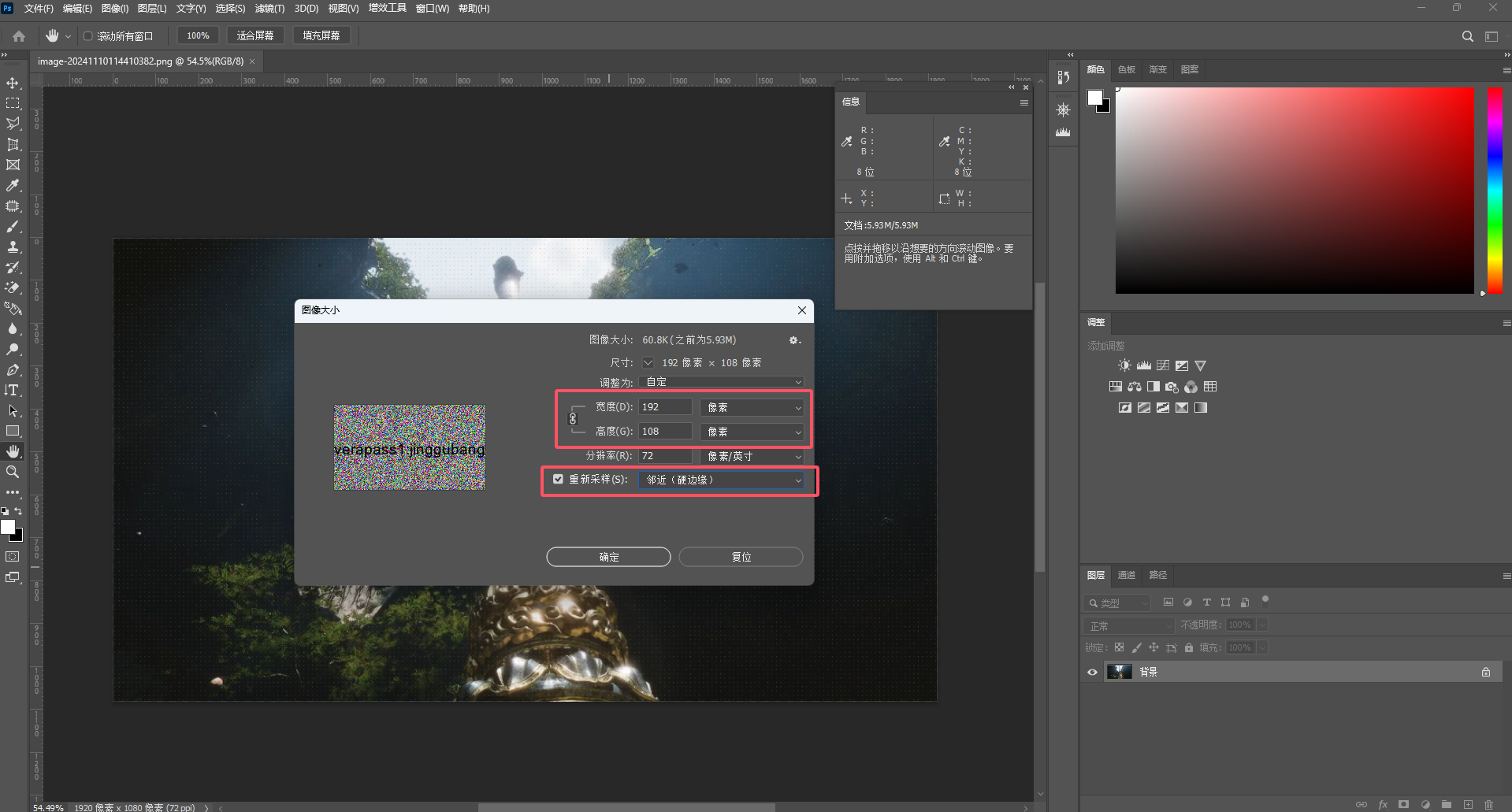
方法二:在windows的终端中运行CTFD中的Get_Pixels.py(注意所有路径中都不要出现中文)
|
|
这里有时候运行会报错,需要把main.py脚本拉到桌面上运行或者检查一下图片的CRC对不对
一样可以得到隐藏的图片

10、pixeljihad(有密码)
直接使用在线网站解密即可:PixelJihad (sekao.net)
11、隐写文本可能藏在原图片和隐写文件的中间
直接在010中运行对应文件类型的模板,依次查看文件头尾有无额外内容即可
12、DeEgger Embedder隐写
可以直接使用 DeEgger Embedder 工具 extract files
13、flag可能藏在 exif 中
直接在 WSL 中输入以下命令查看即可,如果偷懒也可以直接使用 破空 flag 查找工具 进行查找
|
|
14、给了两张图片,flag藏在每行不同像素的个数中
例题1-2023羊城杯初赛-两支老虎
|
|
15、两张图片,用StegSolve中的Image Conbiner合成为一张bmp
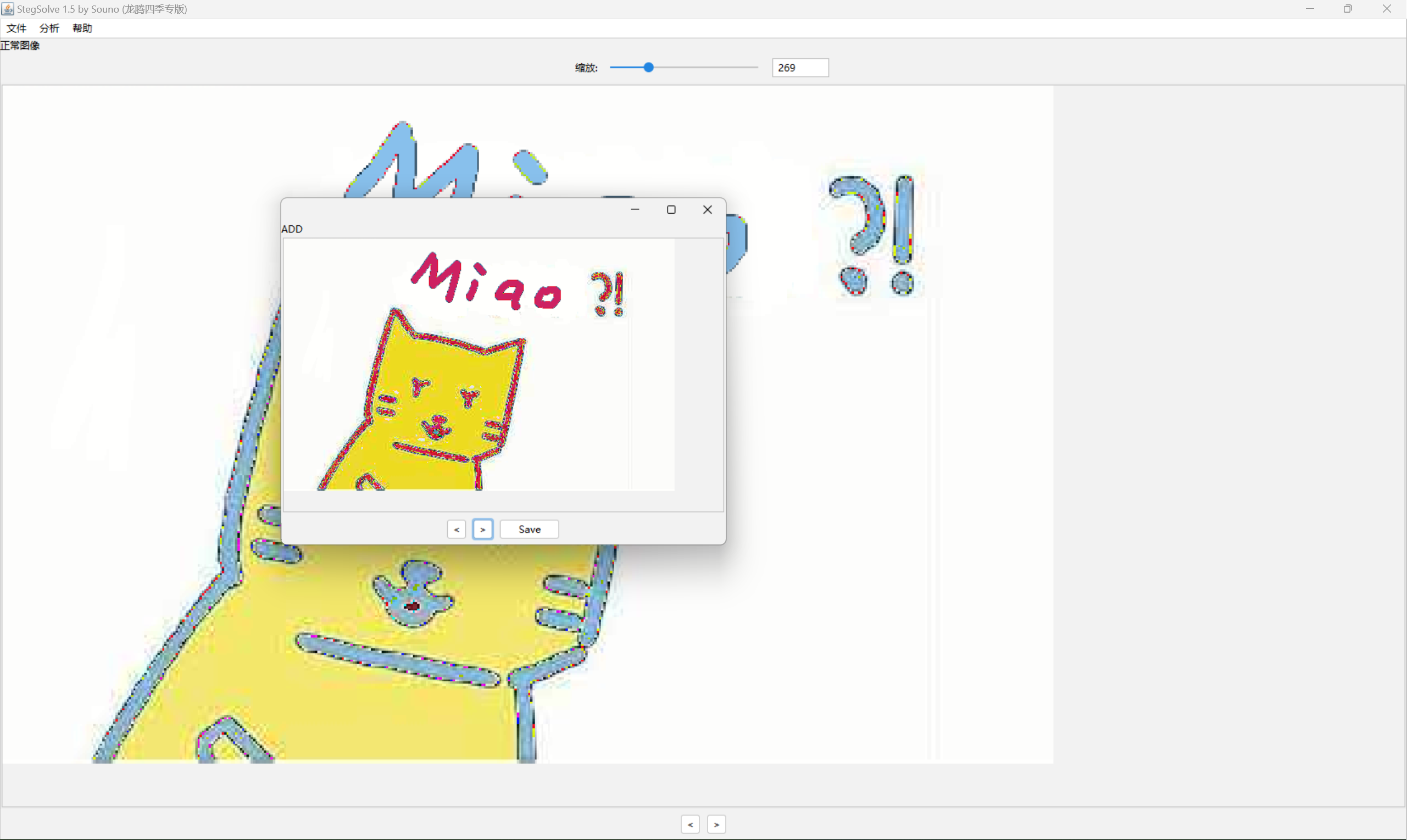
合成一张bmp后,再使用zsteg扫描
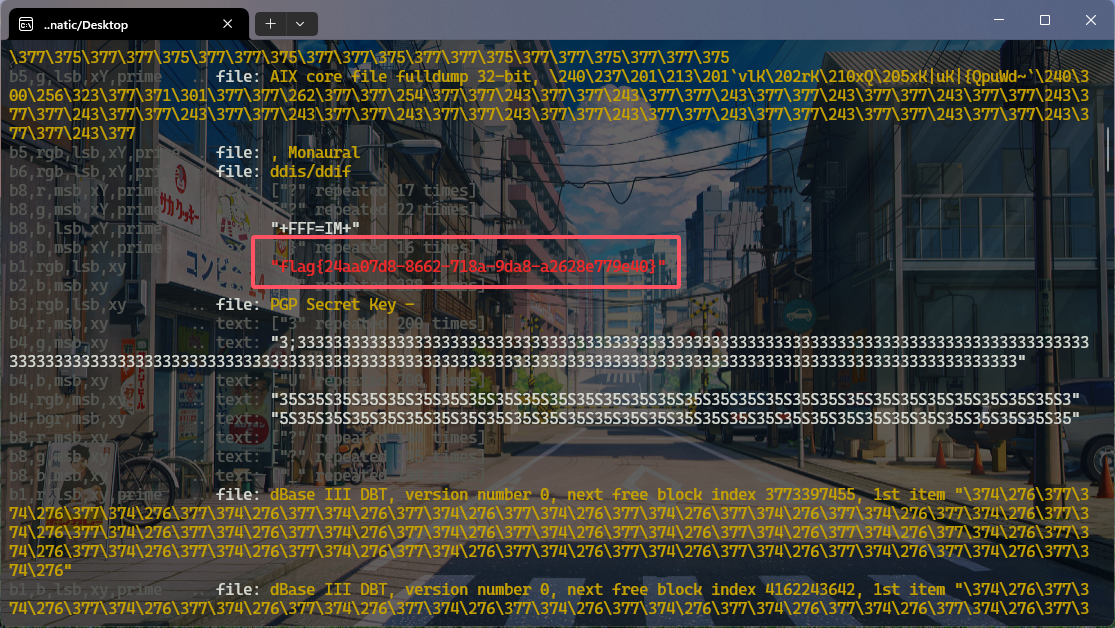
16、图片多个通道存在LSB隐写,StegSolve中把背景颜色相同的勾选上
17、把小说藏进图片
参考链接:https://www.bilibili.com/video/BV1Ai4y1V7rg/?spm_id_from=333.999.0.0&vd_source=31399c09aa0c93655468bde7b13fcc03
|
|
|
|
18、Arnold猫脸变换
参考链接:https://1cepeak.cn/post/arnold/
如果已经得到了shuffle_times、a和b,然后直接使用下面这个脚本恢复即可
|
|
如果题目没有给我们上面的三个参数,我可以尝试爆破一下
例题-cat(技能兴鲁)
|
|
正常来说猫脸变换的图像长和宽都是相等的,如果遇到抽象的长宽不相等的图像,脚本中的N需要改一下
|
|
19、二进制数据转图片
|
|
20、 脚本提取LSB数据并分析
|
|
21、像素点RGB值转图片
题目提供了类似如下的数据:
|
|
直接写一个Python脚本爆破宽高并还原图像即可
|
|
22、图片套娃
图片的每个像素的RGB值其实都是另一张图片的字节数据
例题1-2025软件系统安全赛
附件给了下面这张图片

|
|
用以上脚本把像素的每个RGB值都转为hex,就可以在图片头几个像素发现PNG文件头

|
|
运行以上脚本循环485次后即可得到flag
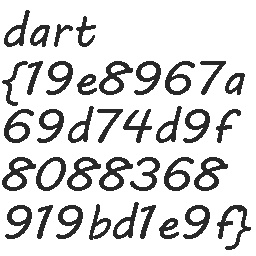
23、Java-BlindWatermark
1、直接用Byxs20写的PuzzleSolver一把梭
2、Github上的开源项目:https://github.com/ww23/BlindWatermark
|
|
24、在线网站一把梭
这种情况常常发生在某些Misc出题人水平不够,图片隐写道行不够的情况
|
|
PNG思路
1、PNG图片宽高被篡改
010打开图片改宽高即可,17~20字节是宽,21~24字节是高
当然也可以用老铜匠的脚本直接爆破图片宽高
2、LSB隐写:
没有密钥的情况
|
|
有时候LSB会隐写图片,zsteg容易看漏,所以还是要用stegsolve.jar过一遍
有密钥的情况(cloacked-pixel)
直接下载开源项目到本地,输入命令解密即可
如果懒得敲命令行,也可以用PuzzleSolver解密
|
|
|
|
3、IDAT块隐写
(1) 解压zlib获得原始数据
然后用010提取数据扔进zlib脚本解压获得原始数据
将异常的IDAT数据块斩头去尾之后使用脚本解压,在python2代码如下:
|
|
(2) 加上文件头爆破宽高得到新的图片
一般出问题的 IDAT Chunk 大小都是比正常的小的,很可能在图片末尾
如果不确定是哪一个有问题,可以尝试都提取出来,一个一个分析
可以使用 tweakpng 辅助分析,但是一般用 010 的模板提取分析就够了
我们可用 WSL 中的 pngcheck -v 0.png 检查 IDAT
如下图,最后一个和倒数第二个IDAT明显有问题,因此可以对这两部分进行尝试
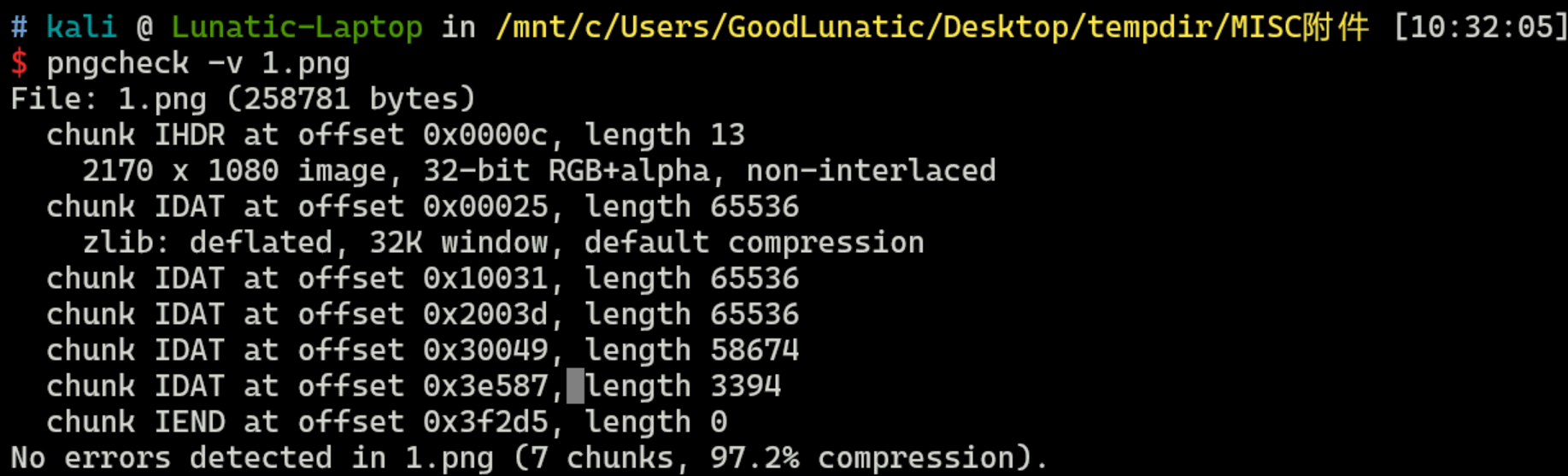
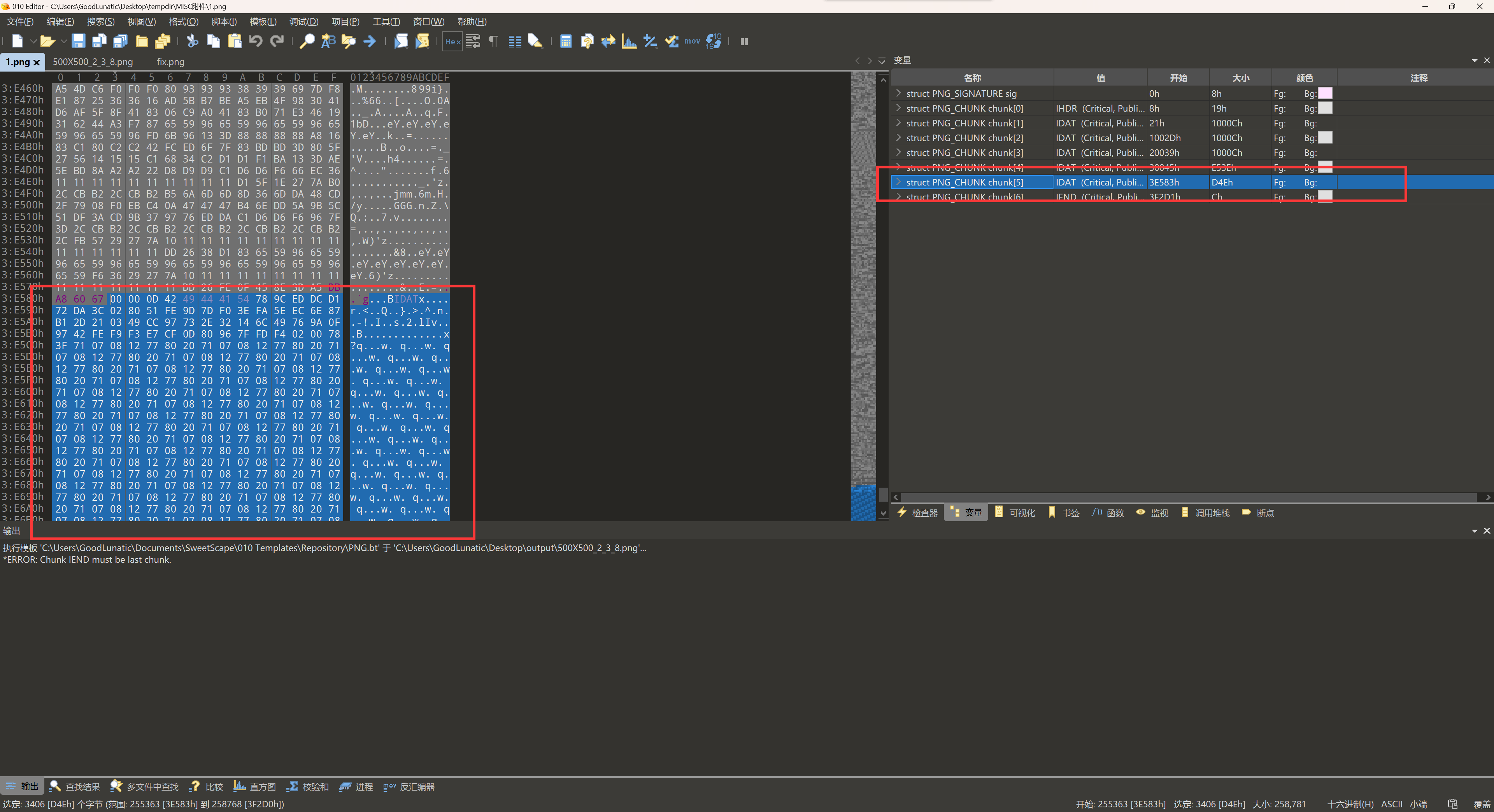
借助 010 的模板功能把IDAT块提取出来,加上文件头尾并爆破宽高即可得到另一张图片
|
|
Tips:这里有时候也可以不用补文件尾
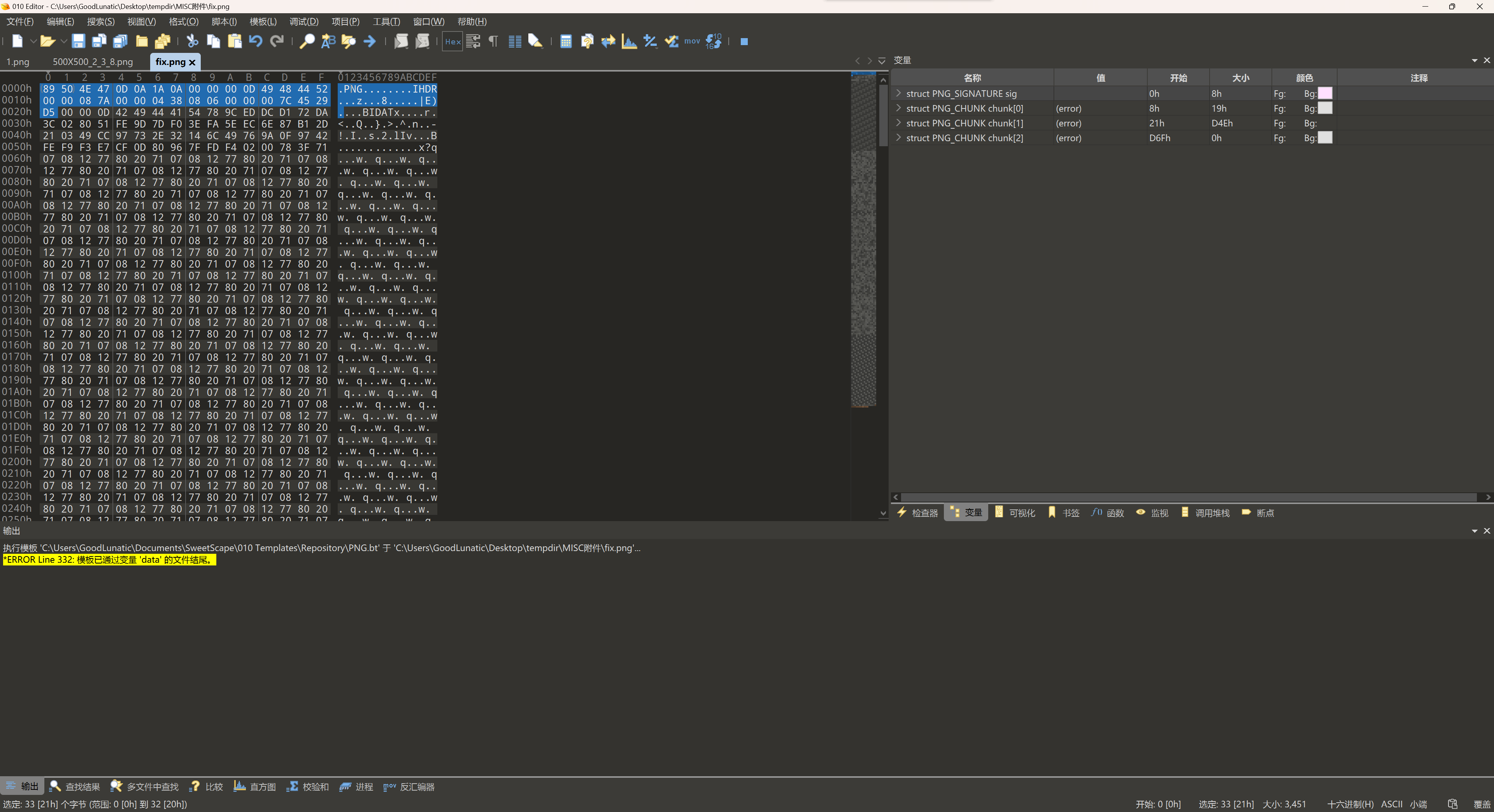
把文件头尾补完整后直接爆破一下宽高即可
例题1-2023安洵杯-dacongのsecret
例题2-DASCTF2024 暑期挑战赛-png_master
4、PNG末尾隐藏内容
010打开PNG,根据PNG模板定位到文件尾,看看后面有没有多余的数据
当然,也可以尝试直接binwalk或者foremost提取(但是如果隐藏文件的文件结构不完整可能识别不出来)
5、apngdis_gui
一张png图片还可能是apng,直接用apngdis_gui跑一下,可以分出两张相似的png
6、CVE-2023-28303 截图工具漏洞
一张图片如果有两个IEND块:AE 42 60 82
就很有可能考察的是这个漏洞
可以使用Github上大佬写好的工具一把梭,恢复完整图片前需要知道原图的分辨率
7、stegpy隐写
stegpy 开源地址 下载好后直接用WSL输入以下命令并输入密码解密即可
也可以直接用 pip 安装: pip3 install stegpy
|
|
8、npiet编程语言
白底+很多彩色的小像素点组成的图片,形如下图

方法一:直接使用在线网站:https://www.bertnase.de/npiet/npiet-execute.php 运行即可
方法二:下载源代码npiet-1.3a-win32到本地,然后使用以下命令运行
|
|
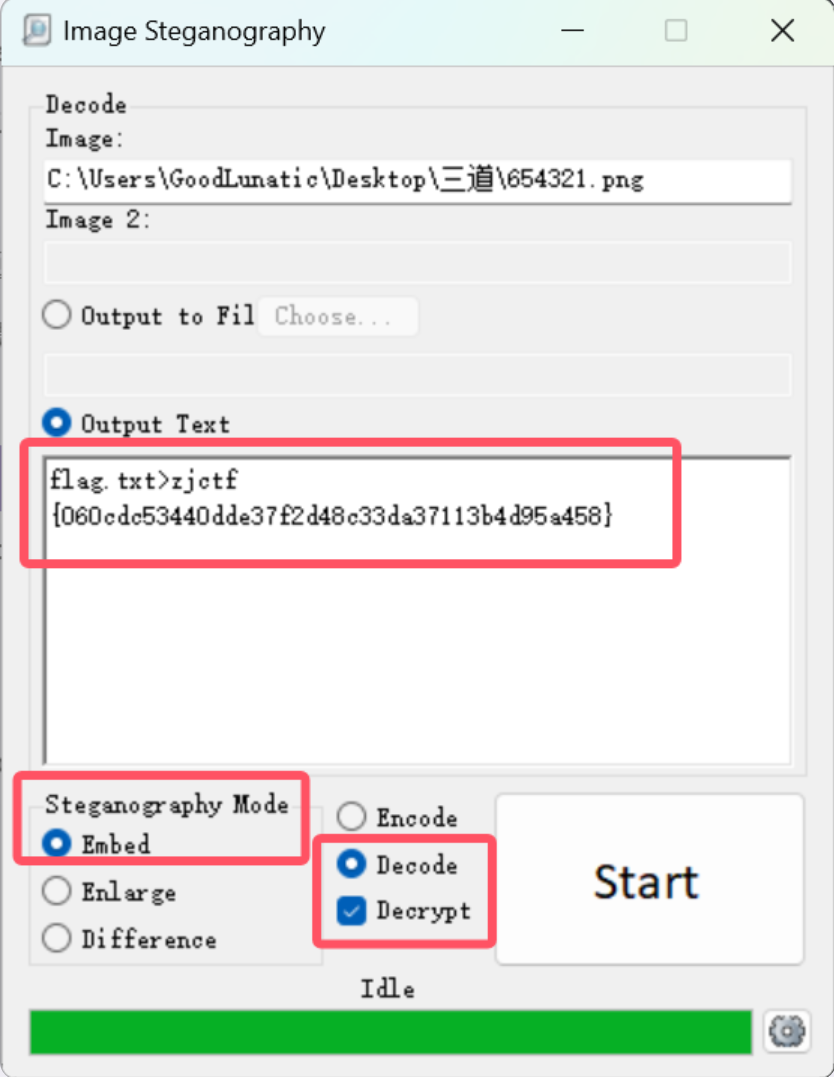
9、Image Steganography隐写
直接使用Image Steganography工具解密即可,如果需要密码,就勾选上Decrypt选项
当然也可以直接用PuzzleSolver解密
JPG思路
1、LSB隐写
用StegSolve打开查看即可
2、可以试试用stegdectet看看是什么加密:
|
|

出现三颗星不一定就代表一定是这种加密方式
2、JPHS隐写(可以无密码)
导出步骤 Select File –> seek –> demo.txt –> Save the file
3、steghide隐写(可以无密码)
|
|
在WSL或者kali里用Stegseek跑(字典在wordlist里)
|
|
|
|
4、Silenteye隐写
直接用silenteye打开输入密钥decode即可,默认密钥是silenteye,也可以填入自己的密钥
5、outguess隐写
|
|
6、F5-steganography-master
把要解密的图片拉到F5文件夹中
|
|
7、JPG宽高隐写
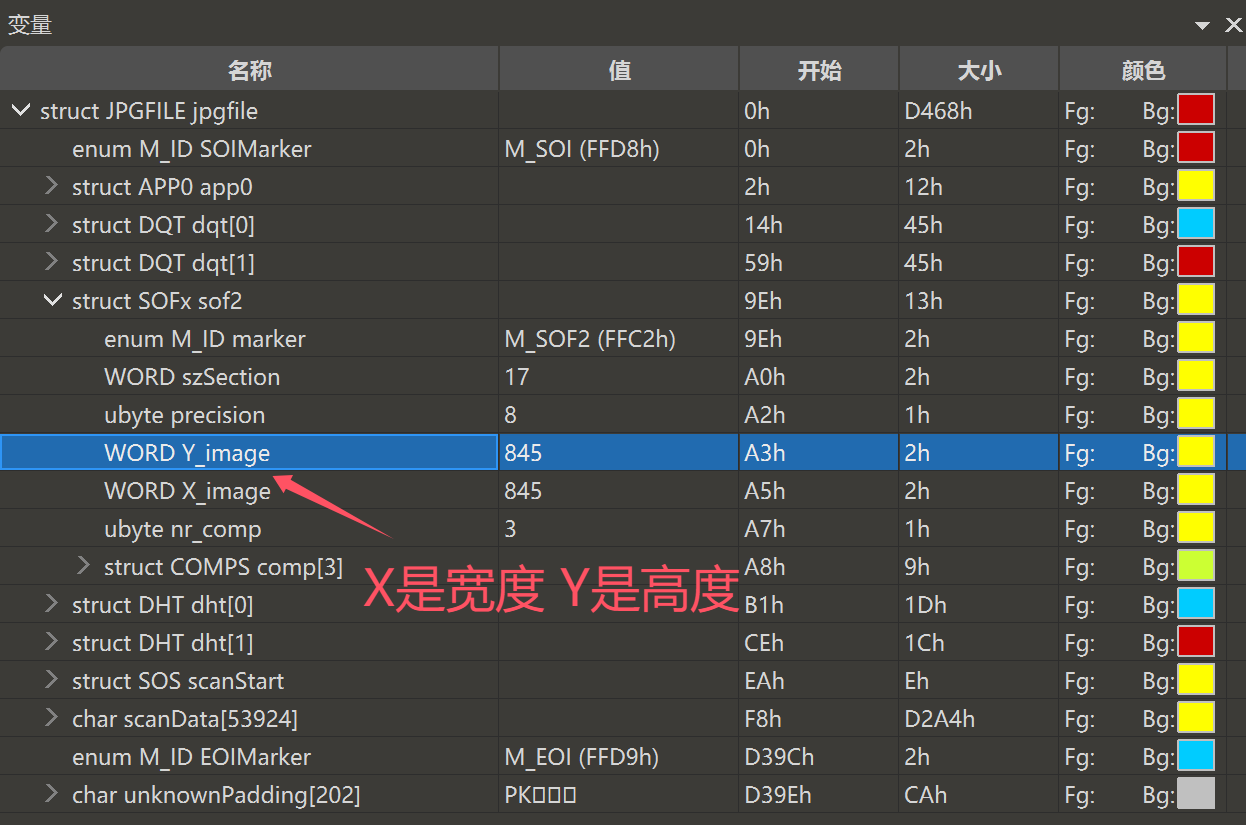
010打开JPG图片,找到 struct SOF 块数据,手动调整宽高即可
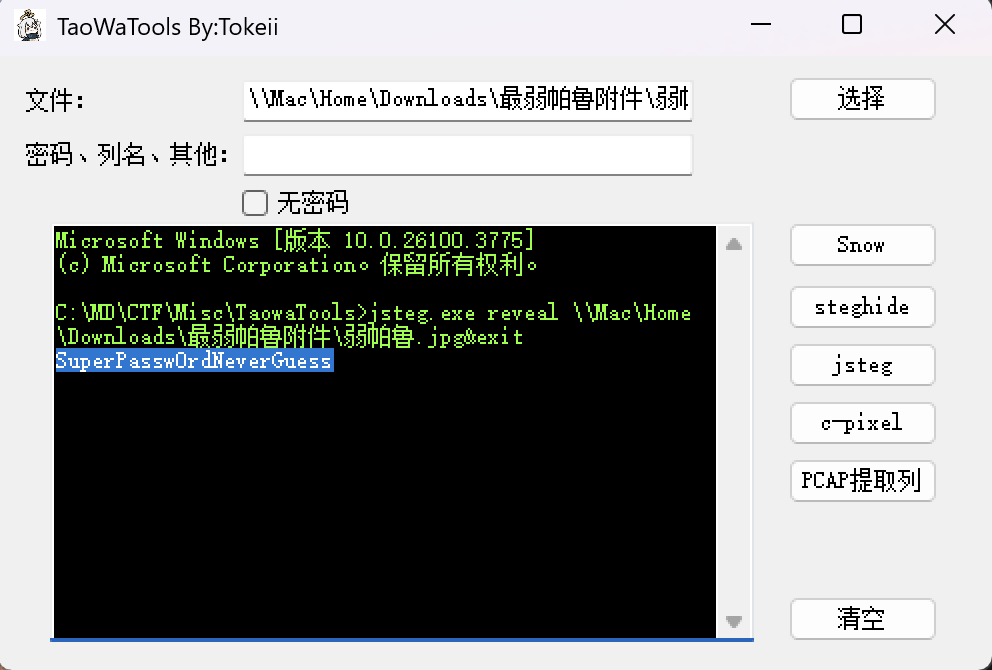
8、jsteg
JPG图片的jsteg隐写可以直接用下面这个工具一把梭
BMP思路
1、bmp宽高爆破:
删除文件头,并保存为文件名.data,然后用GIMP打开修改宽高(这个比较方便)
或者直接用bmp爆破脚本跑 python script.py -f filename.bmp
|
|
|
|
2、wbStego4open隐写(可以无密钥)
用wbStego4open输入密钥后decode即可
3、Silenteye隐写
直接用silenteye打开输入密钥decode即可,默认密钥是silenteye,可以填入自己的密钥
GIF思路
做GIF图像的相关的隐写题之前,我们首先需要对GIF图像大概的参数又一定的了解
下图我用Linux下的identify工具提取了一张GIF图像的一些参数
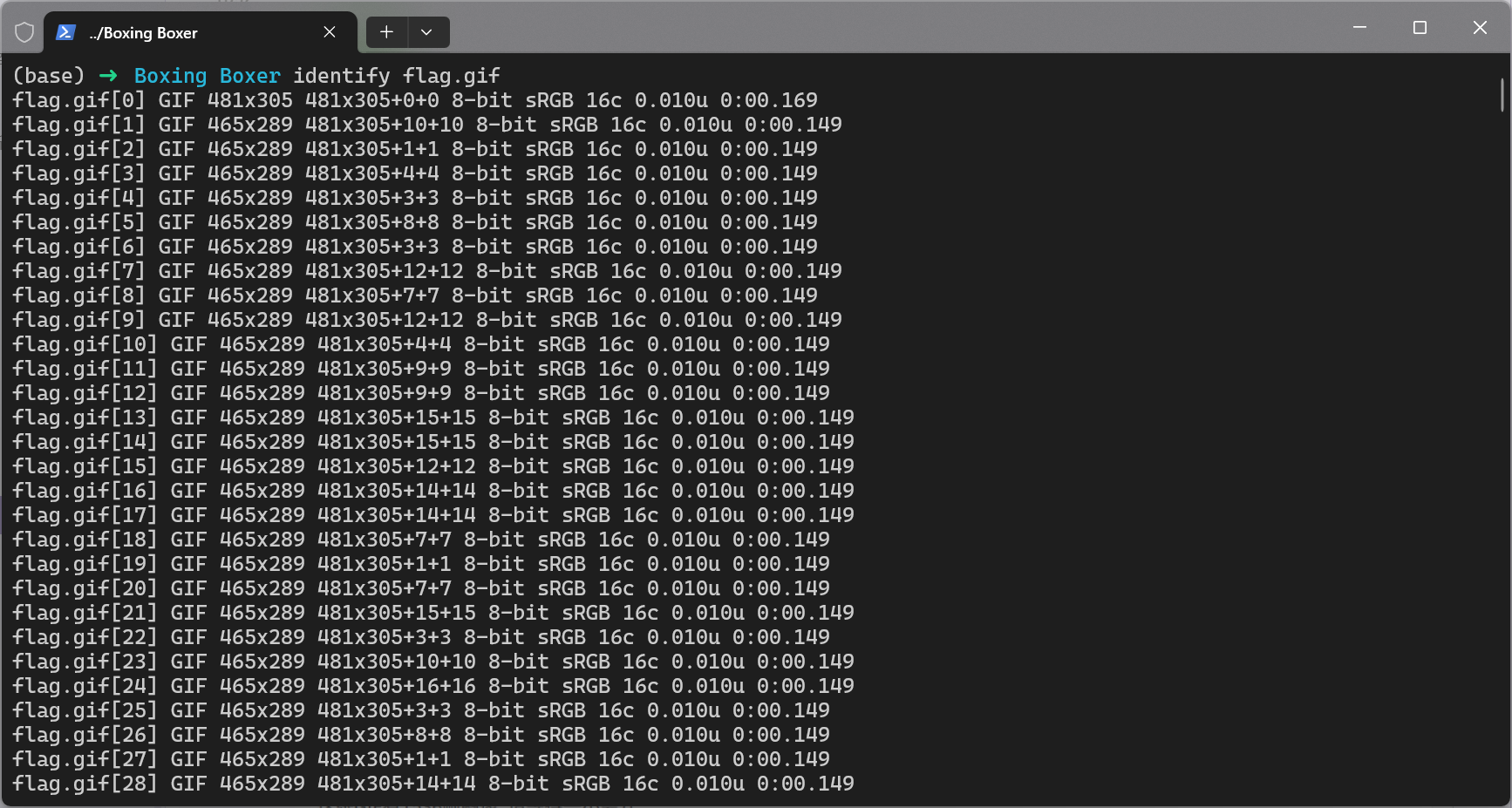
这里简要介绍一下每一行中的参数
|
|
1、GIF分帧(在线网站或者工具)
[推荐] Linux下使用convert提取
|
|
使用ffmpeg提取(如果帧间隔不同,提取出来会有问题)
|
|
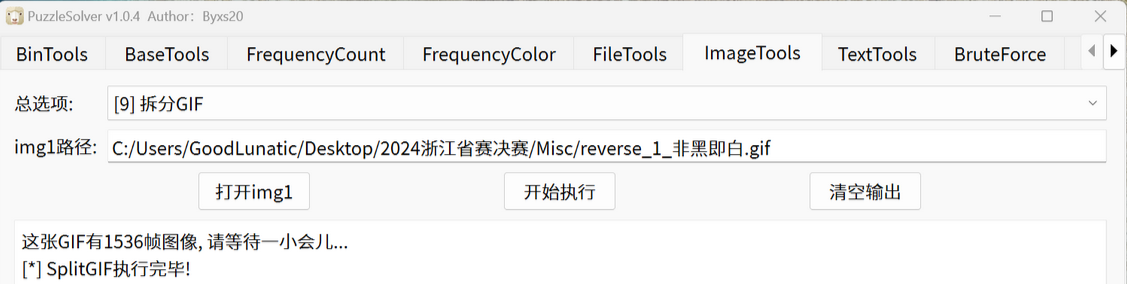
使用PuzzleSolver提取,是按照帧来进行提取
2、帧间隔隐写
[推荐] 方法一:直接使用PuzzleSolver提取帧间隔
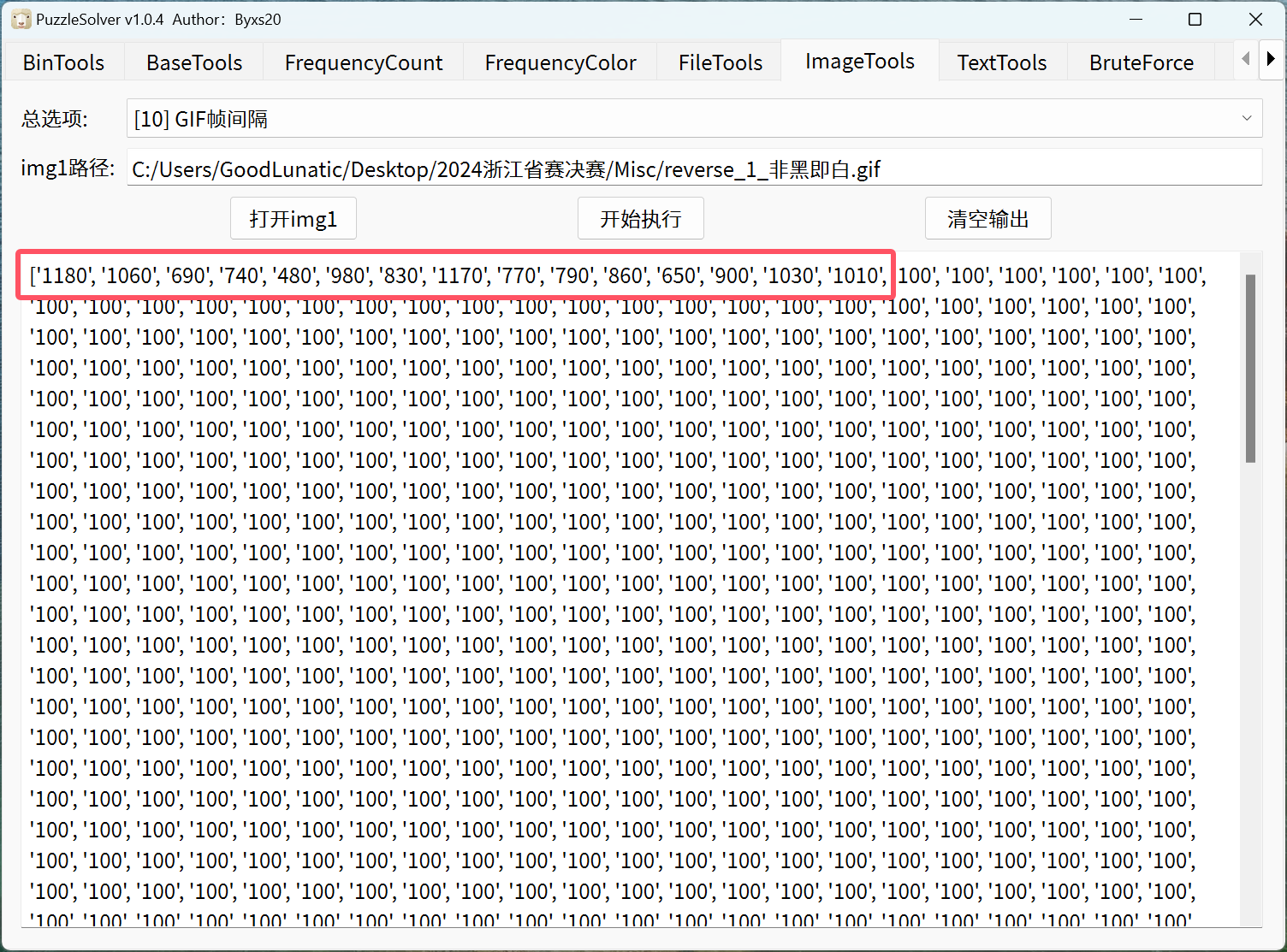
方法二:使用identify提取
|
|
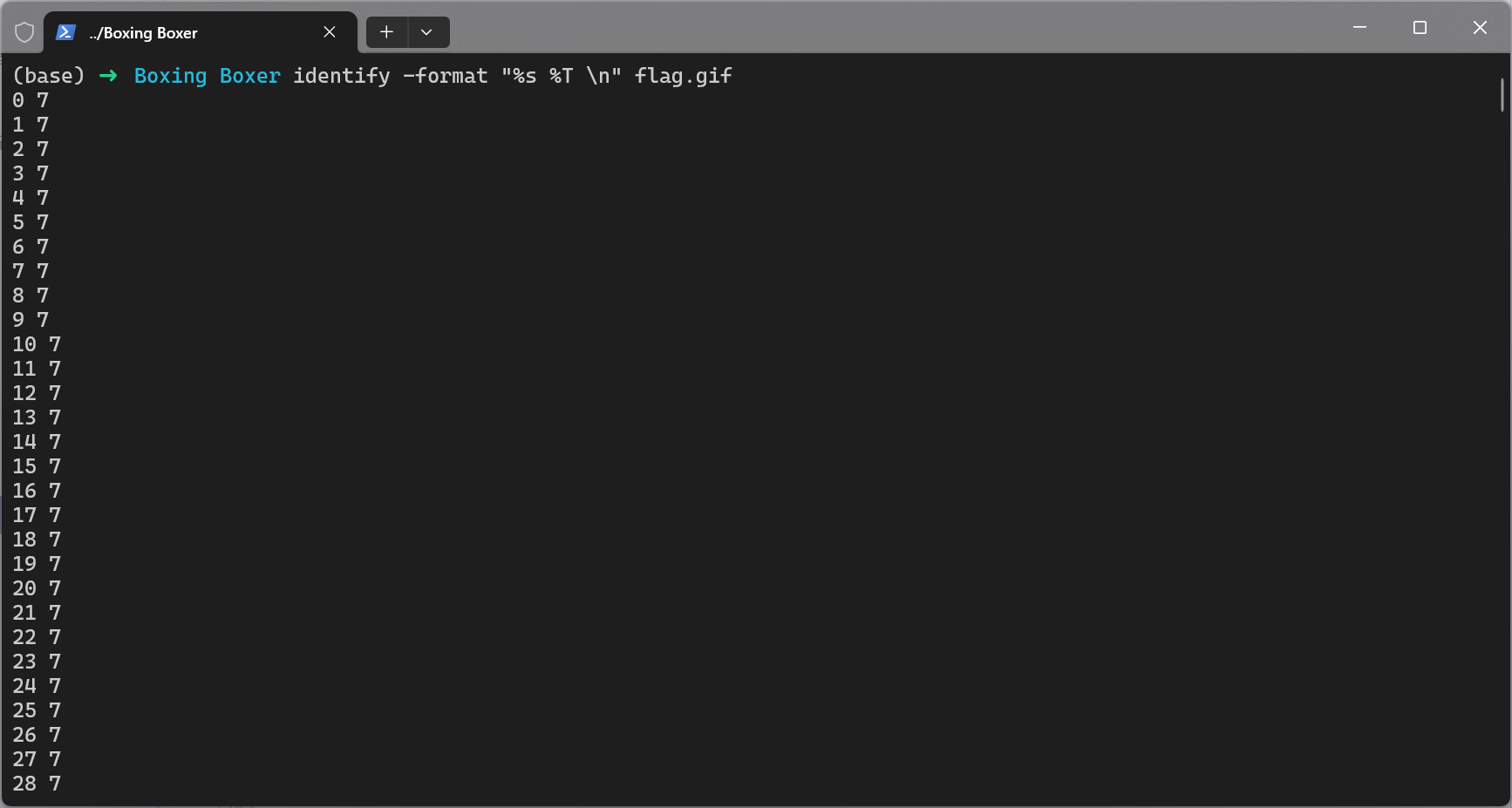
例题1-2024羊城杯初赛-checkin
例题2-2024浙江省赛决赛-非黑即白
GIF图像每帧的XY偏移量隐写
使用identify提取出偏移量然后再分析
|
|
例题1-Boxing Boxer
|
|
GIF图像每帧的实际尺寸隐写
例题1-Boxing Boxer
Webp思路
webp文件用电脑自带的图片看可能会有点问题,建议用浏览器打开这种文件
webp可能是动图,可以用下面这个脚本分离webp中的每帧图片
|
|
BPG图像文件
使用bpg-0.9.8-win64转换为PNG图片即可
|
|
RAW、ARW文件思路
1、RAW的LSB隐写
ARW文件是 Sony 相机的原始数据格式
可以使用 rawpy 模块读取图片的像素数据,查看是否存在LSB隐写(例题1-2024-L3HCTF-RAWatermark)
示例脚本如下:
|
|
2、直接改后缀为.data,然后拖入Gimp调整即可
二维码思路
1、bmp转二维码
2、16进制转pyc
3、字符串制作二维码
|
|
4、四个TTL值转换一个字节的二进制数
5、Aztec code、DataMatrix、GridMatrix、汉信码、PDF417code等
我们平常见的最多的二维码就是QRcode,但是实际上还有很多不同类型的二维码,这里就简单举几个例子:

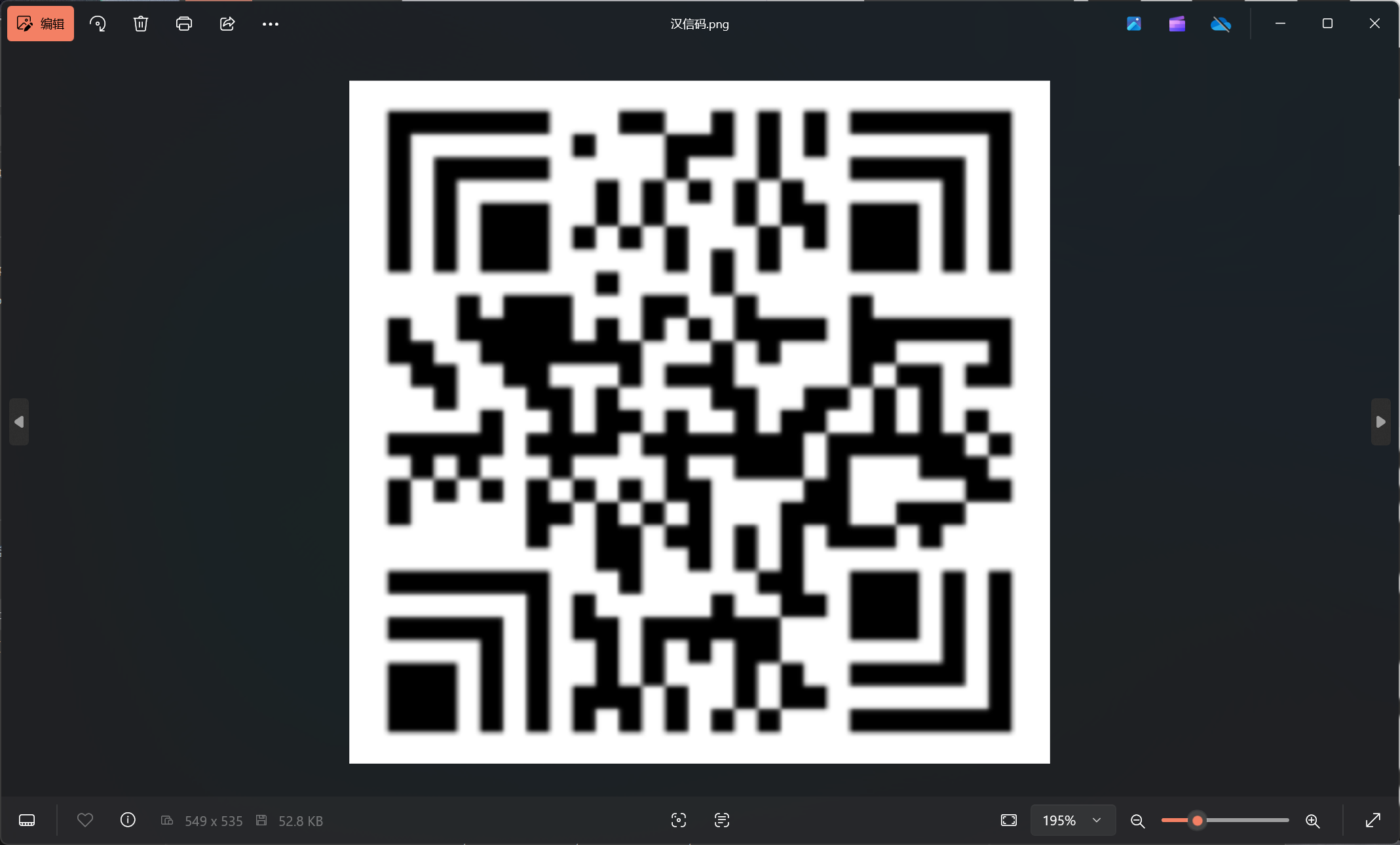
汉信码这里要注意,左下角的那块定位块的方向和另外几块是不一样的
有时候题目会把这块定位块反过来
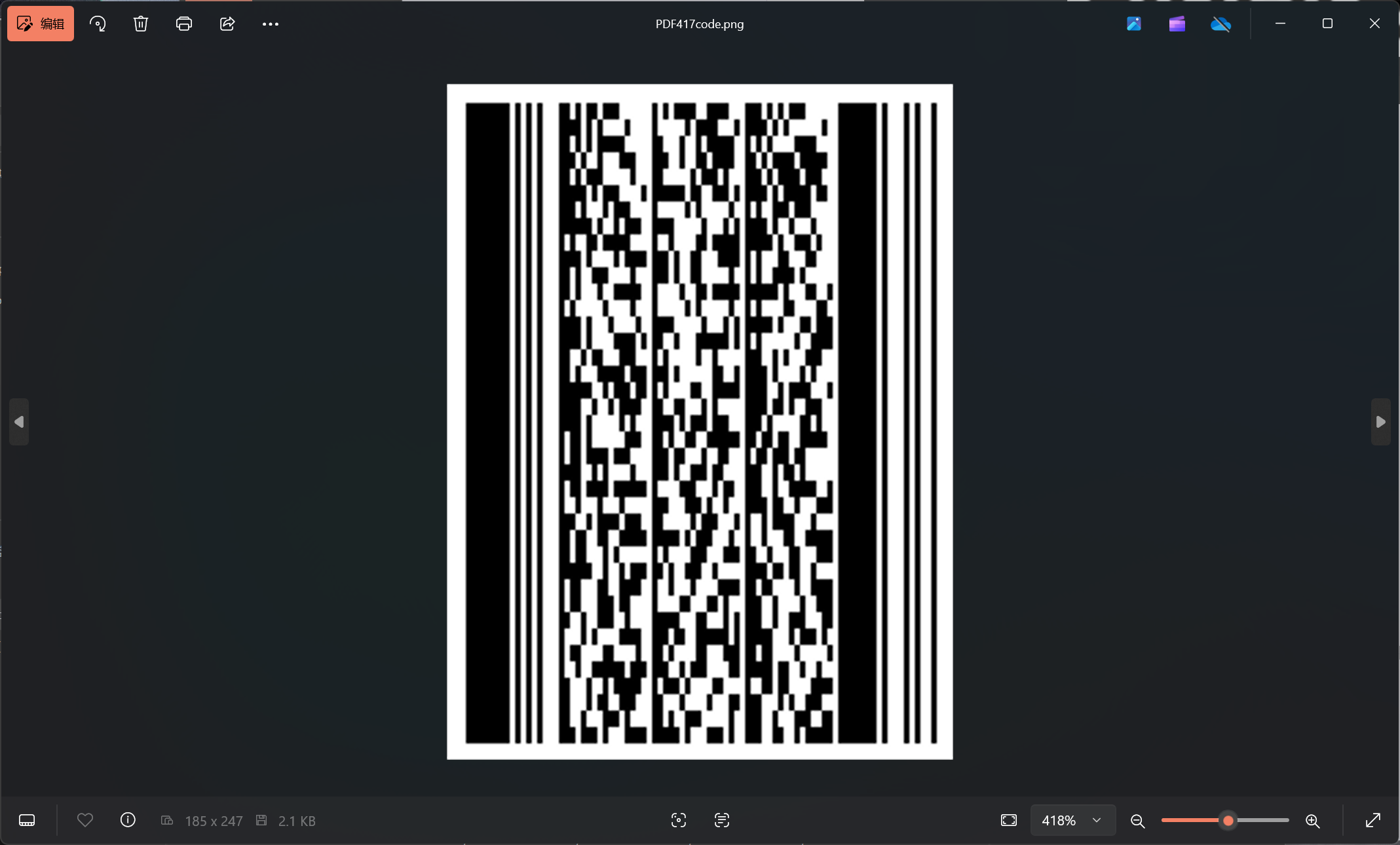
这里要注意的是,出题人可能会把图片反相导致无法直接扫描
因此我们可以先将二维码拉入StegSolve或者PS进行反相处理,再扫描
QRcode 二维码的一些考点
详见作者博客里的QRcode二维码标准及常见考点详解这篇文章
Misc——PDF题思路:
1、直接binwalk或者foremost提取出隐藏文件
2、可能是wbStego4open隐写,用wbStego4open输入密钥直接decode
3、PDF中可能携带了什么文件,可以在firefox或者别的PDF软件中打开并提取
4、PDF中可能有透明的文字,直接全选复制然后粘贴到记事本中查看即可
5、使用DeEgger Embedder工具extract files
6、使用PS打开,里面可能有多个图层(例题1-2024古剑山-jpg)
7、若PDF加密,可以尝试使用pdfcrack爆破一下密码(Ubuntu下可以直接 apt install)
|
|
Misc——MS-Office题思路
有时候会遇到不知道是MS-Office中具体什么类型的情况,如下图
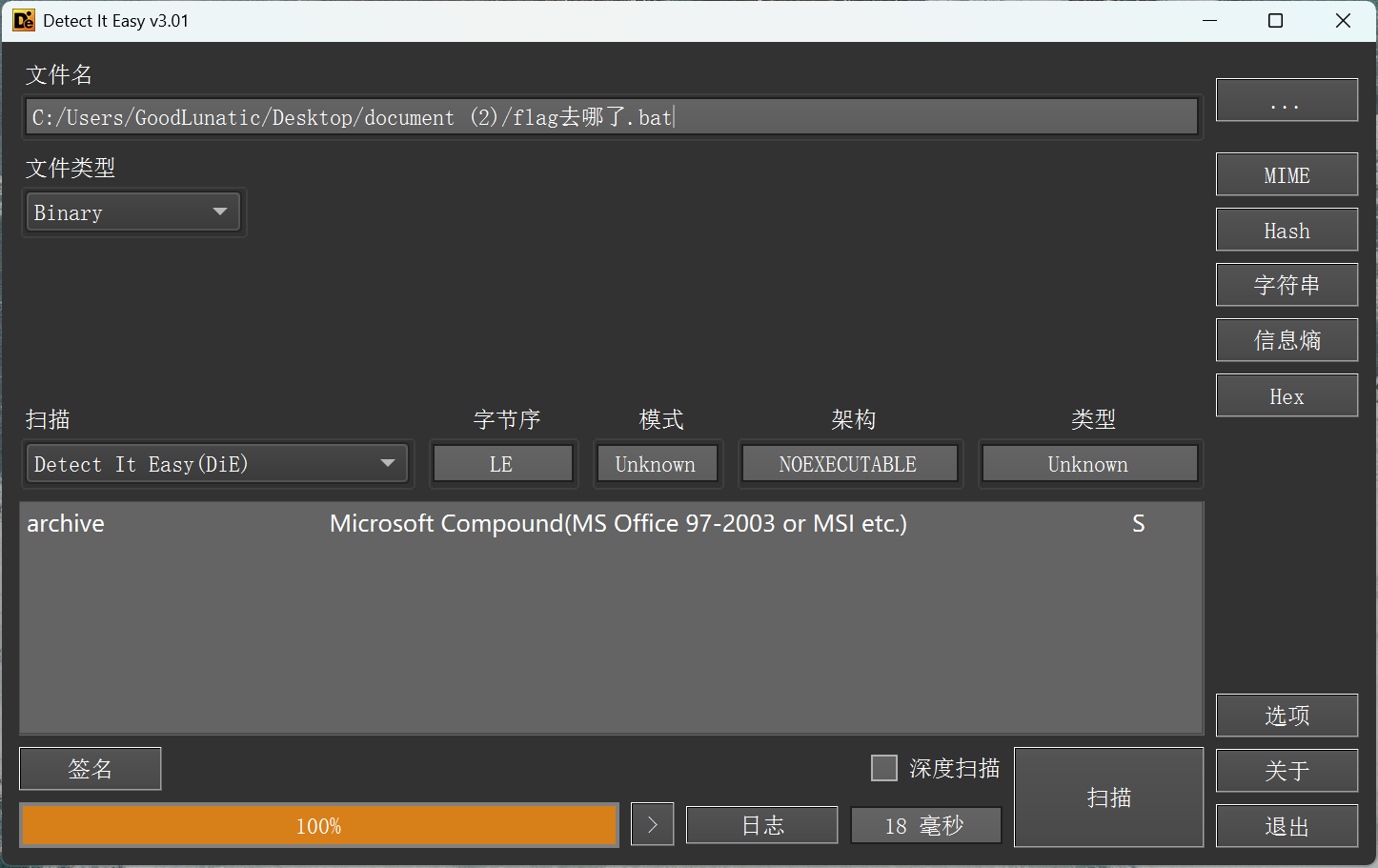
并且这个文件还是加密的,我们可以尝试把后缀改成docx或者pptx,然后用PasswareKit先爆破出密码
再用msoffcrypto-tool输入密码解密一下:https://github.com/nolze/msoffcrypto-tool
|
|
解密完成后010打开就能判断出准确的文件类型了
新版本的文件类型(docx/xlsx/pptx)
Excel文件:.xls .xlsx
1、拉入010或者记事本,查找flag
2、取消隐藏先前隐藏的行和列
3、条件格式里设置突出显示某些单元格(黑白后可能会有图案)
4、要先将数据按照行列排序后再进行处理
Word文件:.doc .docx
1、直接foremost出隐藏文件
2、与宏有关系的各种攻击与隐写
|
|
3、利用行距来隐写(例:ISCC2023-汤姆历险记)
|
|
4、docx中有emf和oleobject
|
|
MS-Office97-2003
OLEHeader修复
| 字段名称 | 偏移量 | 字段描述 |
|---|---|---|
| 文件签名 | 0x0-0-x7 | 固定值:D0CF11E0A1B11AE100 |
| 对象标识符 | 0x8-0x17 | 通常全为0 |
| 次要版本号 | 0x18-0x19 | 通常为固定值:3E00 |
| DLL版本号 | 0x1A-0x1B | 通常为固定值:0300 |
| 字节序 | 0x1C-0x1D | 通常为小段序:FEFF |
| 每个扇区的大小 | 0x1E-0x1F | 通常为固定值0900(即2的9次方=512字节) |
| 迷你扇区大小 | 0x20-0x21 | 通常为固定值0600(即2的6次方=64字节) |
| 保留字段 | 0x22-0x23 | 通常为0000 |
| 保留字段 | 0x24-0x27 | 通常为00000000 |
| 目录扇区的数量 | 0x28-0x2B | 通常为00000000 |
| FAT表扇区的数量 | 0x2C-0x2F | 存储文件分配表(FAT)占用的扇区数量(01000000) |
| 根目录扇区索引 | 0x30-0x33 | 根目录所在扇区的索引号,找RootEntry所载的扇区,计算时需要把第一个扇区排除0x6800/0x200-1=0x33 |
|
|
| 事务签名 | 0x34-0x37 | 通常为固定值:00000000 |
|---|---|---|
| 迷你流最大大小 | 0x38-0x3B | 通常为固定值:00010000 |
| 第一个迷你 FAT 扇区索引 | 0x3C-0x3F | 短扇区分配表的扇区位置,一般紧接着RootEntry,得看RootEntry占用多少扇区,这里是占用两个扇区,因此这里的值应该填0x35 |
| 迷你 FAT 扇区数量 | 0x40-0x43 | 短扇区分配表占用的扇区数,这里长度为0x200,因此只占用了一个扇区 |
|
|
| 第一个 DIFAT 扩展扇区索引 | 0x44-0x47 | 指向第一个 DIFAT(双 FAT)扇区的起始位置(FAT 索引) |
|---|---|---|
| DIFAT 扇区数量 | 0x48-0x4B | 存储 DIFAT(双 FAT)表占用的扇区数量 |
0x44-0x4B:主扇区分配表的扩展部分的索引以及其数量,因为文件比较小没有用到扩展部分,第一个应该是-2即0xFEFFFFFF,然后数量为0
| DIFAT 表 | 0x4C-0x1FF | 主扇区分配表,因为文件不是很大,基本只有前面几个字节是有意义的,后面都是0xFF,取值和RootEntry的扇区号有关,一般就是root扇区倒着写,因为root为0x33,这里我们填一个0x32000000 |
|---|
最后修复完整后的OLEHeader如下
|
|
Misc——txt题思路:
1、 有可能是ntfs,直接用NtfsStreamsEditor2扫描所在文件夹,然后导出可疑文件【如果是压缩包,一定要用winrar解压】
2、可能是wbStego4open隐写,用wbStego4open直接decode(可能有密钥)
3、如果是那种文件夹套文件夹的题目,可以直接把路径粘贴到everything中,让everything一把梭
4、无字天书(whitespace)&snow隐写
一个文件打开都是空白字符
可以使用在线网站解密:https://vii5ard.github.io/whitespace/ 复制进去直接run即可
snow隐写,到snowdos32工具目录下运行 SNOW.EXE -C -p password flag.txt 命令即可
5、垃圾邮件隐写(spammimic)
例题1-2024强网拟态初赛-PvZ
直接使用以下在线网站解密即可:
6、Cloakify隐写
例题1-群友发的题
附件下载链接:https://pan.baidu.com/s/1EMAMOeot_aKXIs5pckTQfQ?pwd=93np 提取码:93np
解密需要用到Cloakify这个项目
拿到密文和字典后,直接Python运行解密即可
|
|
Tips:如果碰到解密失败的情况,可以试试看在windows下重新复制文本,并在末尾加一个换行符
Misc——html题思路:
1、可能是wbStego4open隐写,用wbStego4open直接输入密钥decode
Misc——压缩包思路:
Tips:压缩包的密码可以是可打印字符(中英文数字+特殊符号),也可以是不可打印字符
没有思路时可以直接纯数字/字母暴力爆破一下
zip文件结构
三部分:压缩文件源数据区 + 压缩源文件目录区 + 压缩源文件目录结束标志
文件源数据区
| 字段名称 | 字段描述 |
|---|---|
| frSignature | ZIP文件头,固定值504B0304 |
| frVersion | 解压所需的 pkware 版本 |
| frFLags | 全局方式位标记,最低位的1bit是1表示加密,是0表示未加密 |
| frCompression | 压缩方法(具体值如Store、Deflate等) |
| frFileTime | 被压缩文件的最后修改时间 |
| frFileDate | 被压缩文件的最后修改日期 |
| frCrc | 文件压缩前 CRC-32 的值 |
| frCompressedSize | 被压缩文件压缩后的大小 |
| frUncompressedSize | 被压缩文件压缩前的大小 |
| frFileNameLength | 被压缩文件的文件名长度 |
| frExtraFieldLength | 扩展字段长度(具体值如0等) |
| frFileName | 被压缩文件的文件名 |
| frData | 被压缩文件压缩后的数据 |
文件目录区
| 字段名称 | 字段描述 |
|---|---|
| deSignature | 签名,通常是504B0102 |
| deVersionMadeBy | 制作于哪个 pkware 版本 |
| deVersionToExtract | 解析该目录需要的版本号,与数据区frVersion的值一致 |
| deFLags | 一般标志位,与数据区frFlags的值一致 |
| deCompression | 压缩方法,与数据区frCompression的值一致 |
| deFileTime | 被压缩文件的最后修改时间,与数据区中对应字段的值一致 |
| deFileDate | 被压缩文件的最后修改日期,与数据区中对应字段的值一致 |
| deCrc | 文件压缩前 CRC-32 的值 |
| deCompressedSize | 被压缩文件压缩后的大小 |
| deUncompressedSize | 被压缩文件压缩前的大小 |
| deFileNameLength | 被压缩文件的文件名长度 |
| deExtraFieldLength | 扩展字段长度(与数据区的对应值可能不一致) |
| deFileCommentLength | 文件备注长度 |
| deDiskNumberStart | 文件起始位置所在的磁盘编号(早期磁盘很小的情况下,压缩包可能跨磁盘) |
| deInternalAttributes | 内部文件属性 |
| deExternalAttributes | 外部文件属性 |
| uint deHeaderOffset | 本目录指向的entry相对于第一个entry的起始位置,单位byte,这也就限制了ZIP文件最大也就是4G了,再大就无法定位了 |
| deFileName | 被压缩文件的文件名 |
| deExtraField | 扩展字段 |
文件目录结束
| 字段名称 | 字段描述 |
|---|---|
| elSignature | 签名,通常是504B0506 |
| elDiskNumber | 当前磁盘编号 |
| elStartDiskNumber | 中央目录起始磁盘编号 |
| elEntriesOnDisk | 当前磁盘上的中央目录记录数 |
| elEntriesInDirectory | 中央目录总条目数 |
| elDirectorySize | 中央目录的总大小 |
| elDirectoryOffset | 中央目录相对于第一个entry的起始位置 |
| elCommentLength | 注释长度 |
| char elComment | 压缩包注释 |
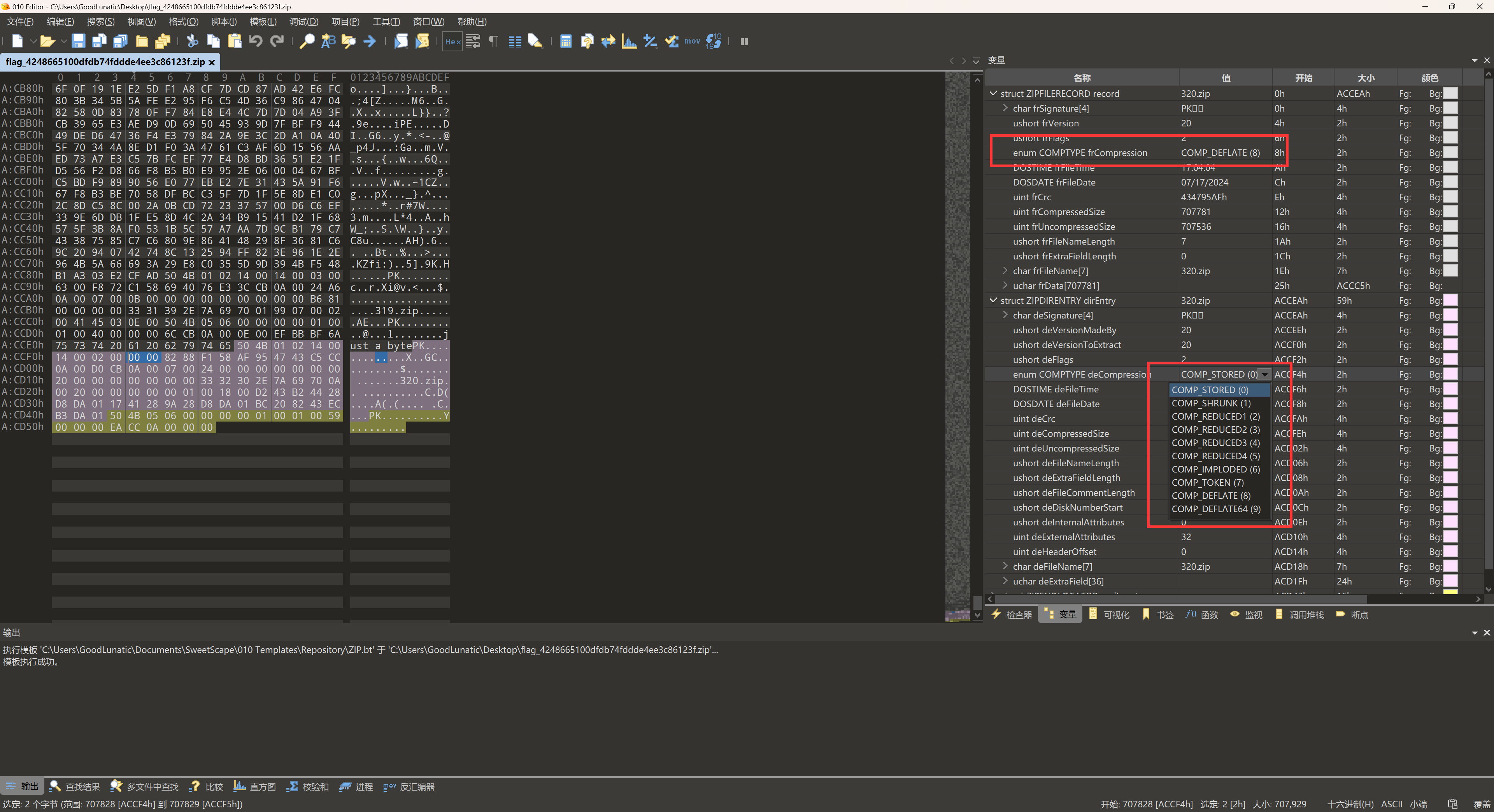
常见报错及对应解决方法(借助010的模板功能)
- 该文件已损坏-源数据区和目录区的文件名长度被修改了
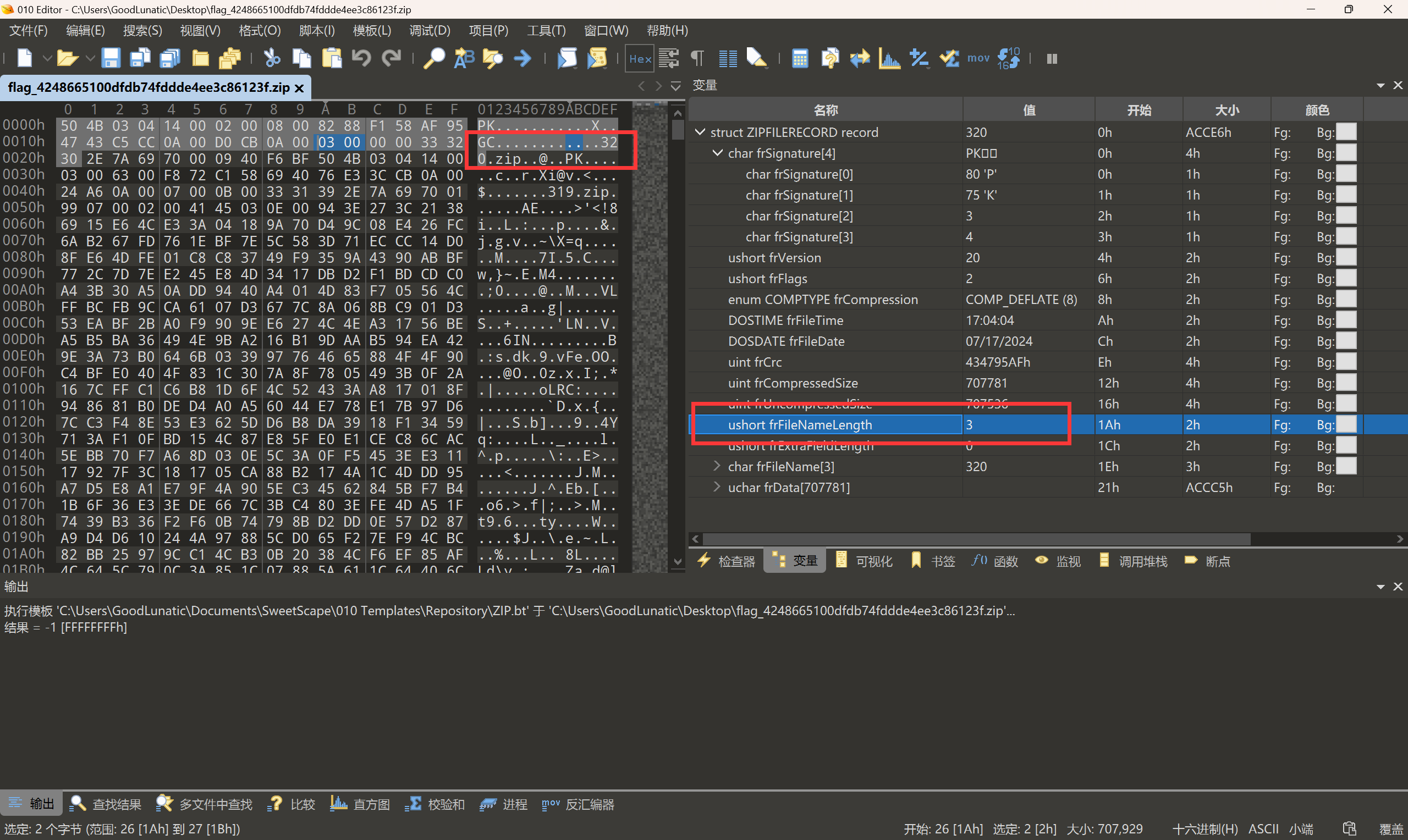
- CRC校验错误-源数据区或目录区的压缩方法被修改了
rar文件结构
| HEX 数据 | 描述 | 010Editor 模板数据 |
|---|---|---|
| 52 61 72 21 1A 07 00 | rar 文件头标记,文本为 Rar! |
Main block
| HEX 数据 | 描述 | 010Editor 模板数据 |
|---|---|---|
| 33 92 B5 E5 | 全部块的 CRC32 值 | uint32 HEAD_CRC |
| 0A | 块大小 | struct uleb128 HeadSize |
| 01 | 块类型 | struct uleb128 HeadType |
| 05 | 阻止标志 | struct uleb128 HeadFlag |
File Header
| HEX 数据 | 描述 | 010Editor 模板数据 |
|---|---|---|
| 43 06 35 17 | 单独块的 CRC32 值 | uint32 HEAD_CRC |
| 55 | 块大小 | struct uleb128 HeadSize |
| 02 | 块类型 | struct uleb128 HeadType |
| 03 | 阻止标志 | struct uleb128 HeadFlag |
Terminator
| HEX 数据 | 描述 | 010Editor 模板数据 |
|---|---|---|
| 1D 77 56 51 | 固定的 CRC32 值 | uint32 HEAD_CRC |
| 03 | 块大小 | struct uleb128 HeadSize |
| 05 | 块类型 | struct uleb128 HeadType |
| 04 00 | 阻止标志 | struct uleb128 HeadFlag |
1、压缩包伪加密
感觉网上很多讲压缩包伪加密的博客都是有问题的,因此打算这里详细总结一下
首先,frFlags 只是用于告诉压缩软件这个压缩包是否被加密,没有任何一个标志可以直接表示压缩包是否是伪加密。我们只能通过frFlags这个标志位判断出压缩包当前是否是加密状态,如果是加密状态,我们再进一步尝试判断是否是伪加密。
zip文件:
Bandizip判断压缩包是否加密的方式:压缩源文件数据区的 frFlags
7zip判断压缩包是否加密的方式:压缩源文件目录区的 frFlags
因此,出题的时候需要把这两个位置都改了,要不然换个软件可能就直接非预期了
去除伪加密的方法:直接用010editor打开,将压缩源文件数据区第8字节和压缩源文件目录区第10字节改为00即可
rar文件:
rar文件的伪加密是非常明显的,打开就会显示报错
010editor打开,第24个字节尾数为4表示加密,0表示无加密,将尾数改为0即可去除伪加密
2、CRC爆破
适用于压缩包中文件比较小,比如只有几字节的时候
可以直接用网上的脚本爆破,但是要注意有些脚本只能提取zip压缩包的CRC32:
https://github.com/AabyssZG/CRC32-Tools
https://github.com/theonlypwner/crc32
|
|
发现网上大部分的脚本只能爆破可打印字符的结果,因此这里我自己写了一个包含不可打印字符的脚本
|
|
例题1-BugKu MISC 就五层你能解开吗?
参考文章:https://blog.csdn.net/mochu7777777/article/details/110206427
3、暴力破解压缩包密码
可以使用的工具:Advanced Archive Password Recovery(ARCHPR)、Passware Kit Forensic、Hashcat
爆破效率:Advanced Archive Password Recovery(ARCHPR) < Passware Kit Forensic< Hashcat
爆破的类型主要可以分为限制字符集及长度的爆破、掩码爆破、字典爆破这三种
Tips:
掩码爆破这里,
ARCHPR是用?表示占位符、而Passware Kit Forensic是用例如?d等正则表达式表示占位符字典爆破推荐使用
rockyou.txt这个字典,kali系统中自带了,在/usr/share/wordlists目录下
Hashcat爆破压缩包密码的步骤
- 生成待爆破的Hash值
|
|
2.找到对应的Hash类型:https://hashcat.net/wiki/doku.php?id=example_hashes
3.使用Hashcat进行爆破
|
|
参数含义:
-a 后跟使用的攻击类型 3表示掩码攻击 0表示字典攻击
-m 后跟待爆破的Hash类型,具体类型参考上面的链接
–increment –increment-min 1 –increment-max 6 表示限制长度1-6位
-1 表示自定义字符集 ?d代表数字 ?l代表小写字母 ?u代表大写字母 ?s代表特殊符号
–force 代表忽略破解过程中的警告信息
–show 输出已爆破出的Hash值及对应明文,爆破成功的Hash会保存在hashcat.potfile文件中
4、压缩包套娃解套
压缩包套娃可能会包含多种类型的压缩混合套娃,但是流程都差不多,这里就贴一下我写的脚本吧
|
|
|
|
Tips:ZIP压缩包套娃建议用
pyzipper模块写脚本解套,不要用zipfile了,这个模块有点过时了
5、分卷压缩包合并
使用以下命令合并或者直接Bandizip打开
|
|
6、压缩包炸弹
很小的压缩文件,解压出来会占据巨大的空间,甚至撑爆磁盘
处理方法:010中直接编辑压缩包文件,看看是否藏有另一个压缩包
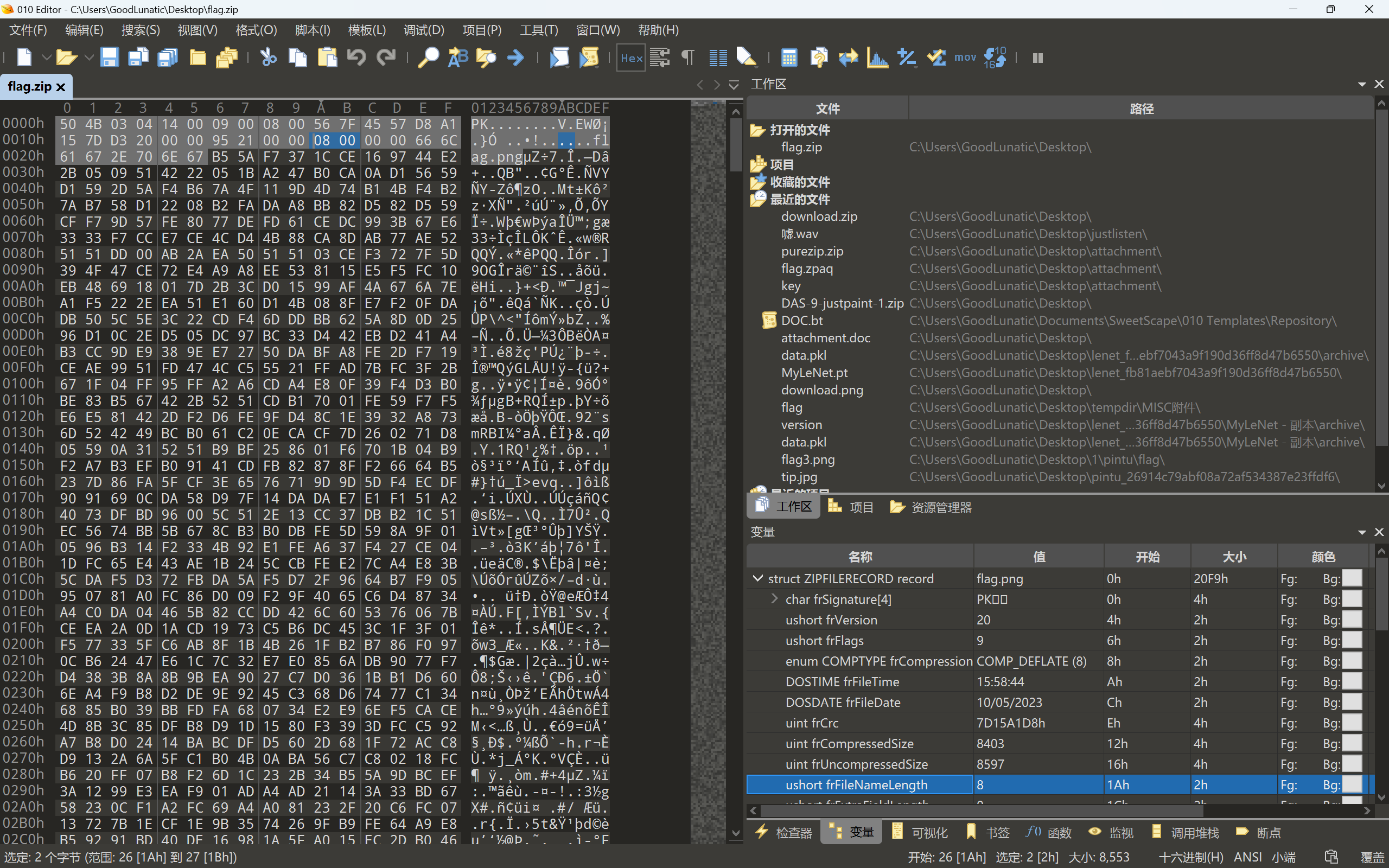
7、根据010中的模板修改了某些参数
有些题目可能会修改源数据中压缩包文件中被压缩文件的文件名的长度
源数据中被压缩文件名字的长度对不上也会导致解压后文件无法打开
所以…010的模板功能真的非常非常的好用!
8、压缩包密码是不可见字符
字节数很短的情况
直接写个Python脚本爆破即可
|
|
字节数较长的情况
需要先把密码base64编码一下,然后再base64解码成byte类型作为密码
|
|
9、明文攻击
已知所有的明文或三段密钥
方法一、直接使用Advanced Archive Password Recovery破解
有和压缩包中的一样(CRC值一样)的文件时,压缩然后用上面那个软件进行明文攻击,这个攻击的过程可能需要几分钟
有了完整的三段密钥也可以使用这个工具破解密码
方法二、使用 bkcrack破解(推荐)
把相同文件按照对应的压缩方法,压缩成压缩包,然后使用bkcrack破解即可
例题1-2023古剑山-幸运饼干
|
|
例题2-2023铁三决赛-baby_jpg
先从部分伪加密的压缩包中分离出
serect.pdf,然后从PDF中 foremost 出了加密压缩包中的sha512.txt将
sha512.txt压缩成sha512.zip,然后使用下面的命令进行明文攻击即可:
|
|
参数含义:
-C 后跟待破解的压缩包,
-c 后跟压缩包中我们要攻击的明文文件
-P 后跟我们压缩好的压缩包
-p 后跟我们已得的明文文件
-U 参数用于修改压缩包密码并导出
已知部分明文
利用bkcrack进行攻击
参考资料:
https://www.freebuf.com/articles/network/255145.html
https://byxs20.github.io/posts/30731.html#%E6%80%BB%E7%BB%93
该利用方法的具体要求如下:
至少已知明文的12个字节及偏移,其中至少8字节需要连续
明文对应的加密算法需要是:
ZipCrypto(Tips:压缩算法不一定要是Store,有时候Deflate也可以)需要知道出题人用的压缩工具
如何判断压缩工具(参考自Byxs20的博客)
| 压缩工具 | VersionMadeBy(压缩所用版本) |
|---|---|
| Bandzip 7.06 | 20 |
| Windows自带 | 20 |
| WinRAR 4.20 | 31 |
| WinRAR 5.70 | 31 |
| 7-Zip | 63 |
bkcrack常用参数
|
|
1)利用明文文本破解
|
|
|
|
2)利用PNG图片文件头破解
|
|
3)利用压缩包格式破解
将一个名为flag.txt的文件打包成ZIP压缩包后,发现文件名称会出现在压缩包文件头中,且偏移固定为30
且默认情况下,flag.zip也会作为该压缩包的名称
已知的明文片段有:
“flag.txt” 8个字节,偏移30
ZIP本身文件头:50 4B 03 04 ,4字节
满足12字节的要求
|
|
Tips:如果这里用
XXXXX.txt作为明文无法破解成功,可以试试直接去掉后缀.txt
例题1-NKCTF2023——五年Misc,三年模拟
|
|
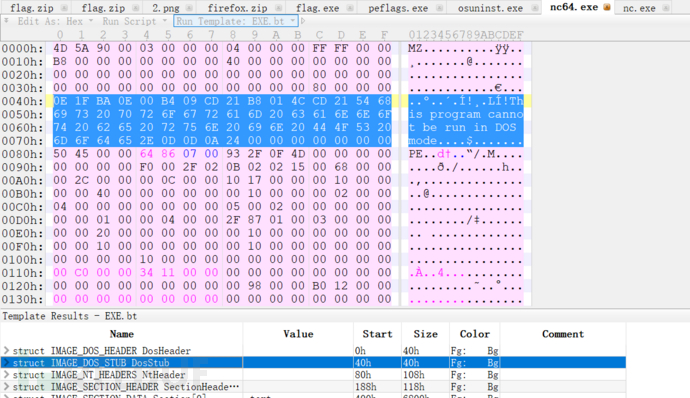
4)利用EXE文件格式破解
EXE文件默认加密情况下,不太会以store方式被加密,但它文件格式中的的明文及其明显,长度足够。
如果加密ZIP压缩包出现以store算法存储的EXE格式文件,很容易进行破解。
大部分exe中都有这相同一段,且偏移固定为64:
|
|
5)利用pcapng格式破解
|
|
6)利用XML文件格式破解
|
|
|
|
7)利用SVG文件格式破解
|
|
8)利用VMDK文件格式破解
|
|
有时候直接给你部分明文的情况(2023 DASCTFxCBCTF)
直接在bkcrack中使用以下命令即可,key是题目给的压缩包中被压缩文件的部分明文
|
|
得到密钥后使用bkcrack修改压缩包密码
破解出压缩包的三段密钥后,可以用 -U 参数修改压缩包密码并导出
|
|
得到密钥后反向爆破压缩包密码
|
|
在比赛中的使用记录
2022 西湖论剑zipeasy
|
|
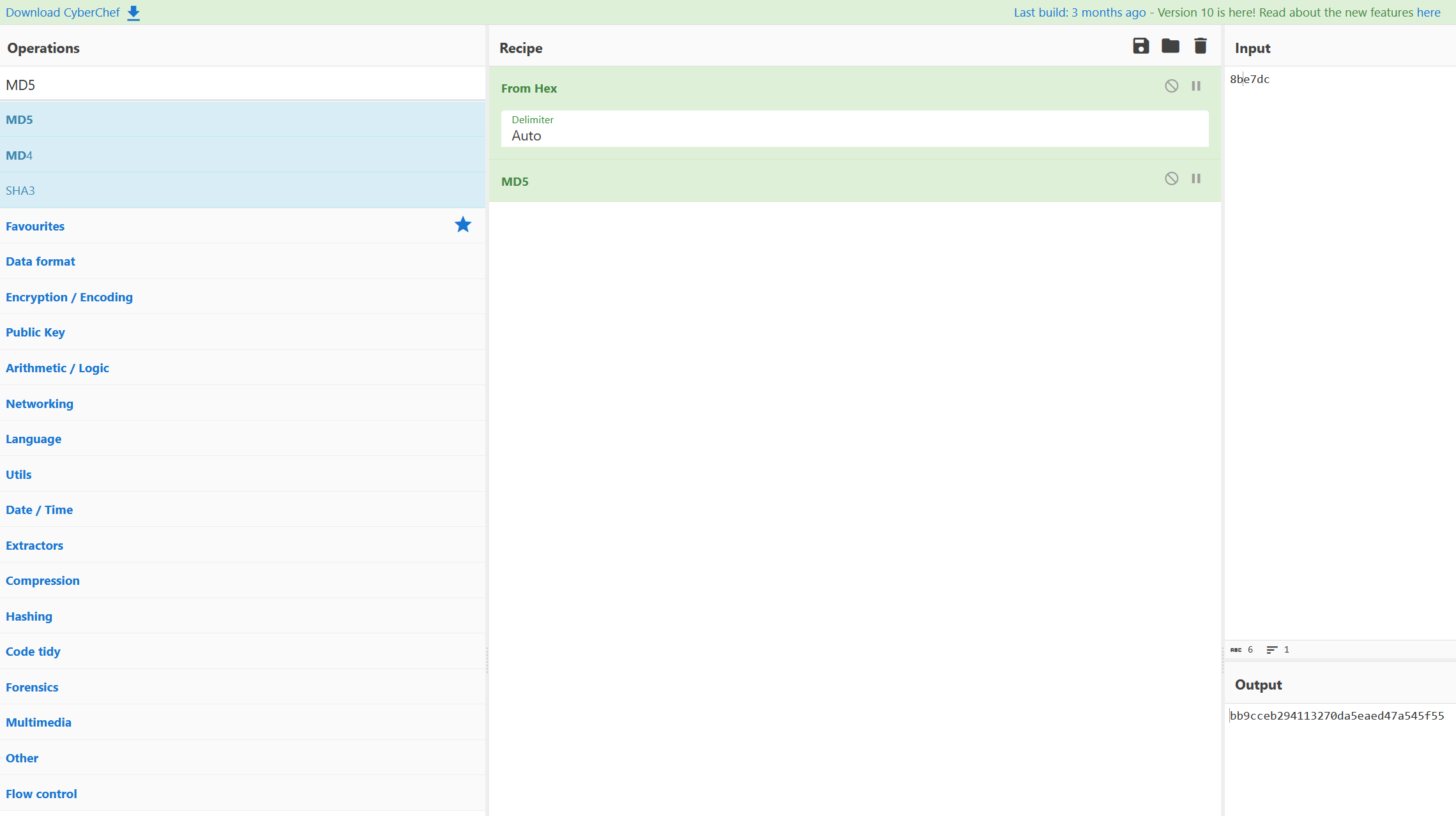
2023 DASCTFxCBCTF
利用bkcrack反向爆破密钥
|
|
然后如果要对得到的密钥进行MD5加密,可以使用CyberChef(From Hex + MD5)
Tips:
明文攻击失败可以尝试多换几个压缩软件:Bandizip、Winrar、7zip、360压缩、2345压缩、kali自带的压缩软件等
这里
echo -n xxx > 1.txt要注意在Windows下使用默认是utf-16LE编码,Linux下使用才是utf-8,这个原因也会导致攻击失败这里密钥爆破成功后推荐使用-U改密码导出压缩包,不推荐使用-d直接解出对应文件,因为如果文件是
deflate压缩的直接解出来会乱码
10、直接补上Zlib头解压
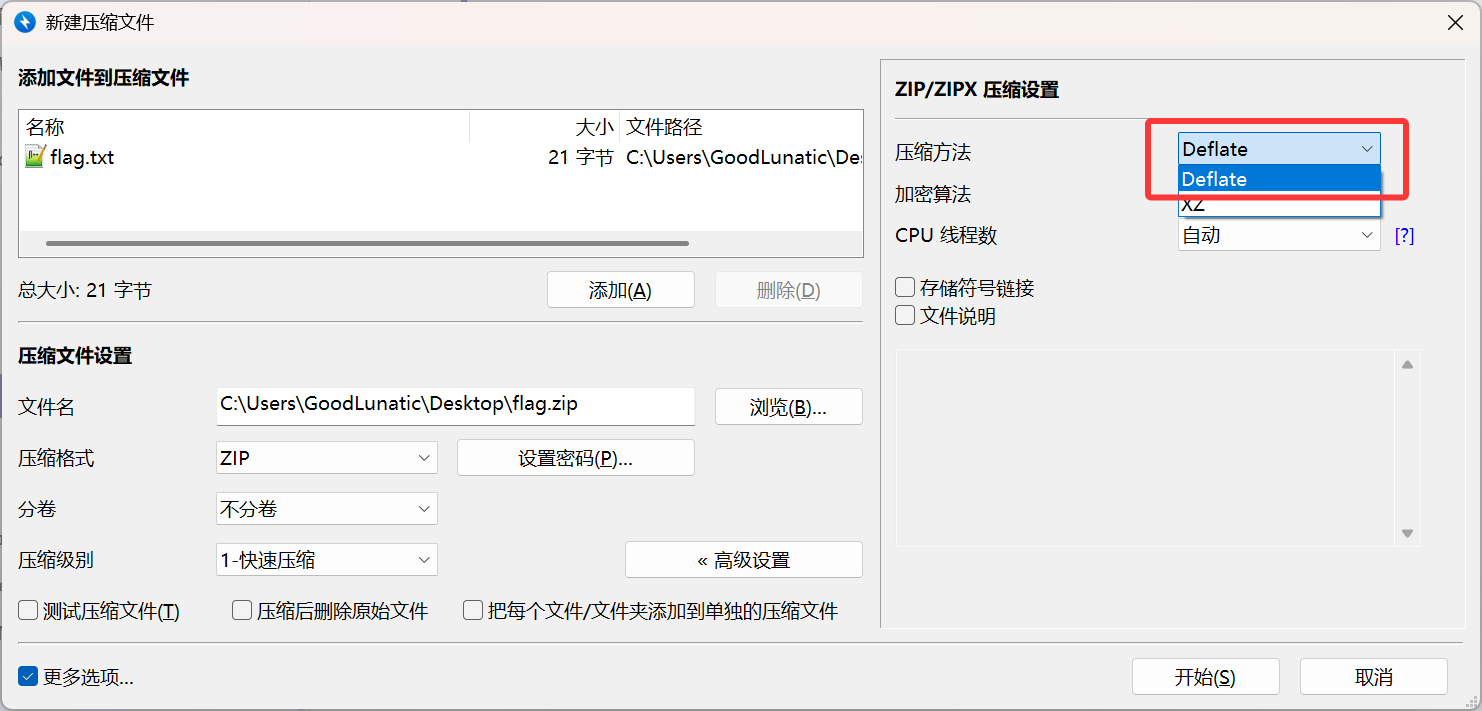
假如压缩包在压缩时选择的是无加密并且压缩方法是Deflate
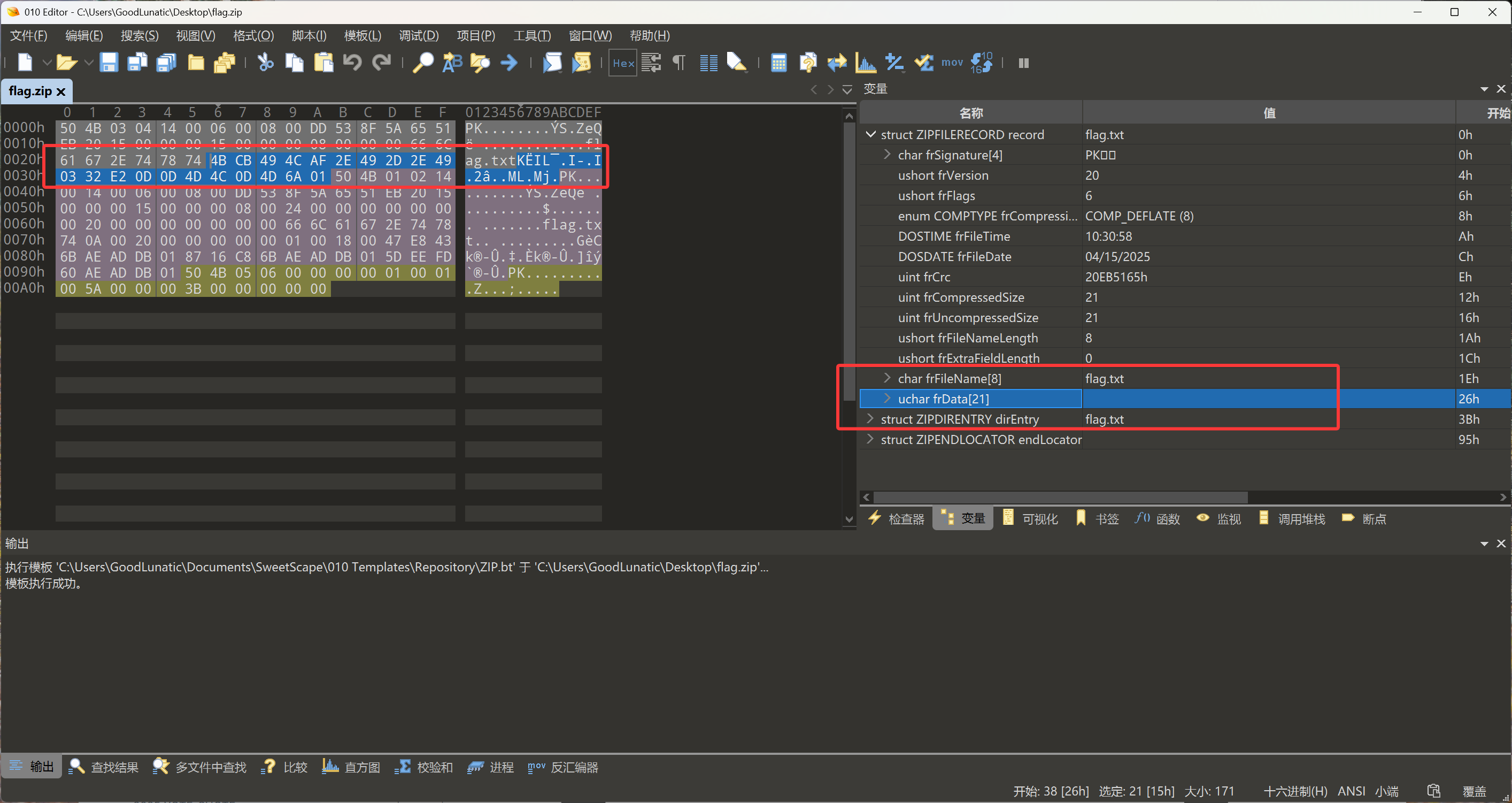
我们可以直接在010中把frData的数据提取出来,前面加上78 9C然后Zlib Inflate解压即可
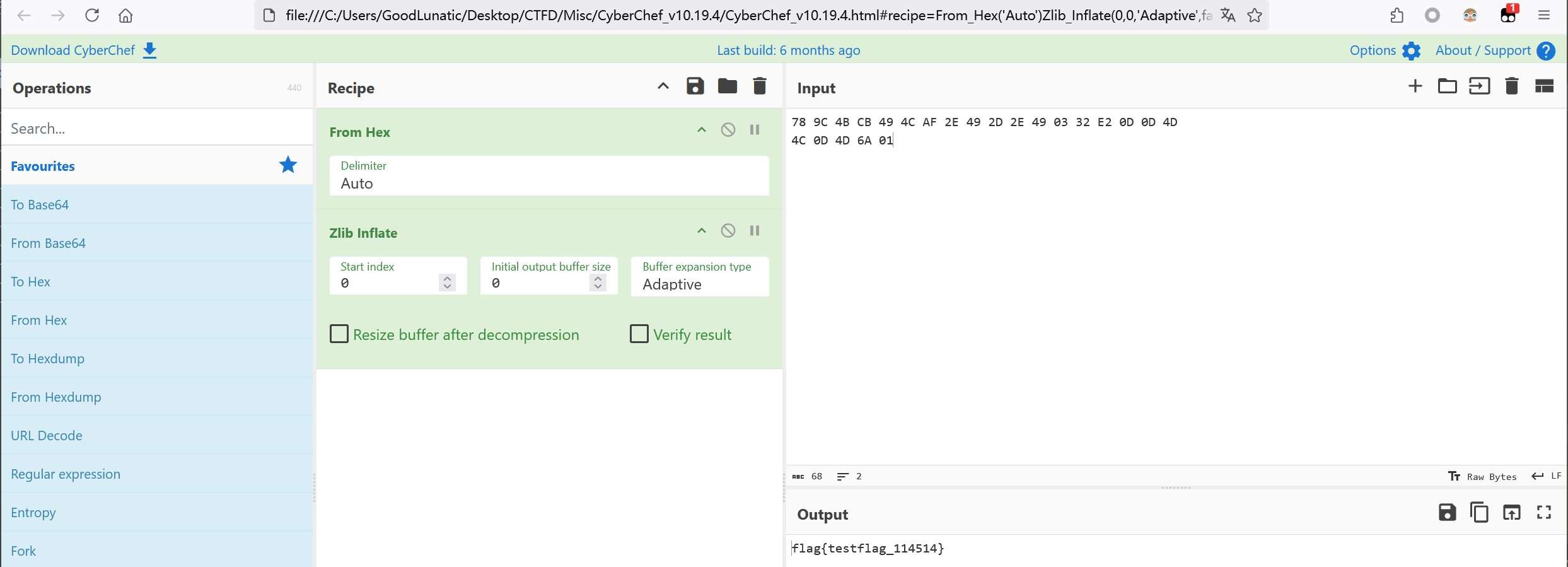
例题1-2025TGCTF-ez_zip
11、把加密的压缩包篡改成伪加密的情况
解决方案:将加密位修改回来即可
以下内容参考自八神:
frFlags和deFlags这两字节其实就叫Flags,010模板里写fr和de是为了区分数据存储区还是中央目录区
然后这两字节一共16bit,只有最低位是记录加密与否的,倒数第二三两个bit记录压缩选项,大部分情况下改了没事
但这两字节改成09的话就动了倒数第四个bt,记录数据描述符,这个bit是1的话,标头里的CRC32和文件大小是未知的
实际数据会以额外的12或16字节结构出现在压缩数据后面,把一个实际上没有数据描述符的压缩包的flags倒数第四bit改成1
会导致软件被指示去读取一个不存在的描述符片段,从而导致后续的数据读取全部错乱
12、压缩包文件时间戳隐写
如果是加密的压缩包,可以用下面的脚本提取时间戳,然后尝试转Ascii码
|
|
如果压缩包没有加密,并且用上面的脚本提不出来有用的信息
可以尝试先解压到一个目录中,然后写脚本读取目录中所有文件修改时间的时间戳
|
|
例题1-2024ISCC-时间刺客
例题2-环环相扣
Misc——视频题思路:
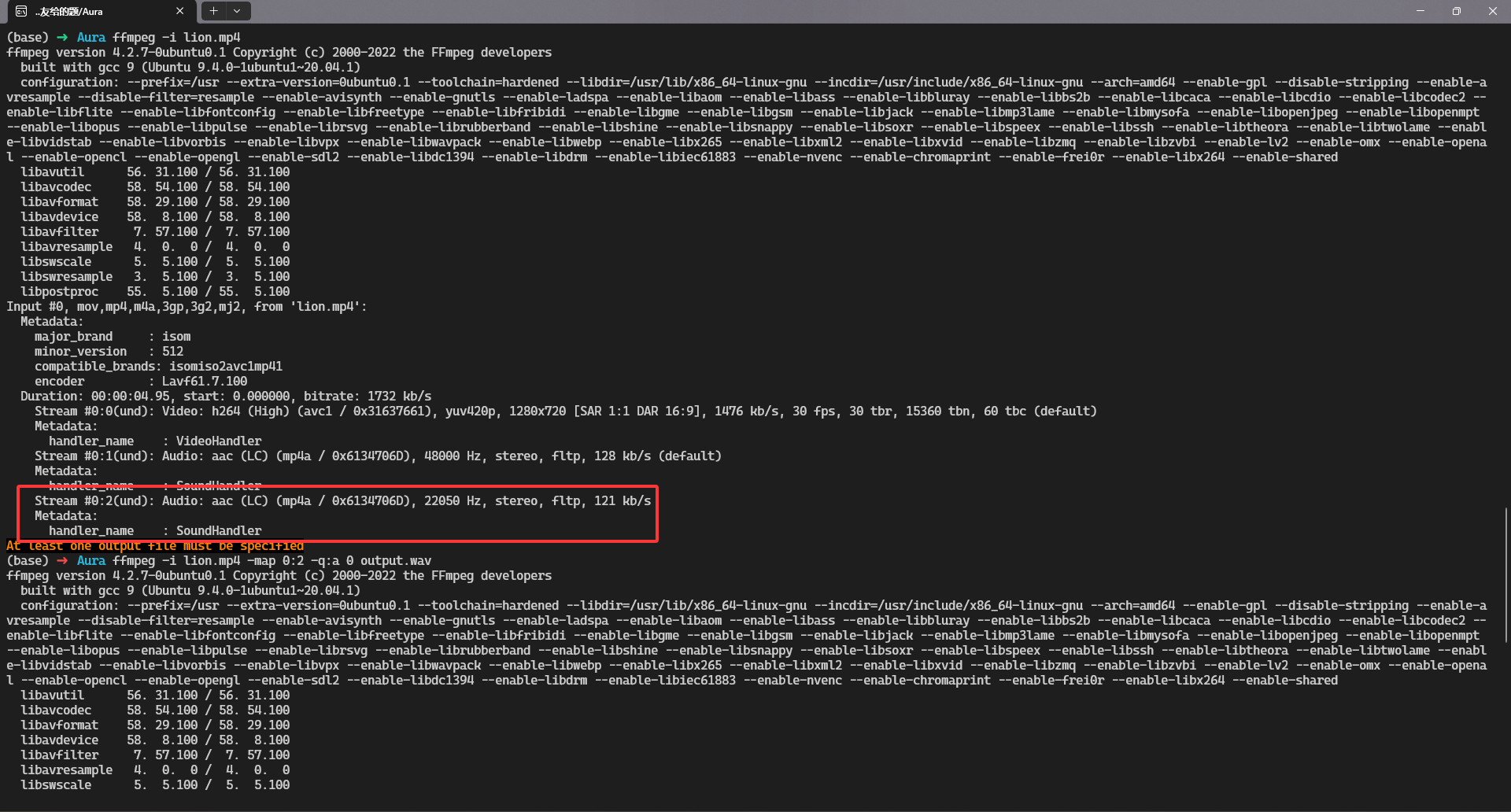
1、视频中的音频存在隐写
|
|
2、可能是视频中的每一帧图片都有LSB隐写(2023 WMCTF)
3、循环读取视频每一帧图像中指定列的指定像素(2023 极客大挑战)
|
|
4、DeEgger Embedder隐写
可以直接使用 DeEgger Embedder 工具 extract files
例题-攻防世界 PyHaHa
Misc——音频题思路:
1、波形图分析:摩斯电码
2、频谱图分析(有时要调高最高频率):
3、Silenteye隐写
wav音频文件可能是silenteye隐写,可以拿silenteye用默认密码解密试试看
当然如果已知密钥的话就用密钥去解密
4、Deepsound隐写
先用 deepsound 打开试一下,如果需要密码说明就是 deepsound 隐写,有密钥直接填入密钥解密即可
如果是 deepsound 隐写并且没有密钥,就先用deepsound2john脚本获取wav文件的哈希值(注释里有使用方法),
然后拉入kali用john爆破hash(如果编码有误,可以先用notepad另存为一下)
执行:john 1.txt
5、SSTV慢扫描电视:
SSTV识别可以直接用这个项目里的脚本:https://github.com/colaclanth/sstv
|
|

Windows中使用RX-SSTV
使用前还要安装虚拟声卡 Virtual Audio Cable
|
|
拉入kali用qsstv(有时候要用到反向和反相)
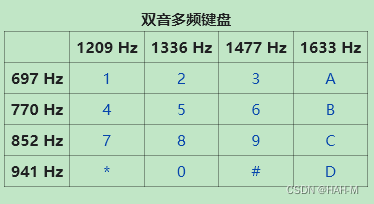
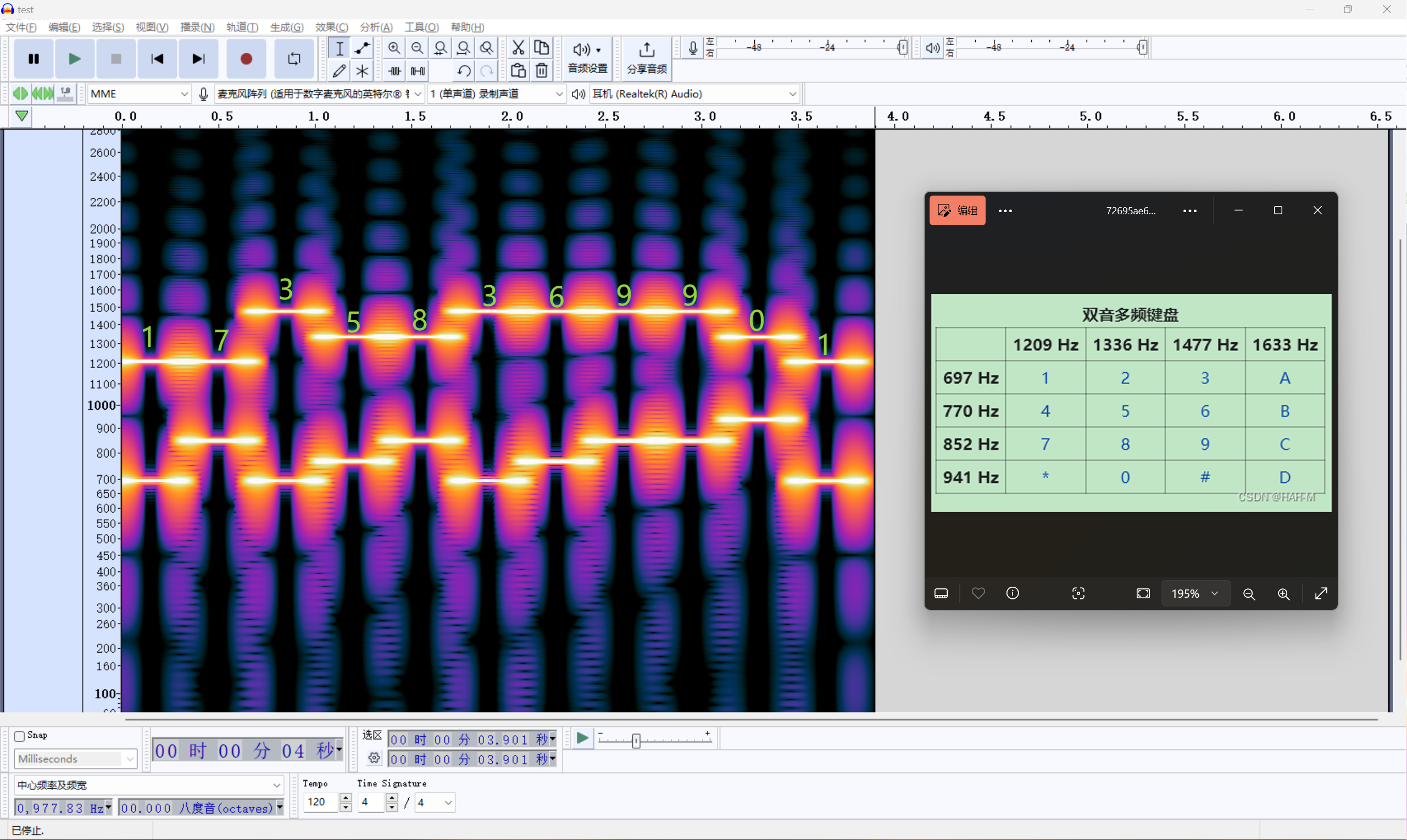
6、电话音分析(DTMF)
用在线网站解码:http://www.dialabc.com/sound/detect/
或者在Windows下使用ribt/dtmf-decoder这个开源项目解密
上面工具的识别可能有误差,如果想要更加精确,可以尝试按照下面这个对照表用肉眼去看
参考链接:https://blog.csdn.net/qawsedrf123lala/article/details/132084646
Tips:如果音频中看不出来可以尝试在Au中把音频增幅,要求能看到两条白线
7、wav可能是业余无线电文件:
先用sox把wav转为raw:
sox -t wav latlong.wav -esigned-integer -b16 -r 22050 -t raw latlong.raw
再用multimon-ng分析:
multimon-ng -t raw -a AFSK1200 latlong.raw
8、WAV可能是steghide隐写(可以无密码)
|
|
在WSL或者kali里用Stegseek跑(字典在wordlist里)
|
|
|
|
9、MP3可能是mp3stego隐写(可以无密码)
使用前需要先把要处理的文件放到 mp3stego 目录下
|
|
10、WAV还可能是OpenPuff隐写(有密码)
直接用OpenPuff.exe解密即可
11、stegpy隐写
stegpy 开源地址 下载好后直接用WSL输入以下命令并输入密码解密即可
也可以直接用 pip 安装: pip3 install stegpy
|
|
12、DeEgger Embedder隐写
可以直接使用 DeEgger Embedder 工具 extract files
13、提取WAV中LSB隐写的数据
|
|
14、分析WAV左右声道的差值
|
|
15、使用脚本提取WAV数据进行分析
|
|
16、提取两个WAV音频中的浮点集并分析
例题1-2024极客大挑战-音乐大师
|
|
Misc——取证题思路:
详见作者博客中的 Misc-Forensics 这篇文章
Git文件泄露:
1、利用命令git stash show 显示做了哪些改动
2、利用命令git stash apply导出改动之前的文件
OSINT
1.用yandex识图
Others:
字节序
字节的排列方式有两个通用规则:
|
|
例子:
|
|
为何要有字节序
|
|
使用Python中的struct模块来处理大小端序
|
|
十六进制数据大小端序转换
|
|
Linux tar命令
打包压缩
|
|
解压提取
|
|
pyc隐写
使用开源工具:https://github.com/AngelKitty/stegosaurus
对隐写的内容进行提取即可
