这比赛有点难评只能说,但是确实是《人民的好比赛》
题目名称 RSA_KU
解一个方程就可以得到p和q,然后解RSA即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import gmpy2
from sympy import *
from Crypto.Util.number import *
n = 129699330328568350681562198986490514508637584957167129897472522138320202321246467459276731970410463464391857177528123417751603910462751346700627325019668100946205876629688057506460903842119543114630198205843883677412125928979399310306206497958051030594098963939139480261500434508726394139839879752553022623977
e = 65537
c = 81542950634170106435892662475507283547967877210216191810634513013031046158459269258017597038287472919950811537049030186565471870789076226171751774409328287149914234904307925163438628271194937049804334335349685851934799426152133152587428808924287968838087416148799251156379854263050430010921100416842555347176
r1 = 129699330328568350681562198986490514508637584957167129897472522138320202321246467459276731970410463464391857177528123417751603910462751346700627325019668067056973833292274532016607871906443481233958300928276492550916101187841666991944275728863657788124666879987399045804435273107746626297122522298113586003834
r2 = 129699330328568350681562198986490514508637584957167129897472522138320202321246467459276731970410463464391857177528123417751603910462751346700627325019668066482326285878341068180156082719320570801770055174426452966817548862938770659420487687194933539128855877517847711670959794869291907075654200433400668220458
p = Symbol('p')
q = Symbol('q')
res = solve([(p-2)*(q-1)-r1, (p-1)*(q-2)-r2], [p, q])[1]
p = int(res[0])
q = n//p
phi = (p-1)*(q-1)
d = gmpy2.invert(e, phi)
m = pow(c, d, n)
# print(m)
print(long_to_bytes(m))
# b'ISCC{EmTOvTJP4NZQLr8Yy2--}'
|
题目名称 时间刺客
题目附件给了一个压缩包,解压后得到给你也用不了.pcap和29.7z
打开流量包,发现是USB流量,直接用脚本进行提取后可以得到如下内容
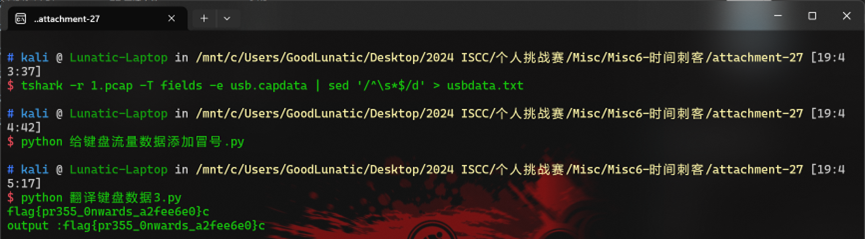
但是经过尝试发现是个假的flag,其实流量包的文件名也提示了
之后仔细查看题目名称:时间刺客
以及题面的提示:2024年10月14日早8点,小明敲键盘时候解出了flag
猜测与这个时间有关,然后在29.rar中发现了接近的时间
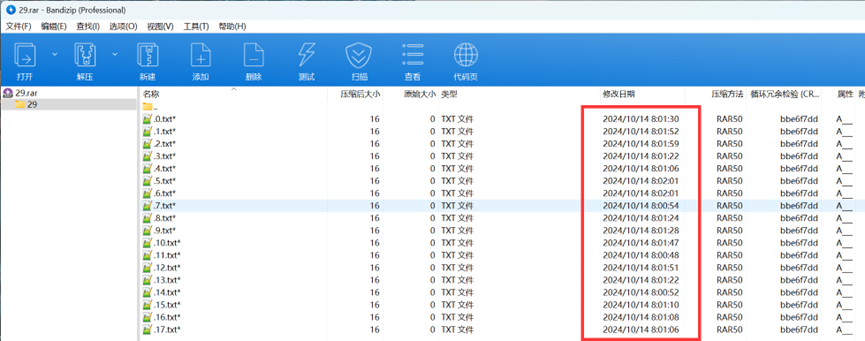
经过尝试,发现直接把文件0.txt-1.txt的时间减去题面中的时间得到的秒数
转为ascii码然后套上ISCC{} 就是flag:ISCC{ZpwRByy6TXk0oR4FDB}
1
2
3
4
5
|
data = "90 112 119 82 66 121 121 54 84 88 107 48 111 82 52 70 68 66"
ls = data.split()
print(ls)
for item in ls:
print(chr(int(item)), end="")
|
题目名称 工业互联网模拟仿真数据分析
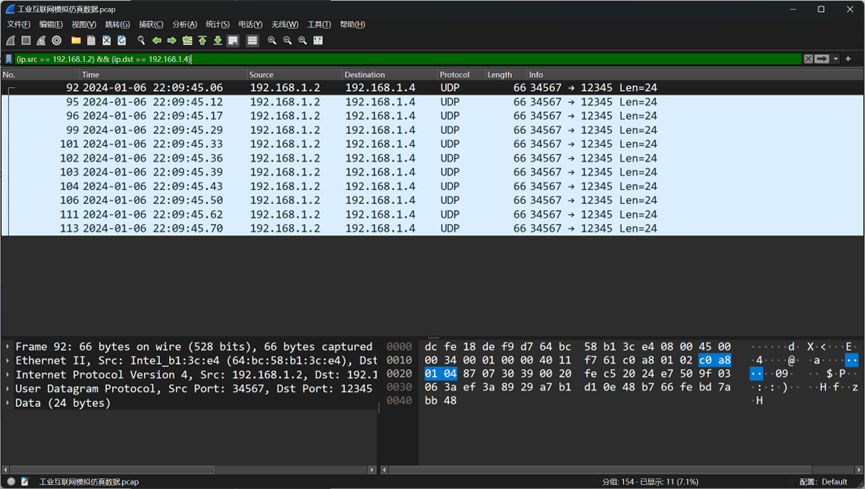
题目一:在某些网络会话中,数据包可能保持固定大小,请给出含有此确定性特征的会话IP地址和数据包字节大小值。
使用wireshark的过滤器一个个筛选,发现(ip.src == 192.168.1.2) && (ip.dst == 192.168.1.4)的数据包的长度都是24,因此这题的答案就是
192.168.1.2,192.168.1.4,24
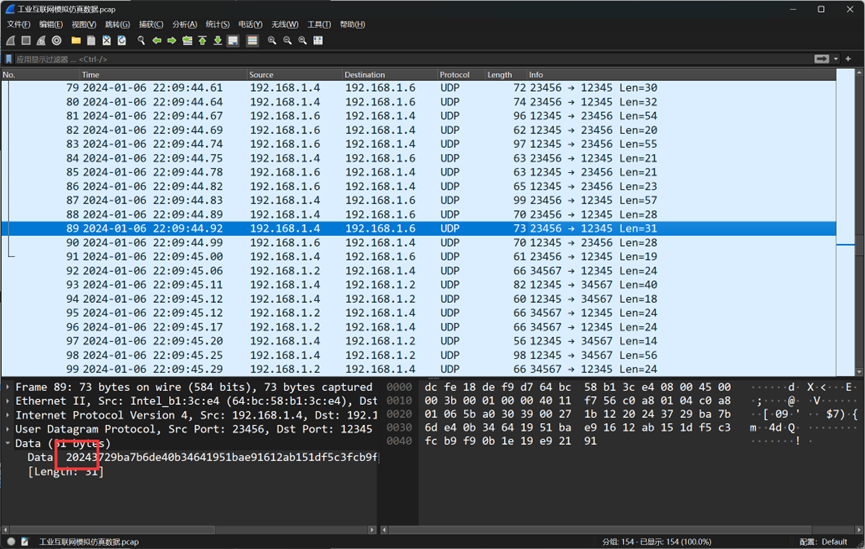
题目二:通信包数据某些字段可能为确定的,请给出确定字节数值。
翻看流量包,关注流量的data字段,发现data字段的前四位都是2024
因此本题的答案就是 2024
题目三:一些网络通信业务在时间序列上有确定性规律,请提供涉及的IP地址及时间规律数值(小数点后两位)
使用wireshark的过滤器进行筛选,发现只有(ip.src == 192.168.1.3) && (ip.dst == 192.168.1.5)的每帧的间隔都大致为0.06
因此本题的答案为:192.168.1.3,192.168.1.5,0.06
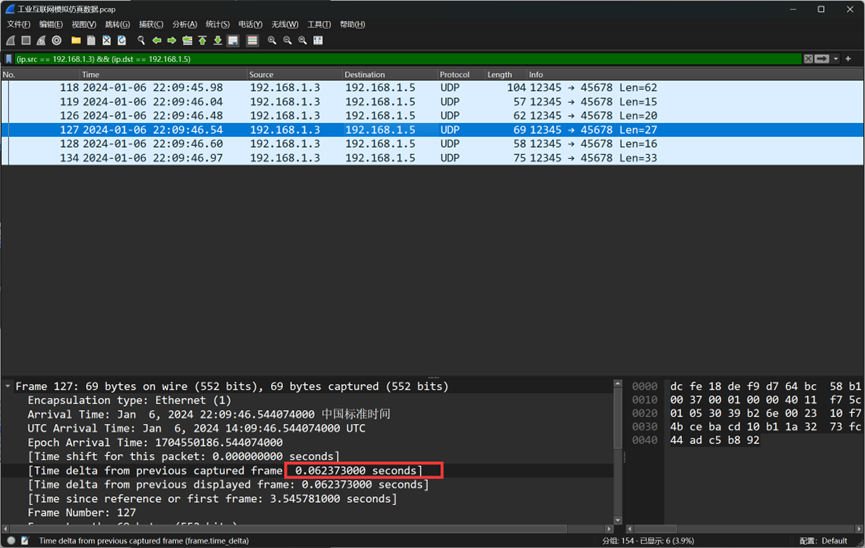
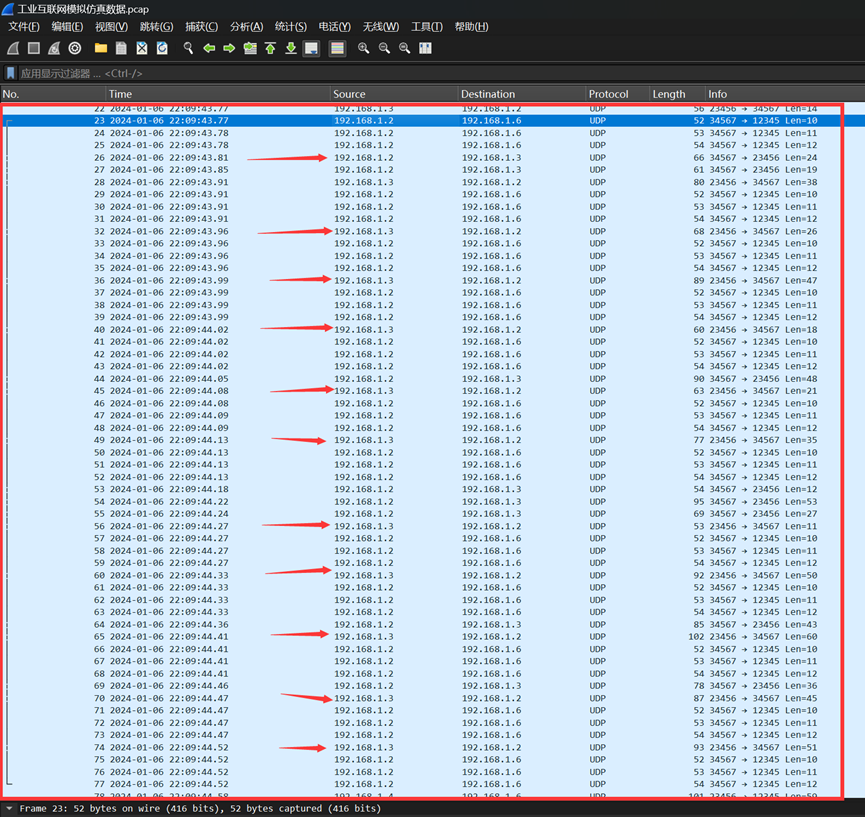
题目四:一些网络通信业务存在逻辑关联性,请提供涉及的IP地址
因为题目中提示了逻辑关联性,因此猜测是两个以上ip之间连续的通信
翻看流量包,发现只有192.168.1.2,192.168.3,192.168.1.6有这样的特征
仔细查看下图中的分组,发现这三个ip的通信有明显的规律
因此大胆猜测本题答案就是 192.168.1.2,192.168.3,192.168.1.6
题目五:网络数据包往往会添加数据完整性校验值,请分析出数据校验算法名称及校验值在数据包的起始位和结束位(倒数位)
校验算法网上一搜很容易就可以知道只可能是:CRC16或CRC32
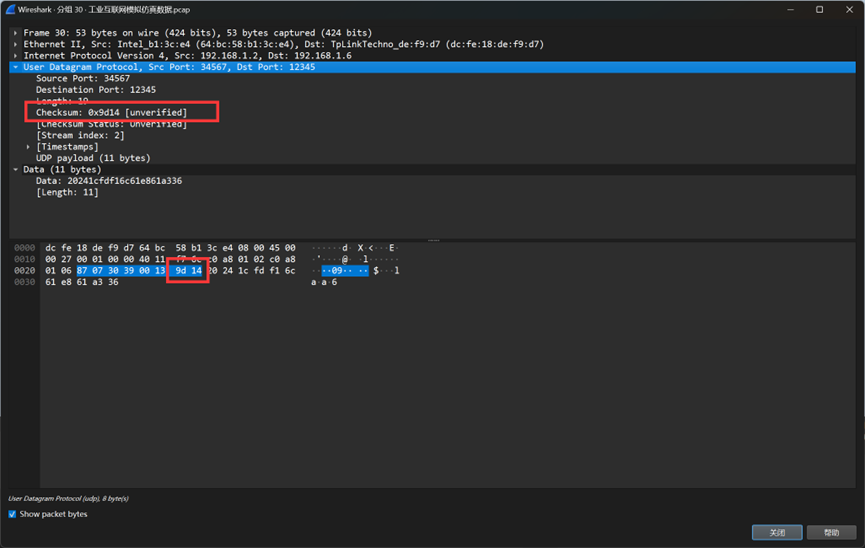
然后题目提示结束位是倒数位,如上图,很容易可以知道是 1
如果是上图那样的顺序,起始位应该是7,但是提交后发现不对
因此遍历1-7以及对CRC16和CRC32进行尝试,发现遍历到4且校验算法是CRC16的时候答案正确
因此本题的答案为:CRC16,4,1
最后使用题目附件给的 flag.py 生成flag即可
adcca5c2a82064a17a645d35b6b054cd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import hashlib
def generate_flag(*answers):
# 将所有答案使用英文逗号连接
combined_answers = ','.join(answers)
# 生成flag格式
initial_flag = f"ISCC{{{combined_answers}}}"
# 对flag进行MD5加密
md5_hash = hashlib.md5(initial_flag.encode()).hexdigest()
return md5_hash
# 示例用法
if __name__ == "__main__":
answers = [
"192.168.1.2,192.168.1.4,24", # 第一小题答案:IP顺序从小到大排列,涉及的IP个数由选手自己判断,数值为整数
"2024", # 第二小题答案:数值为整数
"192.168.1.3,192.168.1.5,0.06", # 第三小题答案:IP顺序从小到大排列,涉及的IP个数由选手自己判断,数值保留小数点后2位
"192.168.1.2,192.168.1.3,192.168.1.6", # 第四小题答案:IP顺序从小到大排列,涉及的IP个数由选手自己判断
"CRC16,4,1" # 第五小题答案:数据校验算法名称长度为5个字符,其中英文字母大写
]
# 生成MD5加密后的flag
final_flag = generate_flag(*answers)
# 输出最终的MD5加密字符串
print(final_flag)
# adcca5c2a82064a17a645d35b6b054cd
|
题目名称 Number_is_the_key
题目附件给了一个后缀为 .xlsx 的 Excel 文件
打开发现是空白的,因此我们将其后缀改为 .zip 然后解压
然后查看 sheet1.xml 文件
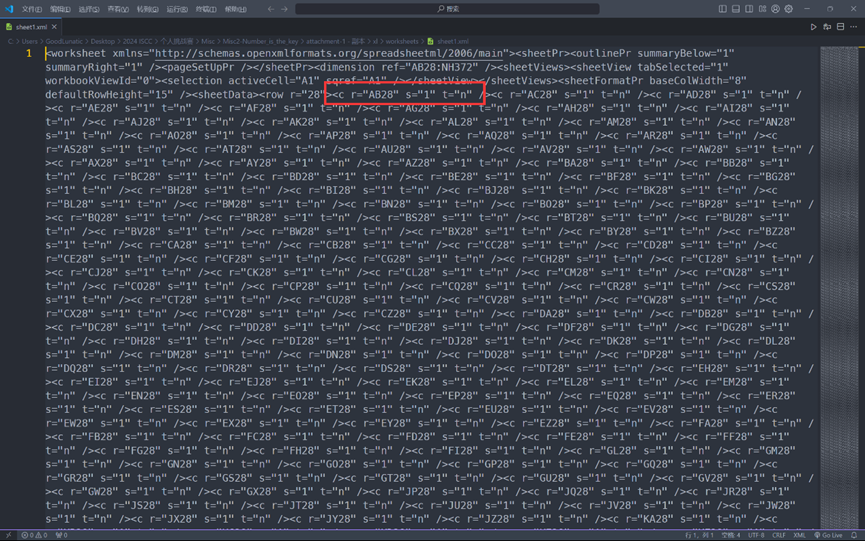
发现从 AB28 开始后的单元格就设置了特殊的格式
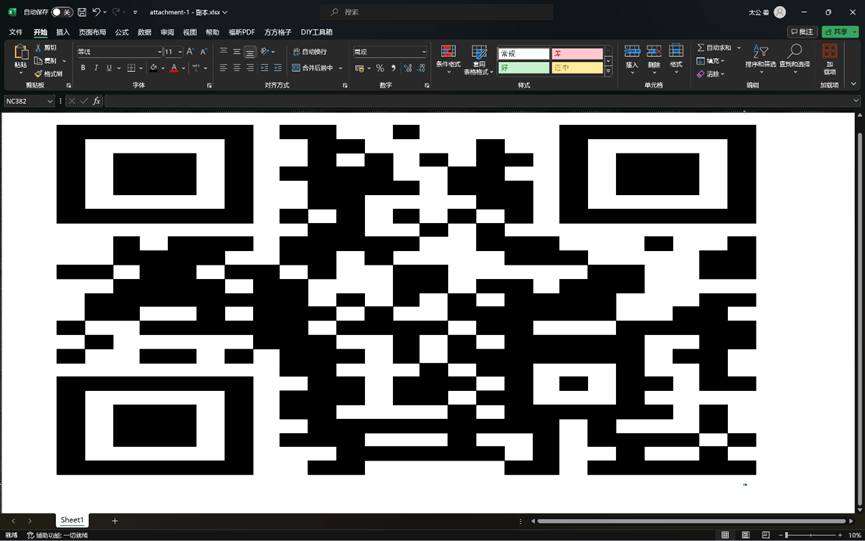
因此,我们使用 Excel 的 方方格子 插件,将所有带有特殊格式的单元格都染上黑色
最后就可以得到一张二维码,扫码然后套上 ISCC{} 即可得到flag:ISCC{NEfmGuWH9kj3}
题目名称 钢铁侠在解密
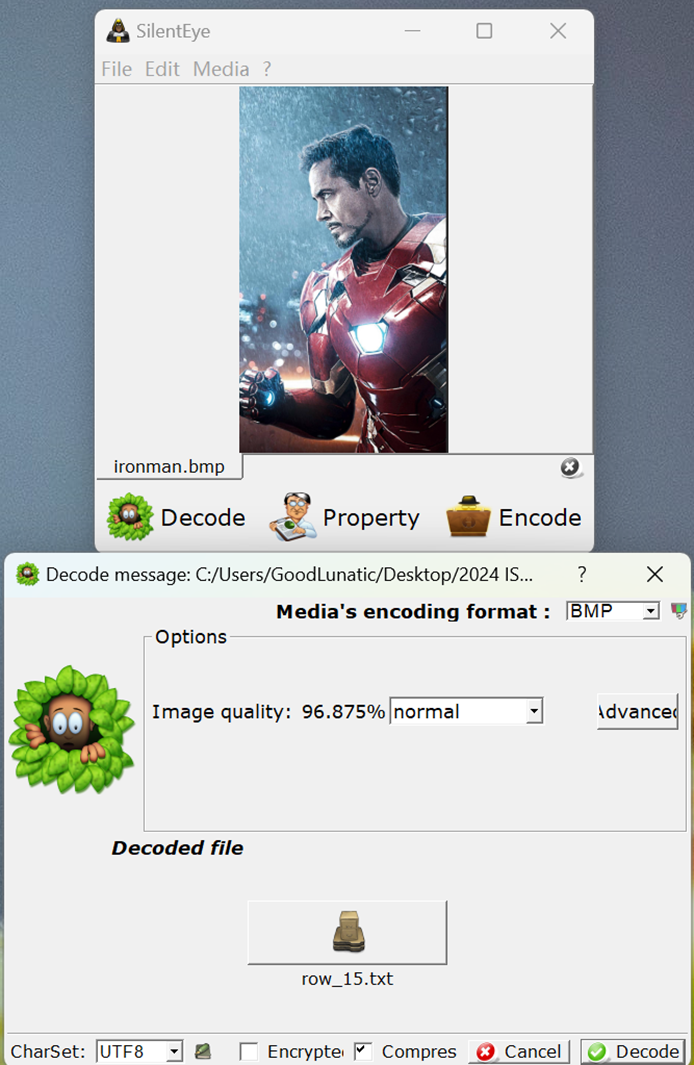
下载附件得到一张bmp和一个txt文件,txt中的内容如下

bmp图片用silenteye的默认密钥解密可以得到一个row_15.txt文件,内容如下

然后根据第一个txt中的两个message,猜测是Franklin-Reiter攻击
因此编写以下sage脚本解密即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
from Crypto.Util.number import *
def pdivmod(u, v):
q = u // v
r = u - q*v
return (q, r)
def hgcd(u, v, min_degree=10):
x = u.parent().gen()
if u.degree() < v.degree():
u, v = v, u
if 2*v.degree() < u.degree() or u.degree() < min_degree:
q = u // v
return matrix([[1, -q], [0, 1]])
m = u.degree() // 2
b0, c0 = pdivmod(u, x ^ m)
b1, c1 = pdivmod(v, x ^ m)
R = hgcd(b0, b1)
DE = R * matrix([[u], [v]])
d, e = DE[0, 0], DE[1, 0]
q, f = pdivmod(d, e)
g0 = e // x ^ (m//2)
g1 = f // x ^ (m//2)
S = hgcd(g0, g1)
return S * matrix([[0, 1], [1, -q]]) * R
def pgcd(u, v):
if u.degree() < v.degree():
u, v = v, u
if v == 0:
return u
if u % v == 0:
return v
if u.degree() < 10:
while v != 0:
u, v = v, u % v
return u
R = hgcd(u, v)
B = R * matrix([[u], [v]])
b0, b1 = B[0, 0], B[1, 0]
r = b0 % b1
if r == 0:
return b1
return pgcd(b1, r)
N = 14333611673783142269533986072221892120042043537656734360856590164188122242725003914350459078347531255332508629469837960098772139271345723909824739672964835254762978904635416440402619070985645389389404927628520300563003721921925991789638218429597072053352316704656855913499811263742752562137683270151792361591681078161140269916896950693743947015425843446590958629225545563635366985228666863861856912727775048741305004192164068930881720463095045582233773945480224557678337152700769274051268380831948998464841302024749660091030851843867128275500525355379659601067910067304244120384025022313676471378733553918638120029697
e = 52595
C1 = 802093892729192941580665011605981398643530233926109463886209503685959095613171485985762661514322963576269598152729097579533877674515875516282404529508497779730189074032928274695857168424002886904858686000461526126614908827244676771690725888152210040841972944761623077247602641877126957731257208582410945549031425565879267159184883137909818689997281974273252574535681544530587715066564265243494048246112594995638340450339106354505485106648286015712536198070069919772614706832920562663986301064607437301824460692026593701216796871799380302113057481598882604838413416307504118805969161357431328680495141776275071296173
C2 = 4347759269713255842868721891321309924474876284811676713945108771523855679085766955818799612747337385232455809605793392968961849166829723223104940826515052145950180478123326816893736987699542015096462429328699032881765214583786779076664315615319762383761580464345845869110150235370030567992797358255647147096147592022154816132252299082589333757444673894458399459786203403775172278814851528256257984749914424362937769063724056491014110490780419677743398985039331667919664612815248085943101548896494990284248046124975509017022846681134773052692726968901967721594274742239819769033528383898901918890790453848947445365073
m1 = b'iscc'
m2 = b'good'
P.< x > = PolynomialRing(Zmod(N))
g1 = (x*2**32+bytes_to_long(m1))**e - C1
g2 = (x*2**32+bytes_to_long(m2))**e - C2
r = pgcd(g1, g2)
flag = int(-r.monic().constant_coefficient())
print(long_to_bytes(flag))
# b'flag{xu_huai_ruo_gu_264}
|
参考链接:
https://github.com/RICSecLab/ricerca-ctf-2023-public/blob/1670030e7d6200e572a5fd85951ac8f6e4f0fbc6/crypto/rsalcg/solution/solve.sage
题目名称 成语学习
解压题目附件给的压缩包可以得到:发了一堆东西.pcap和something_copy.zip
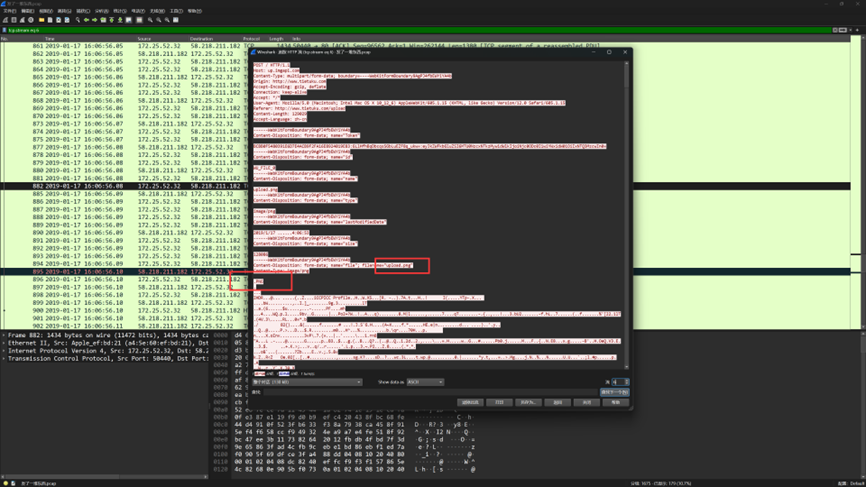
追踪HTTP流,在流6中发现上传了一张png图片,手动提取出这张图片
010打开发现存在CRC错误,猜测被改宽高了,使用脚本爆破并修复
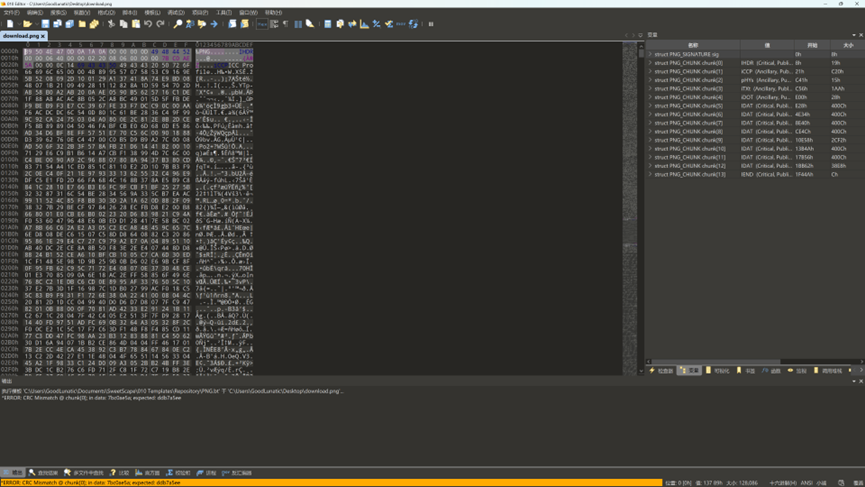
复完成后可以得到下图,发现压缩包的解压密码:57pmYyWt
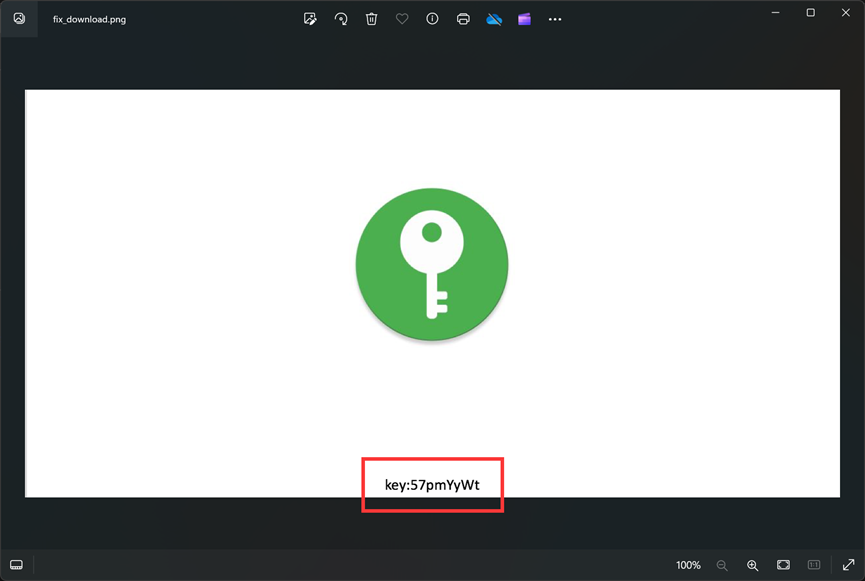
使用得到的密码解压压缩包,可以得到一个文件,010查看文件头:504B0304,发现是个压缩包
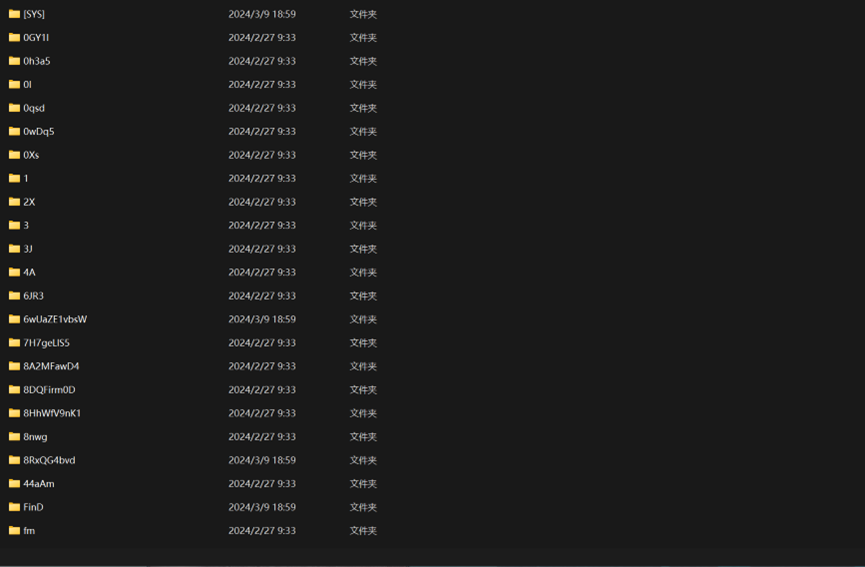
因此改后缀为.zip并解压,解压后可以得到一个Linux ext格式磁盘的目录
直接使用everything查看所有文件的修改时间,在O7avZhikgKgbF目录下找到flag.txt
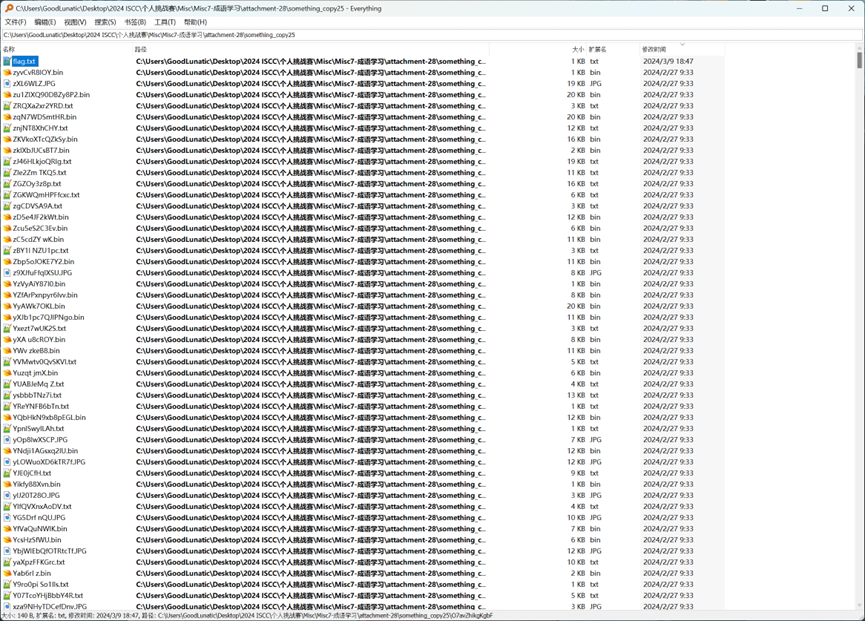
flag.txt中内容如下:
1
2
|
《你信我啊》
李维斯特指着墙上的“去甚去泰”边享用longan边和你说,你千万不要拿我的食物去加密啊。
|
上网搜索一下李维斯特,发现是MD5的设计者
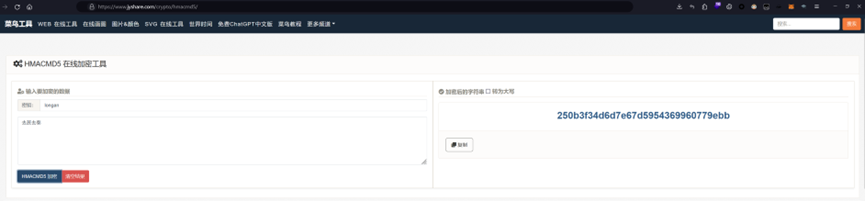
因此猜测这题需要使用MD5加密,直接使用在线网站:https://www.jyshare.com/crypto/hmacmd5/ 加密
待加密的内容是flag.txt中成语,密钥是flag.txt中的那串英文字符,加密得到的字符串套上ISCC{} 就是flag
ISCC{250b3f34d6d7e67d5954369960779ebb}
题目名称 FunZip
题目附件给了一个压缩包,解压后得到一个 .txt 文本文件
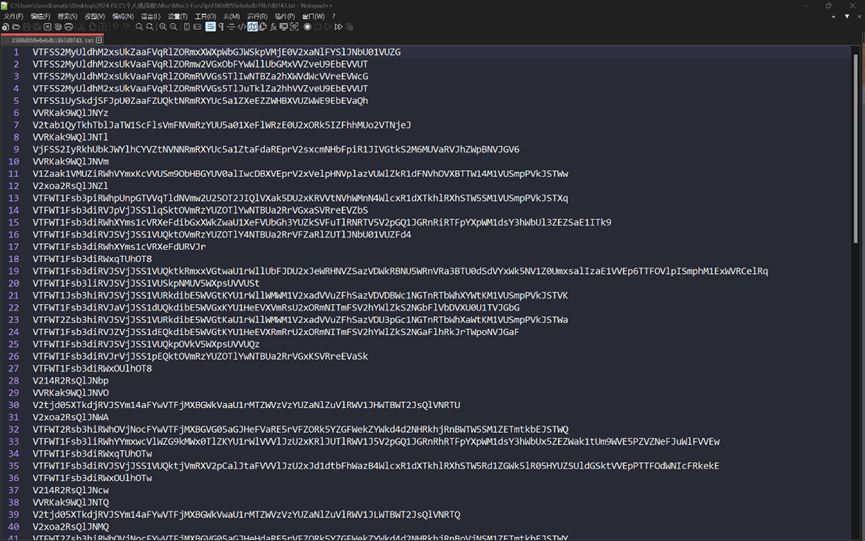
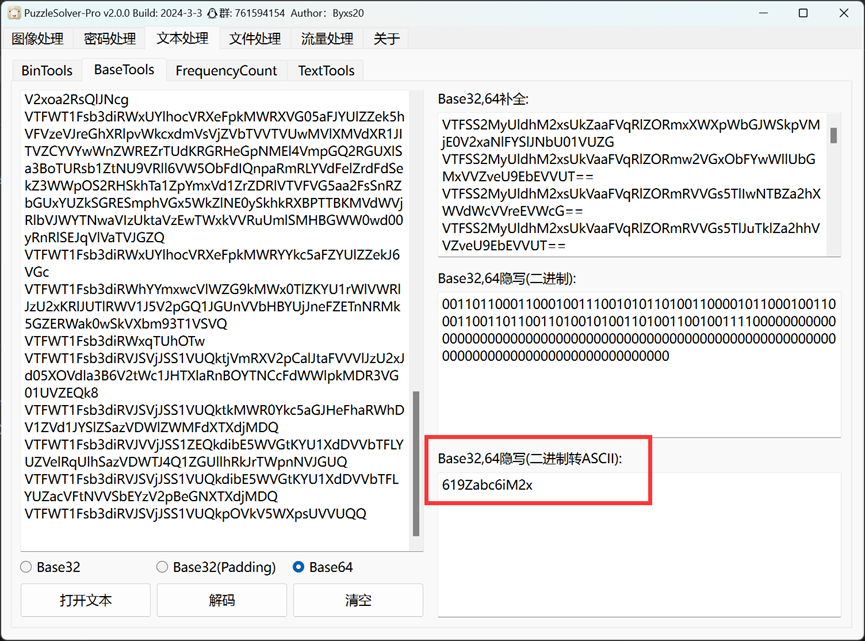
看起来像是 base64 编码后的字符串,由于是多行,所以猜测是 base64 隐写
直接使用PuzzleSolver解base64隐写然后套上 ISCC{} 即可得到flag
题目名称 Where_is_the_flag
原题,参考链接:https://miaotony.xyz/2021/12/16/CTF_2021AsuriCTF_NUAACTF_Misc/
题目附件给了一个.pyc文件,直接使用uncompyle6进行反编译
uncompyle6 .\attachment-26.pyc > decompyle.py
可以得到以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from Crypto.Cipher import AES
import binascii
def decrypt(x, cipher):
key = x + "n0lve3t6r1s"
try:
aes = AES.new(key.rjust(24, "A"), AES.MODE_ECB)
cipher = binascii.unhexlify(cipher)
flag = aes.decrypt(cipher).decode()
return flag
except:
return flag
def main():
c = "3423bdd3553eb376e55610c74e2510826ef4e99bcbb8dc0cd3db289aa729bab6"
k = input("Please input your key: ")
flag = decrypt(k, c)
if "flag" in flag:
print("Wow, you find it!!!")
else:
print("Oh no!!!")
if __name__ == "__main__":
main()
|
代码中的key还缺了一份,根据参考链接,应该是pyc隐写
使用开源工具:https://github.com/AngelKitty/stegosaurus
对隐写的内容进行提取
Extracted payload: k5fgb2eur5sty,发现和参考链接中的是一样的
因此完整的key就是:k5fgb2eur5styn0lve3t6r1s

后续步骤,直接使用参考链接中的在线网站解密即可
密文就是反编译得到的Python代码中的c
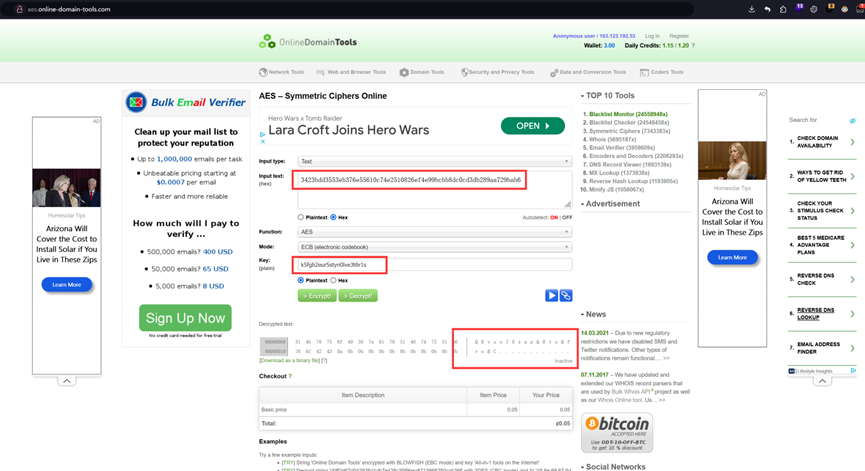
最后套上ISCC{} 就是flag:ISCC{QKvuoI8zapQHtuQfvoBC}
题目名称 有人让我给你带个话(一血)
下载附件并解压,可以得到一张png和一段未知数据
未知数据的文件名为:有人和你说了一些东西
首先使用010打开这张图片,发现末尾藏了一个rar压缩包,手动给他提取出来并解压
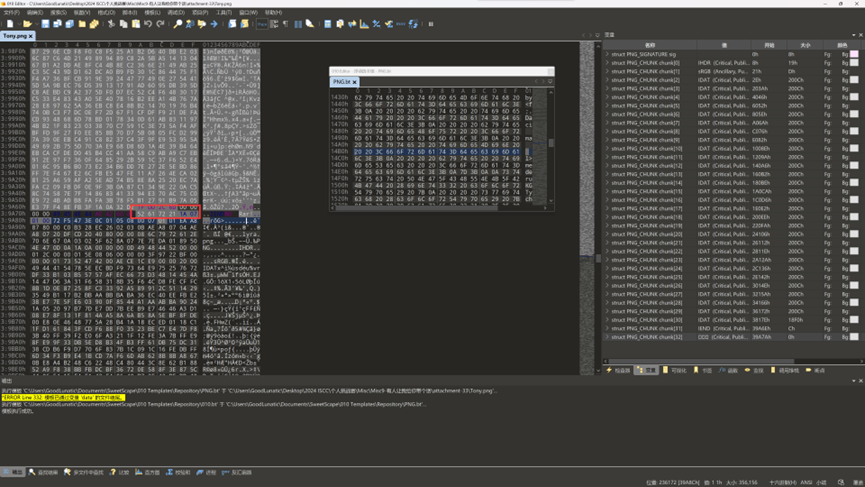
然后可以得到下面这张lyra.png

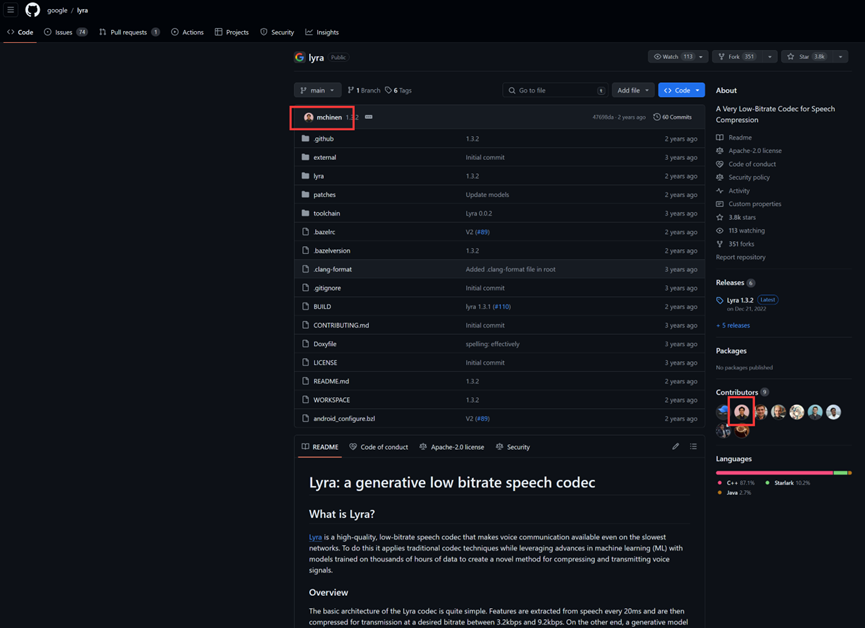
上Google搜索lyra,可以在Github中搜到这个仓库的链接
https://github.com/google/lyra
然后发现这个项目作者的头像就是上面那张png
因此猜测题目肯定跟这个项目有关了,按照Github上的步骤安装一下lyra
这个项目需要使用bazel 进行安装,所以安装lyra之前需要先安装bazel
安装完成后,把之前那段未知数据的后缀改为.lyra,然后使用lyra解码
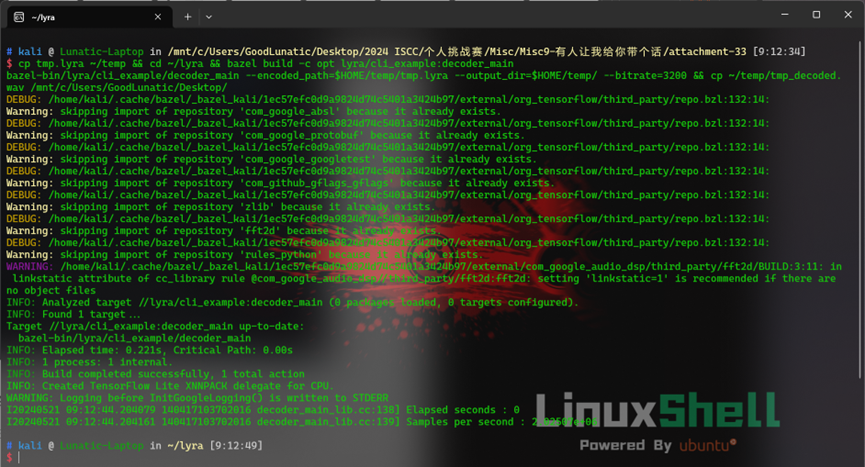
解码后可以得到一个.wav音频文件,里面的内容是社会主义核心价值观编码
最后直接使用在线网站识别并解密即可得到flag:ISCC{52IRN9UBA5RI}
题目名称 精装四合一
下载附件得到一个压缩包,解压后得到四张图片
010打开,发现每张图片的末尾都有多余的数据,但是没有发现明显的文件头
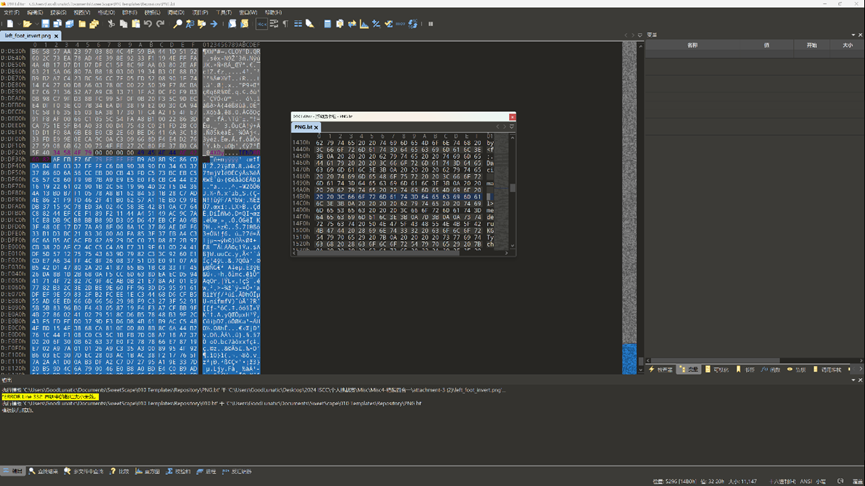
因此根据经验就可以大胆猜测是数据异或了什么
我们手动将四张图片末尾的数据都提取出来
然后用010自带的异或功能,拿出题最常见的异或值0xFF尝试一下
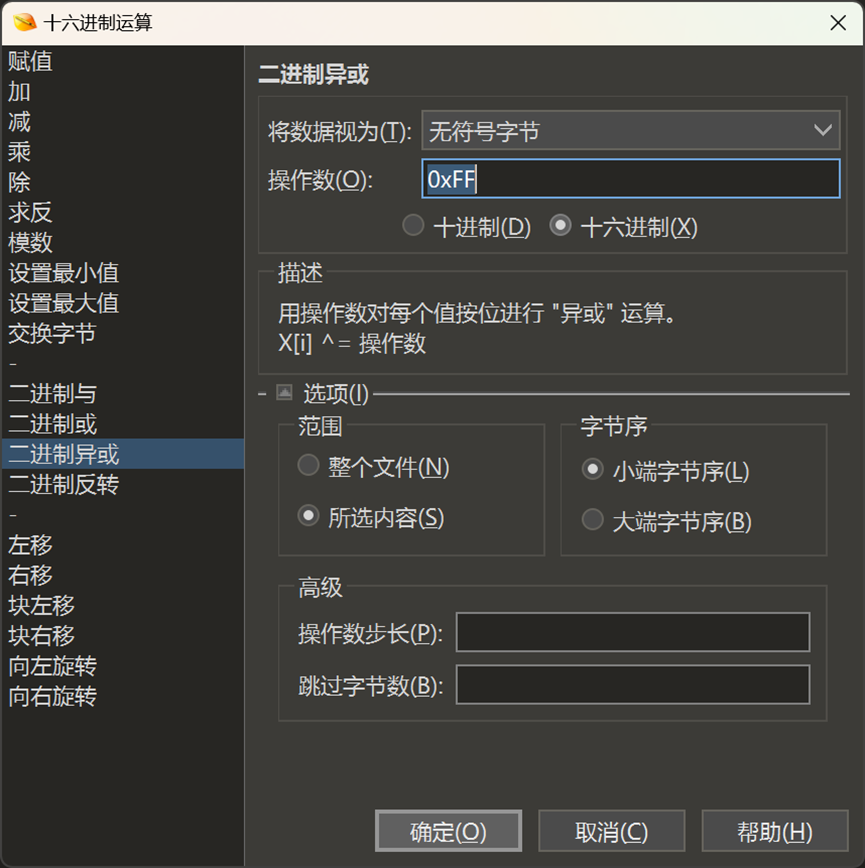
然后我们关注异或处理后数据的前几字节
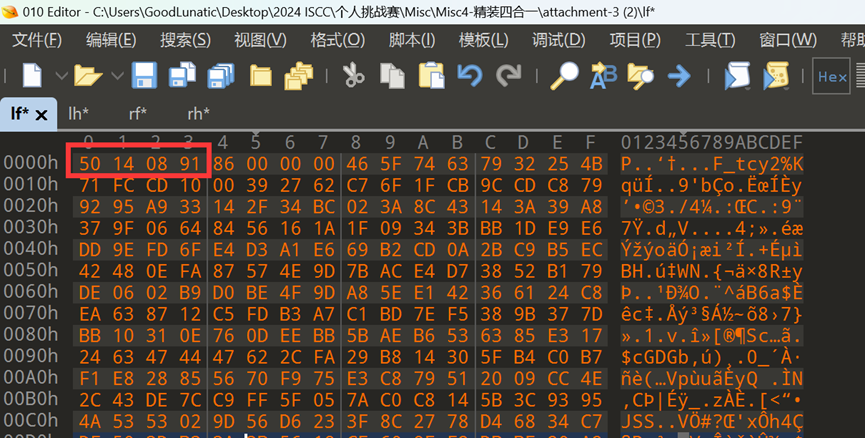
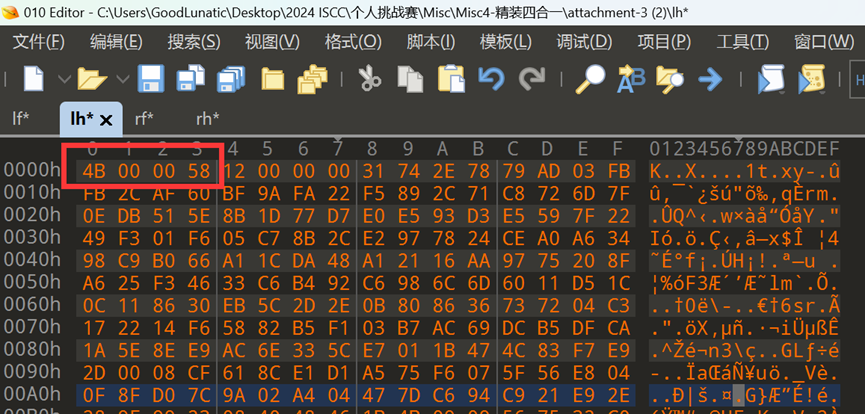
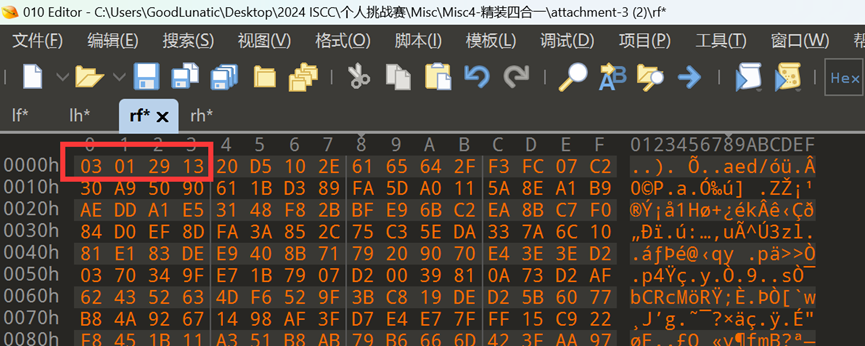
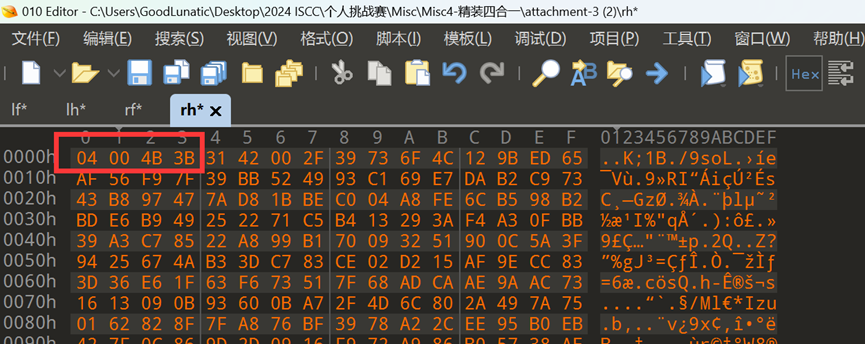
按照left_foot_invert -> left_hand_invert -> right_foot_invert->right_hand_invert的顺序,把每段数据的第一个字节连起来,可以得到 50 4B 03 04
很明显,是zip的文件头,因此我们写一个Python脚本循环提取即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
def get_data(filename):
with open(filename, 'rb') as f:
data = f.read()
return data
def solve():
res = ''
data1_hex = get_data("lf").hex()
data2_hex = get_data("lh").hex()
data3_hex = get_data("rf").hex()
data4_hex = get_data("rh").hex()
# print(type(data1_hex))
for index in range(0, len(data1_hex), 2):
try:
res += data1_hex[index:index+2]+data2_hex[index:index+2] + \
data3_hex[index:index+2]+data4_hex[index:index+2]
except:
pass
res = bytes.fromhex(res)
with open('flag.zip', 'wb') as f:
f.write(res)
if __name__ == "__main__":
solve()
|
提取完后就可以得到一个加密的压缩包,打开发现里面有个F1a9_test.docx
经过尝试,发现这个压缩包的解压密码是纯数字的弱密码:65537
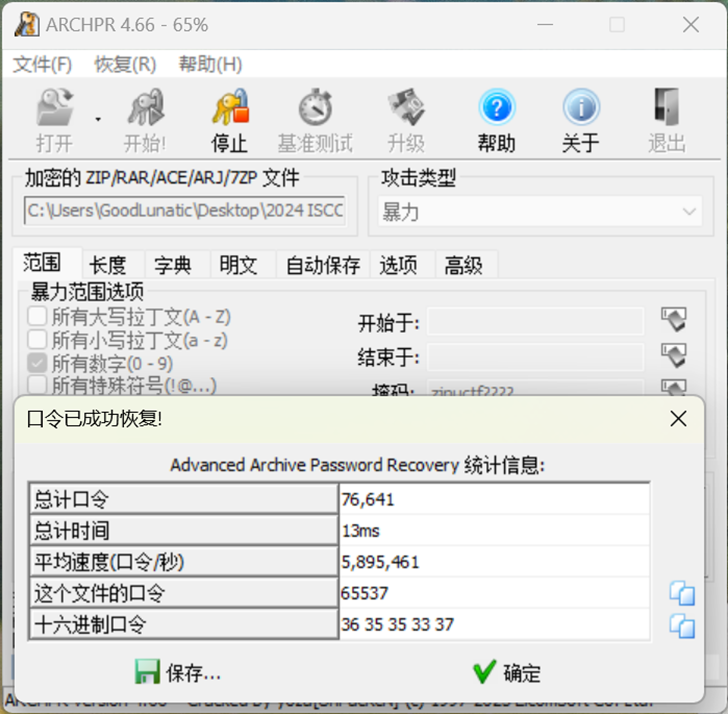
使用爆破得到的密码解压压缩包,打开docx文件,将字体改为红色
并把上面那张白色的图片移开,可以得到一串可疑的数字
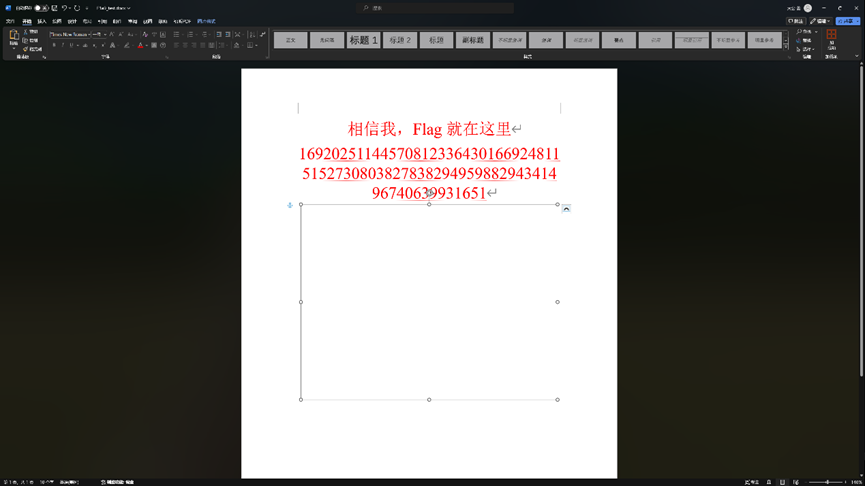
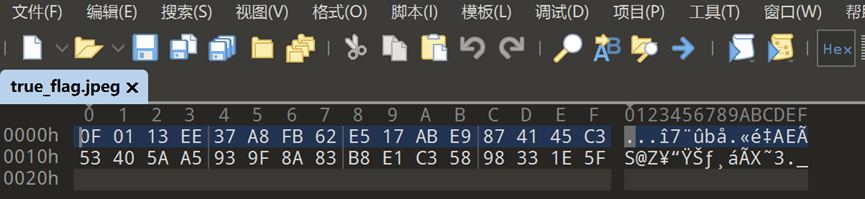
然后我们把docx文件改后缀为.zip并解压
把word\media\true_flag.jpeg这张图片复制出来,然后用010打开

发现内容很短,并且没有明显的文件头特征,所以猜测是加密了
后来经过尝试,发现是使用RSA算法加密了
其实前面的压缩包解压密码65537就提示了是RSA算法,然后e就是65537
先前得到的那串可疑数字就是RSA的n,直接使用在线网站分解即可得到p和q
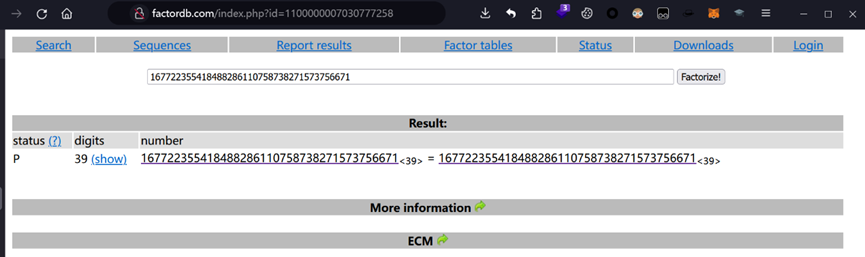
最后运行以下脚本解密RSA即可得到flag:ISCC{0cryBV36G2H3Tc7}
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from Crypto.Util.number import *
with open(r"true_flag.jpeg", 'rb') as f:
c = f.read()
c = bytes_to_long(c)
p = 167722355418488286110758738271573756671
q = 100882503720822822072470797230485840381
e = 65537
d = inverse(e, (p - 1) * (q - 1))
m = pow(c, d, p * q)
print(long_to_bytes(m))
# b'\x02\t\xd3i\x02\xa6J\xa15\x00ISCC{0cryBV36G2H3Tc7}'
|
题目名称 Magic_Keyboard
题目改编自2021pbctf,找到了官方Writeup
参考Writeup,下载这个开源项目
跟着pbctf做法做一遍,只要把threshold值改大就行,能够得到键盘键盘敲得字母
然后发现了其和iscc的十六进制存在对应的单表替换,两位两位爆过去就可以了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
from acoustic_keylogger.audio_processing import *
from acoustic_keylogger.unsupervised import *
from sklearn.preprocessing import MinMaxScaler
from string import hexdigits
hex_num = hexdigits[:16]
table = {
'a': '4',
'b': '9',
'c': '5',
' ': '3',
'e': '7',
'f': 'b',
'g': '6', # 第一次猜测
'h': 'f', # 第二次猜测
'i': '1', # 第三次猜测
'j': '2', # 第三次猜测
'k': '0', # 第四次猜测
'l': 'e', # 第五次猜测
'm': 'c', # 第六次猜测
'n': 'd', # 第七次猜测
}
def get_phrase():
data = wav_read("1.wav")
keystrokes = detect_keystrokes(data)
X = [extract_features(x) for x in keystrokes]
X_norm = MinMaxScaler().fit_transform(X)
letters = {}
phrase = []
current_letter = ord('a')
for x in X_norm:
if x[0] not in letters:
letters[x[0]] = current_letter
current_letter += 1
phrase.append(letters[x[0]])
print("".join([chr(x) for x in phrase]).replace("d", " "))
# abc a a efeegcchgiejgcchgie ekgbejgbglgechekgcghekgmgcen
def guess1(s, guess_str):
for num in hex_num:
tmp = ""
flag = True
for item in s:
if item in table:
tmp += table[item]
elif item == guess_str:
tmp += str(num)
tmp_bytes = bytes.fromhex(tmp) # 必须是偶数个字符
for byte in tmp_bytes:
if (byte < 32 or byte > 126):
flag = False
break
if (flag):
print(f"{tmp_bytes} {guess_str}:{num}")
def guess2(s, guess_str1, guess_str2):
for num1 in hex_num:
for num2 in hex_num:
tmp = ""
flag = True
for item in s:
if item in table:
tmp += table[item]
elif item == guess_str1:
tmp += str(num1)
elif item == guess_str2:
tmp += str(num2)
tmp_bytes = bytes.fromhex(tmp) # 必须是偶数个字符
for byte in tmp_bytes:
if (byte < 32 or byte > 126):
flag = False
break
if (flag):
print(f"{tmp_bytes} {guess_str1}:{num1} {guess_str2}:{num2}")
if __name__ == "__main__":
# print(binascii.hexlify(b'ISCC{')) # 495343437b
s = "abc a a efeegcchgiejgcchgie ekgbejgbglgechekgcghekgmgcen"
guess_str1 = 'n'
# guess_str2 = 'j'
guess1(s, guess_str1)
# guess2(s, guess_str1, guess_str2)
# ISCC{we_are_aspiring_people}
|
题目名称 重“隐”
题目附件给了一个压缩包,解压得到 music.wav 和 picture.png
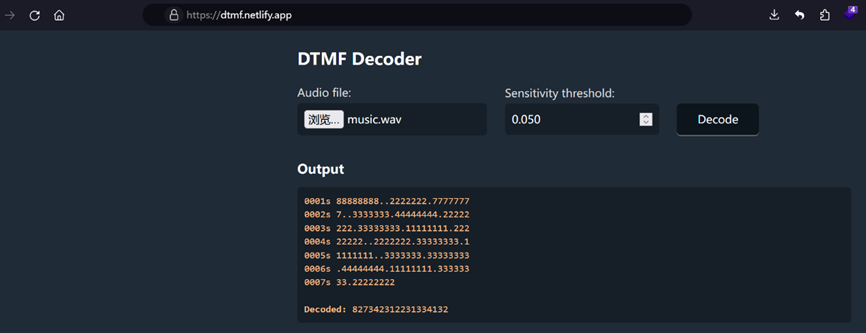
播放那个 wav 文件,发现是DTMF电话音
因此直接使用在线网站识别得到:827342312231334132
经过尝试发现 wav 拉入 deepsound 中会提示需要输入密码
因此猜测这个 wav 文件用 deepsound 隐藏文件了
但是解密需要密钥,经过尝试发现这个密钥可以使用 john 爆破 Hash 值得到
Hash值的生成可以使用网上的deepsound2join.py脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
import logging
import os
import sys
import textwrap
def decode_data_low(buf):
return buf[::2]
def decode_data_normal(buf):
out = bytearray()
for i in range(0, len(buf), 4):
out.append((buf[i] & 15) << 4 | (buf[i + 2] & 15))
return out
def decode_data_high(buf):
out = bytearray()
for i in range(0, len(buf), 8):
out.append((buf[i] & 3) << 6 | (buf[i + 2] & 3) << 4
| (buf[i + 4] & 3) << 2 | (buf[i + 6] & 3))
return out
def is_magic(buf):
# This is a more efficient way of testing for the `DSCF` magic header without
# decoding the whole buffer
return (buf[0] & 15) == (68 >> 4) and (buf[2] & 15) == (68 & 15) \
and (buf[4] & 15) == (83 >> 4) and (buf[6] & 15) == (83 & 15) \
and (buf[8] & 15) == (67 >> 4) and (buf[10] & 15) == (67 & 15) \
and (buf[12] & 15) == (70 >> 4) and (buf[14] & 15) == (70 & 15)
def is_wave(buf):
return buf[0:4] == b'RIFF' and buf[8:12] == b'WAVE'
def process_deepsound_file(f):
bname = os.path.basename(f.name)
logger = logging.getLogger(bname)
# Check if it's a .wav file
buf = f.read(12)
if not is_wave(buf):
global convert_warn
logger.error('file not in .wav format')
convert_warn = True
return
f.seek(0, os.SEEK_SET)
# Scan for the marker...
hdrsz = 104
hdr = None
while True:
off = f.tell()
buf = f.read(hdrsz)
if len(buf) < hdrsz:
break
if is_magic(buf):
hdr = decode_data_normal(buf)
logger.info('found DeepSound header at offset %i', off)
break
f.seek(-hdrsz + 1, os.SEEK_CUR)
if hdr is None:
logger.warn('does not appear to be a DeepSound file')
return
# Check some header fields
mode = hdr[4]
encrypted = hdr[5]
modes = {2: 'low', 4: 'normal', 8: 'high'}
if mode in modes:
logger.info('data is encoded in %s-quality mode', modes[mode])
else:
logger.error('unexpected data encoding mode %i', modes[mode])
return
if encrypted == 0:
logger.warn('file is not encrypted')
return
elif encrypted != 1:
logger.error('unexpected encryption flag %i', encrypted)
return
sha1 = hdr[6:6+20]
print('%s:$dynamic_1529$%s' % (bname, sha1.hex()))
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--verbose', '-v', action='store_true')
parser.add_argument('files', nargs='+', metavar='file',
type=argparse.FileType('rb', bufsize=4096))
args = parser.parse_args()
if args.verbose:
logging.basicConfig(level=logging.INFO)
else:
logging.basicConfig(level=logging.WARN)
convert_warn = False
for f in args.files:
process_deepsound_file(f)
if convert_warn:
print(textwrap.dedent.rstrip(), file=sys.stderr)
|
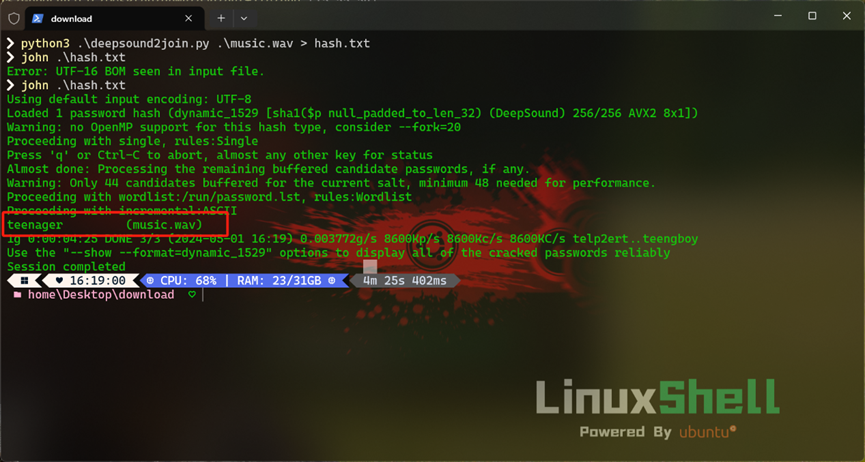
运行以上代码后就可以得到以下 Hash 值:
music.wav:$dynamic_1529$4e93a8873afa884dff4909f912f792ca9986c142
然后直接使用 john hash.txt 命令爆破即可得到密钥:teenager
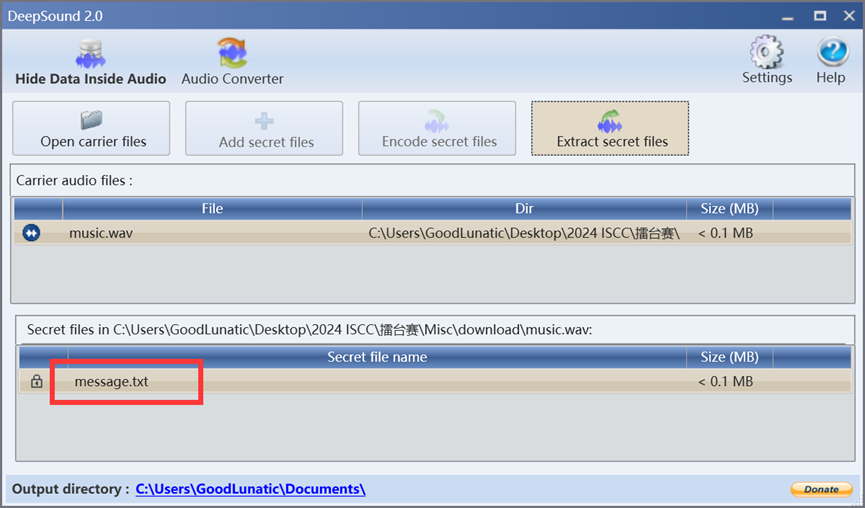
使用密钥解密deepsound后可以得到一个message.txt
message.txt 内容如下

发现存在很多不可见字符,直接使用PuzzleSolver解密
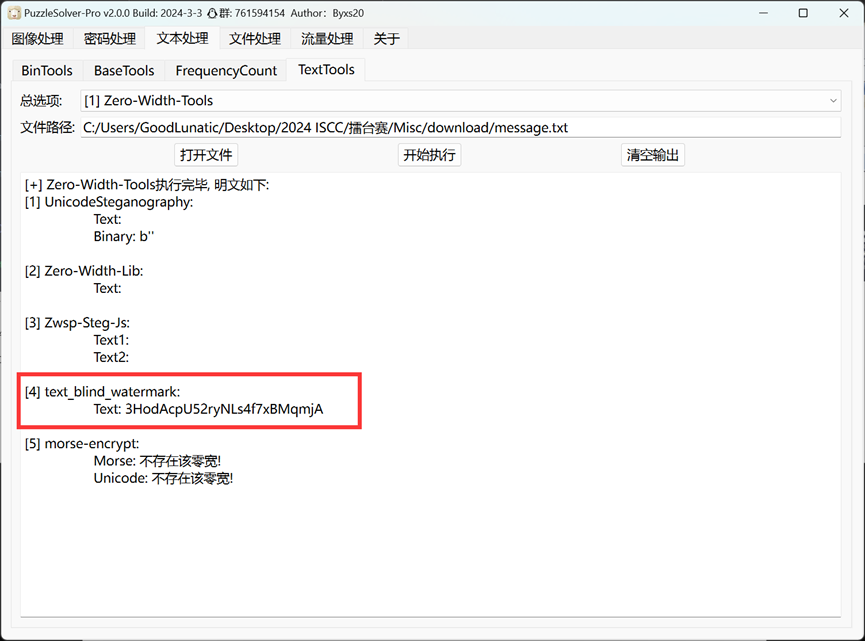
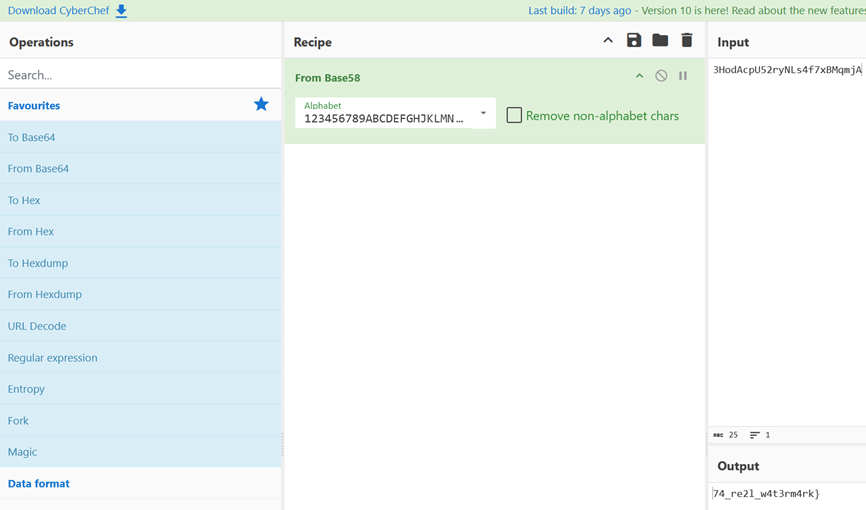
将得到的字符串base58解码即可得到后半段的flag:74_re2l_w4t3rm4rk}
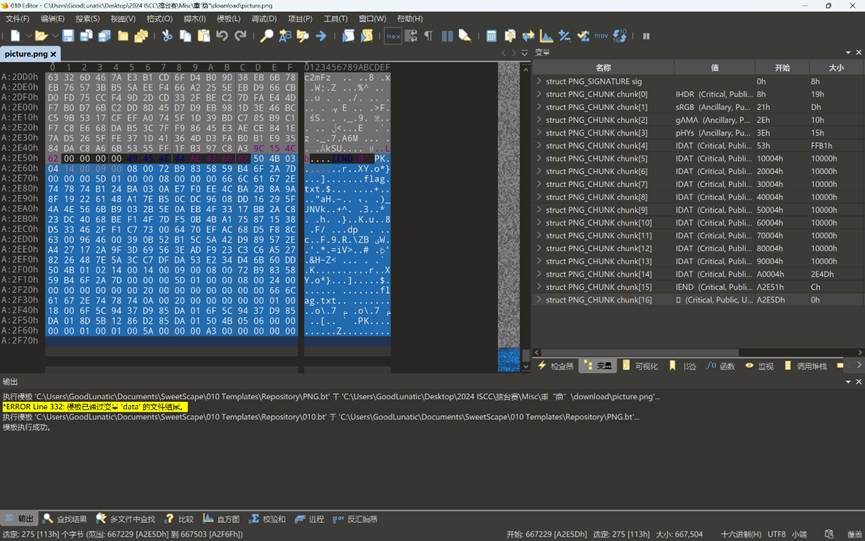
然后再来看那张png图片,010打开发现图片末尾有一个压缩包
这里直接使用010手动提取出这个压缩包
打开提取出的压缩包,发现需要密码
这时候想到之前DTMF识别出的内容还没有使用
因此可以大胆猜测密码与之前识别出的内容有关
在经历了各种编码和加密的尝试后,最终发现是手机九宫格键盘密码
参考链接:https://blog.csdn.net/qq_55011640/article/details/123626280
根据参考文章解码即可得到:URHDBDFGE
对应方式如下所示:
82 73 42 31 22 31 33 41 32
U R H D B D F G E
解压压缩包后可以得到flag.txt,打开后发现里面是 brainfuck

直接使用随波逐流解密即可得到前半段的flag:ISCC{y0u_f1nd_t
最后两段flag合起来即可得到最后的flag:ISCC{y0u_f1nd_t74_re2l_w4t3rm4rk}
题目名称 World Line
题目附件给一个压缩包,解压后得到两个文件夹α和β
我们首先看α,里面有一个C【hristina】.jpg,一个key.zip,和一个重新来过.txt
txt文件中的内容如下:
1
|
AK5O3BaZi+p1ci0JxythDZWToTXkFj4dexQ3cOAmYfUwtUVyJahFOcNroC8nAsHyCnmiuOOpJYyOWBV5npW3pg==
|
hints:【加】密过程中,请在不够64个字符的密文后面补 0
看到长度不足64,要在后面补0,想到DES的Zero padding方式
但是DES解密需要密钥,经过尝试,发现密钥就是那个jpg文件名中【】包裹的内容:hristina
知道密钥后直接在线网站解密即可
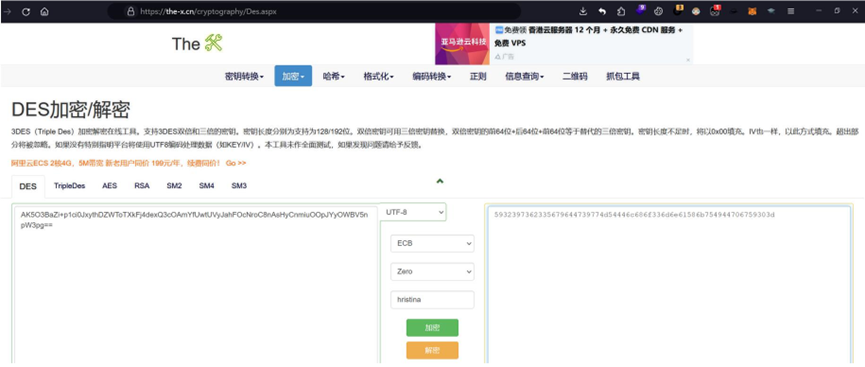
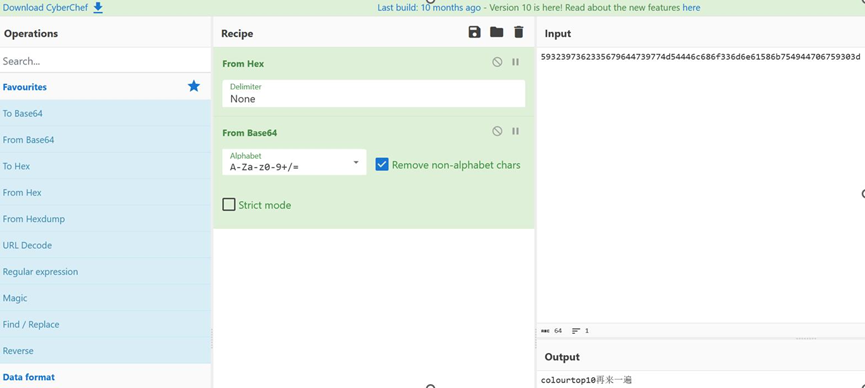
然后再用CyberChef解码hex并解码base64即可得到一个提示:
colourtop10再来一遍
因此这里猜测需要提取jpg图片中出现频率前十的像素值
但是提取出来后,并没有发现明显的提示
打开key.zip,发现里面有一个key.jpg和一个α.zip
然后再来看β文件夹中的内容,里面有一个椎名真由理文件夹
一个epilogue.txt,一个RSA.py,还有一个βase64.txt
βase64.txt中是一串base64编码的字符串,直接CyberChef解码一下
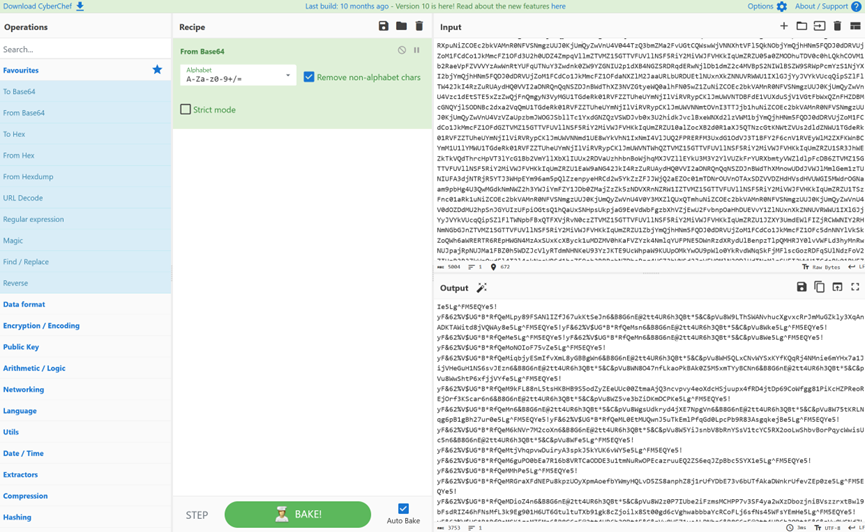
仔细观察,发现里面有如下重复的内容:
e5Lg^FM5EQYe5!yF&62%V$UGBRfQeM
直接上网搜索一下,发现在2024NKCTF中出现过
然后打开那个RSA.py,内容如下:
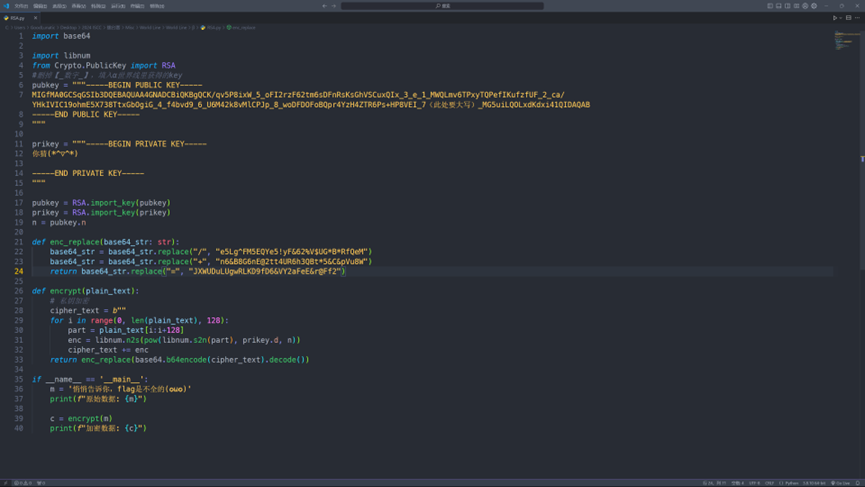
发现和上面2024NKCTF的那道题的加密代码非常非常的像
删去_数字_后,公钥都是一模一样的,因此可以大胆猜测私钥也是一样的
因此我们可以直接尝试用2024NKCTF的那个解密来对我们上面的那个密文进行解密,解密脚本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
import base64
import libnum
from Crypto.PublicKey import RSA
from urllib.parse import unquote
pubkey_str = """-----BEGIN PUBLIC KEY-----
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCK/qv5P8ixWjoFI2rzF62tm6sDFnRsKsGhVSCuxQIxuehMWQLmv6TPxyTQPefIKufzfUFaca/YHkIVIC19ohmE5X738TtxGbOgiGef4bvd9sU6M42k8vMlCPJp1woDFDOFoBQpr4YzH4ZTR6Ps+HP8VEIJMG5uiLQOLxdKdxi41QIDAQAB
-----END PUBLIC KEY-----
"""
prikey_str = """-----BEGIN PRIVATE KEY-----
MIICdgIBADANBgkqhkiG9w0BAQEFAASCAmAwggJcAgEAAoGBAIr+q/k/yLFaOgUjavMXra2bqwMWdGwqwaFVIK7FAjG56ExZAua/pM/HJNA958gq5/N9QVpxr9geQhUgLX2iGYTlfvfxO3EZs6CIZ5/hu932xTozjaTy8yUI8mnXCgMUM4WgFCmvhjMfhlNHo+z4c/xUQgkwbm6ItA4vF0p3GLjVAgMBAAECgYBDsqawT5DAUOHRft6oZ+//jsJMTrOFu41ztrKkbPAUqCesh+4R1WXAjY4wnvY1WDCBN5CNLLIo4RPuli2R81HZ4OpZuiHv81sNMccauhrJrioDdbxhxbM7/jQ6M9YajwdNisL5zClXCOs1/y01+9vDiMDk0kX8hiIYlpPKDwjqQQJBAL6Y0fuoJng57GGhdwvN2c656tLDPj9GRi0sfeeMqavRTMz6/qea1LdAuzDhRoS2Wb8ArhOkYns0GMazzc1q428CQQC6sM9OiVR4EV/ewGnBnF+0p3alcYr//Gp1wZ6fKIrFJQpbHTzf27AhKgOJ1qB6A7P/mQS6JvYDPsgrVkPLRnX7AkEAr/xpfyXfB4nsUqWFR3f2UiRmx98RfdlEePeo9YFzNTvX3zkuo9GZ8e8qKNMJiwbYzT0yft59NGeBLQ/eynqUrwJAE6Nxy0Mq/Y5mVVpMRa+babeMBY9SHeeBk22QsBFlt6NT2Y3Tz4CeoH547NEFBJDLKIICO0rJ6kF6cQScERASbQJAZy088sVY6DJtGRLPuysv3NiyfEvikmczCEkDPex4shvFLddwNUlmhzml5pscIie44mBOJ0uX37y+co3q6UoRQg==
-----END PRIVATE KEY-----
"""
pubkey = RSA.import_key(pubkey_str)
prikey = RSA.import_key(prikey_str)
n = pubkey.n
def dec_replace(base64_str: str):
base64_str = base64_str.replace("e5Lg^FM5EQYe5!yF&62%V$UG*B*RfQeM", "/")
base64_str = base64_str.replace("n6&B8G6nE@2tt4UR6h3QBt*5&C&pVu8W", "+")
base64_str = base64_str.replace("JXWUDuLUgwRLKD9fD6&VY2aFeE&r@Ff2", "=")
return base64_str
def decrypt(cipher_text):
# 使用公钥解密
plain_text = b""
cipher_text = base64.b64decode(dec_replace(cipher_text))
for i in range(0, len(cipher_text), 128):
part = cipher_text[i:i+128]
dec = libnum.n2s(pow(libnum.s2n(part), pubkey.e, n))
plain_text += dec
return plain_text.decode()
if __name__ == '__main__':
cipher_text = input("请输入要解密的密文: ")
cipher_text = unquote(cipher_text)
decrypted_text = decrypt(cipher_text)
print("解密后的明文为:", decrypted_text)
|
解密结果如下:
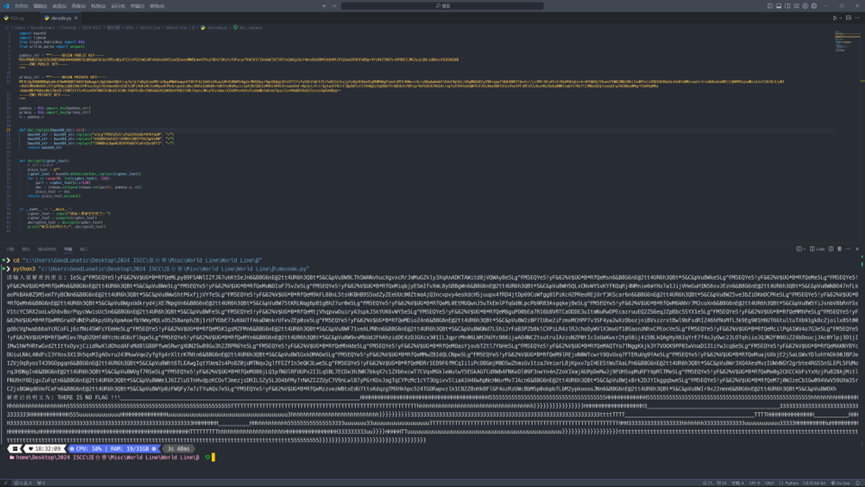
虽然它说这里没有flag,但是发现里面有很多重复的可疑字符
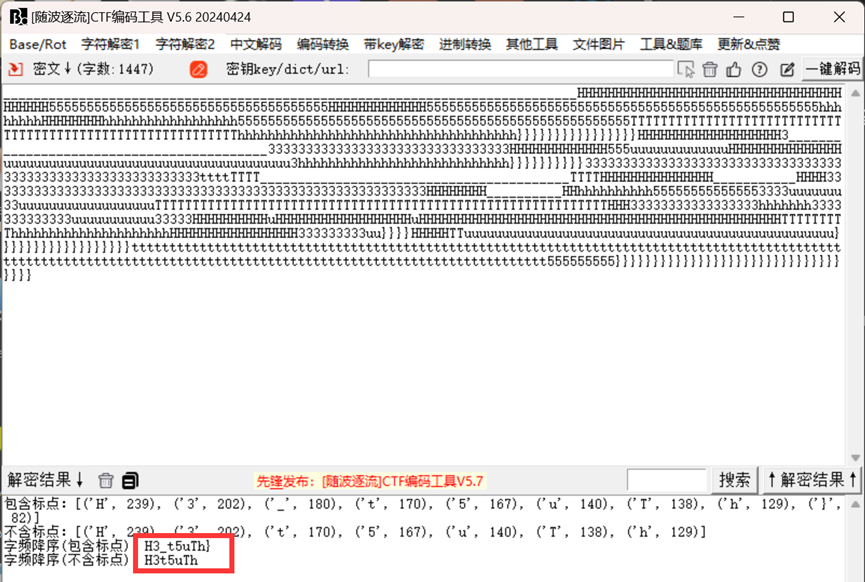
使用随波逐流进行字频统计后可以得到一部分的flag:H3_t5uTh}
上面那个加密代码和2024NKCTF一模一样应该算是出题人的失误吧,也算是非预期了。
其实获得私钥的正常流程是下面这样的:
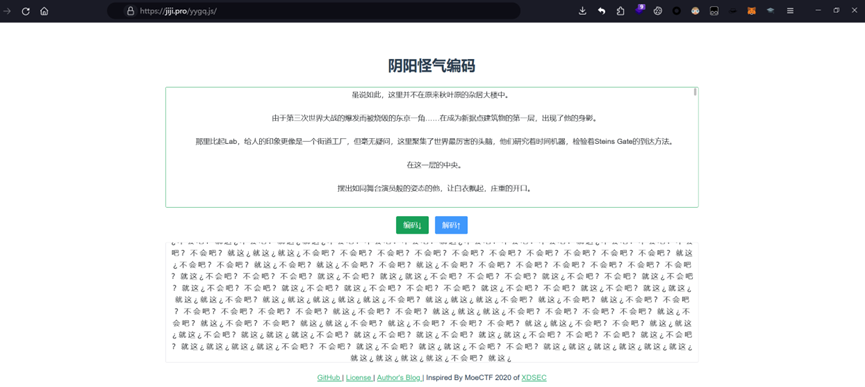
打开epilogue.txt,发现里面都是 不 会 吧 ? 就 这 ¿
上网搜索后,知道了是阴阳怪气编码,直接在线网站解密即可
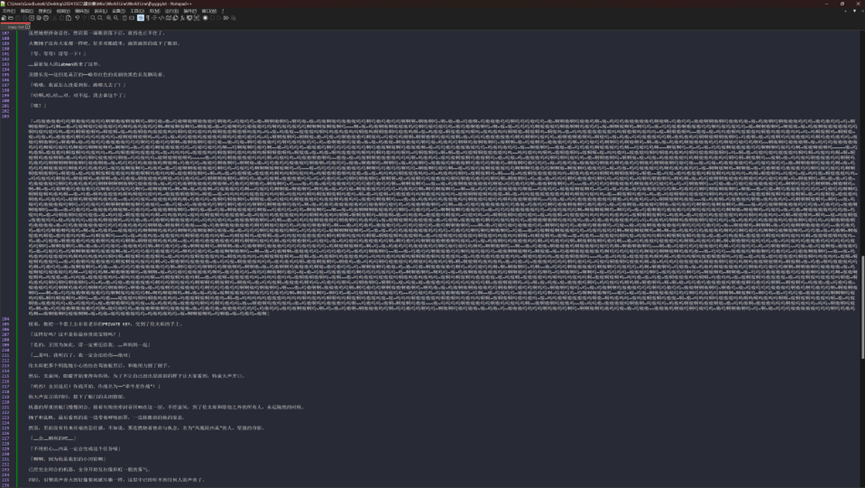
在得到的解密结果中,发现有 嗷呜 兽语加密,直接使用在线网站解密
兽音译者解密得到的结果补上“+“号,就是上面加密代码的私钥了
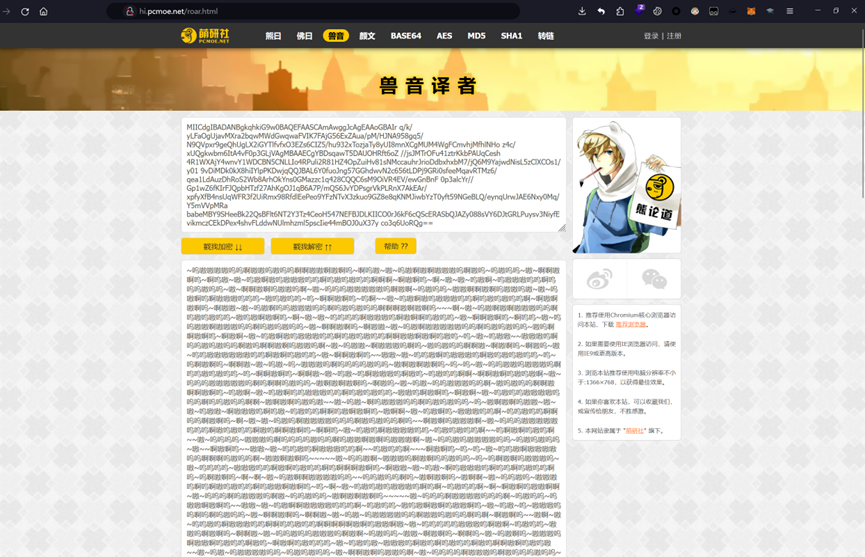
然后我们继续看 椎名真由理 文件夹中的内容
打开后发现有一个β.jpg和一个β文件夹,β.jpg中有很多小点
然后β文件夹中有一个8787文件夹和0.png-572.png
用Puzzle-Merak稍微拼一下,就知道分辨率和外面的β.jpg是一样的,都是1280x720
因为每块碎片的长宽是40x40,因此正常来说应该有32x18=576张碎片
1
|
magick montage *.png -tile 32x18 -geometry +0+0 flag-0.png
|
仔细观察碎片的名称,发现有123_9049 (0U_f4N).png和321_19704.png
0U_f4N应该也是flag的一部分
然后我们再看8787文件夹,里面有一个快来破解.zip
其中的key.txt和key.png是没有加密的,因此我们直接拖出来
key.png内容如下,猜测gdE_t也是flag的一部分
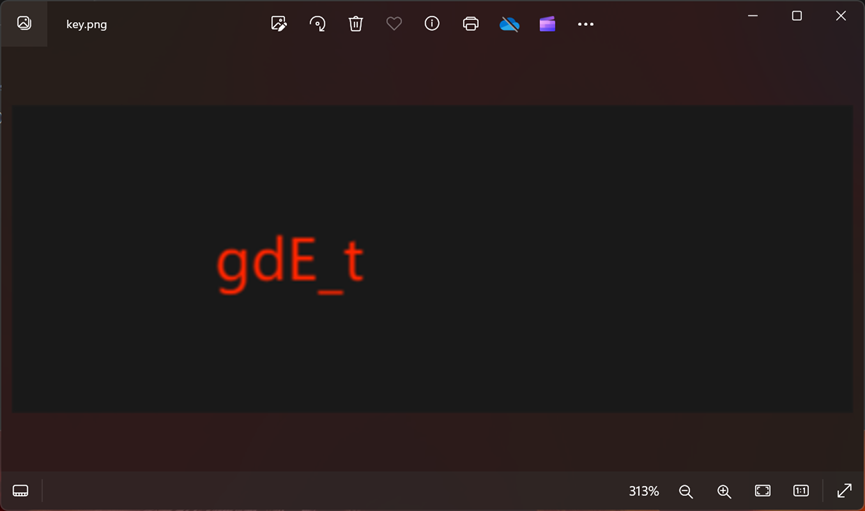
然后key.txt给了如下提示:有key有图片,该怎么办呢
因此我猜测gdE_t也是key
回头去查看那个有很多拼图碎片的β文件夹,发现321_19704.png的创建时间和别的都不一样
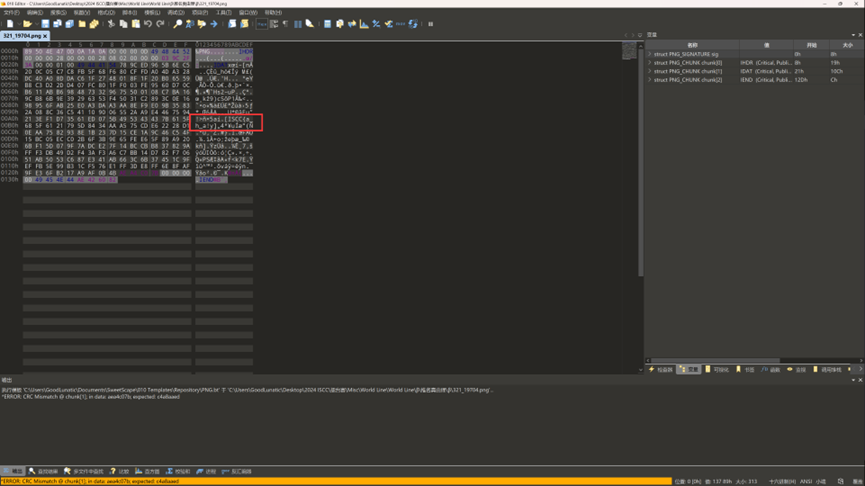
感觉应该有点问题,因此我们使用010打开查看
仔细观察图片的数据,就可以发现flag的第一部分:ISCC{a_h_a!y
最后将上面得到四部分结合起来,发现就是完整的flag:ISCC{a_h_a!y0U_f4NgdE_tH3_t5uTh}
这道题我也不知道出题人具体是怎么想的,感觉还有很多东西都没用上,但是东拼西凑一下也可以得到最后的flag,很难评只能说。。。
题目名称 数据泄露
题目附件给了一个pcap流量包,打开后发现主要是TCP、HTTP、DNS流量
根据题目给的提示,是要分析DNS隧道工具的原始文件名
因此我们重点关注DNS流量
参考了以下几个网上的链接:
https://teamssix.com/210608-150224.html
https://www.freebuf.com/articles/web/282552.html
https://www.freebuf.com/articles/security-management/214923.html
结合题目给的流量包分析,猜测响应的内容应该是在TXT类型记录中
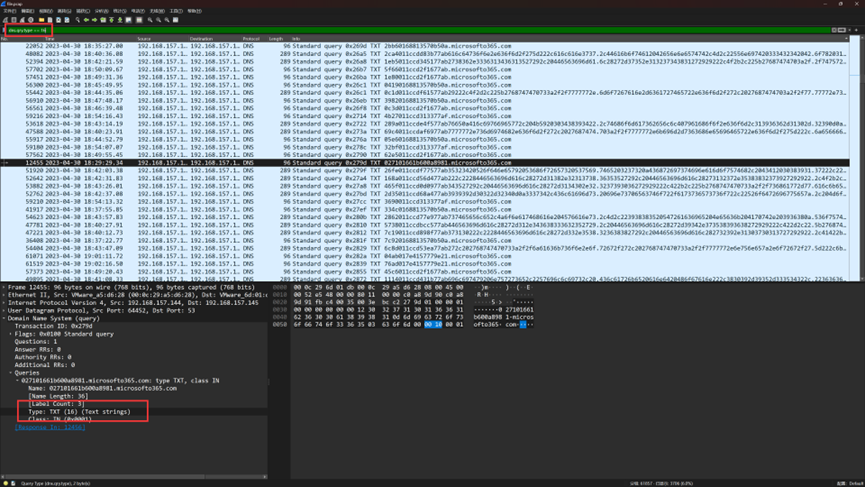
因此我们使用Wireshark自带的过滤器过滤出带有TXT类型记录的流量包
dns.qry.type == 16
域名前缀就是响应的内容,看着像是简单十六进制编码了的字符串
用CyberChef尝试解码了几个,发现只有长度较长的可以正常解码
因此我们用过滤器过滤出长度较长的流量,并导出特定分组
len(dns.qry.name) >65
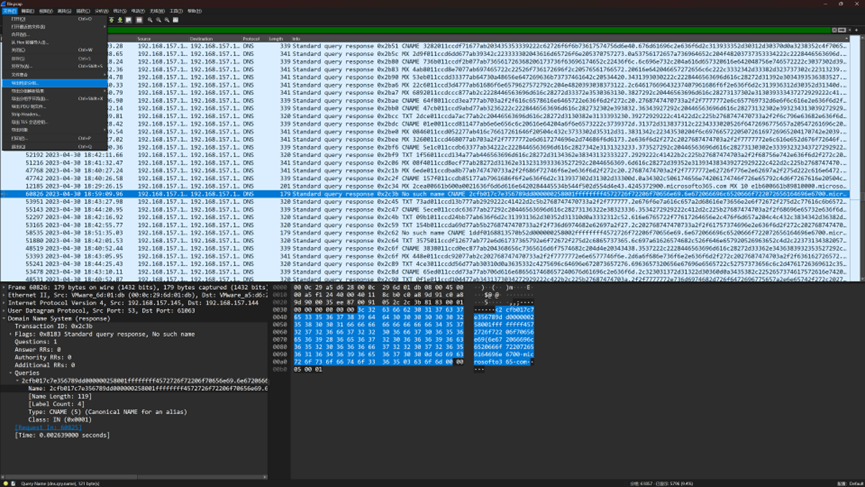
然后使用tshark提取dns.qry.name字段的数据

然后把提取出的数据中的.microsofto365.com删除
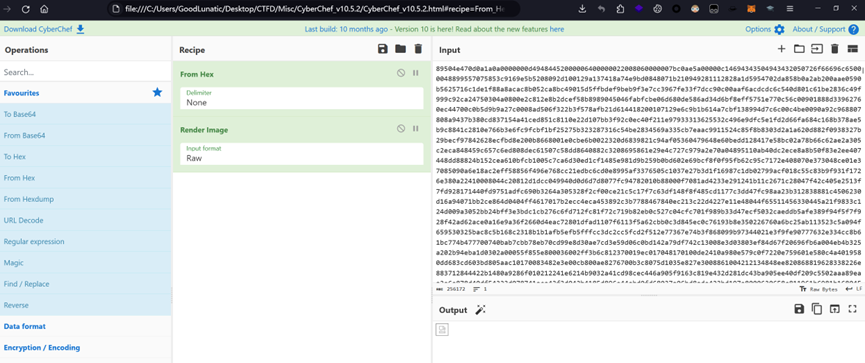
最后把所有数据复制到CyberChef中解码十六进制
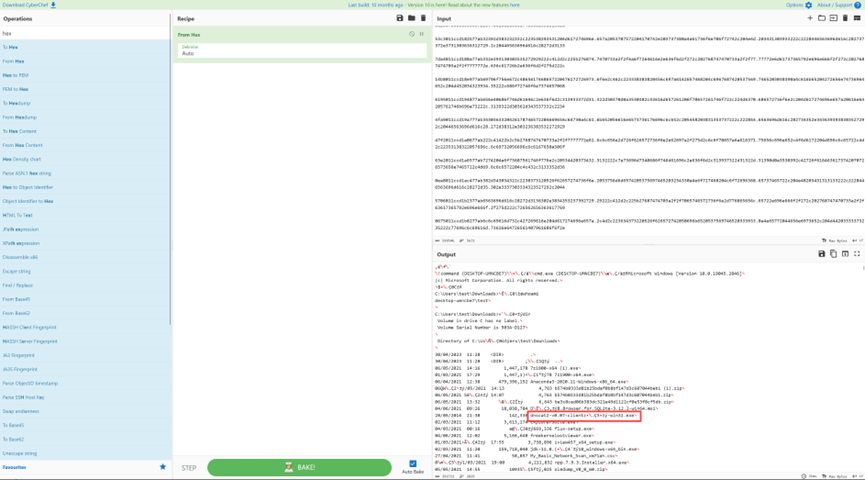
在解码结果中发现了dnscat2-v0.07-clientz.Ç3±ý-win32.exe这个常见的DNS隧道工具(常见的几个DNS隧道工具上面的参考文章中有提到)
这里解码出来的名字是不全的,因此我们去网上搜索这个工具
然后可以找到一个下载链接
下载这个压缩包,打开就可以看到完整的工具名了
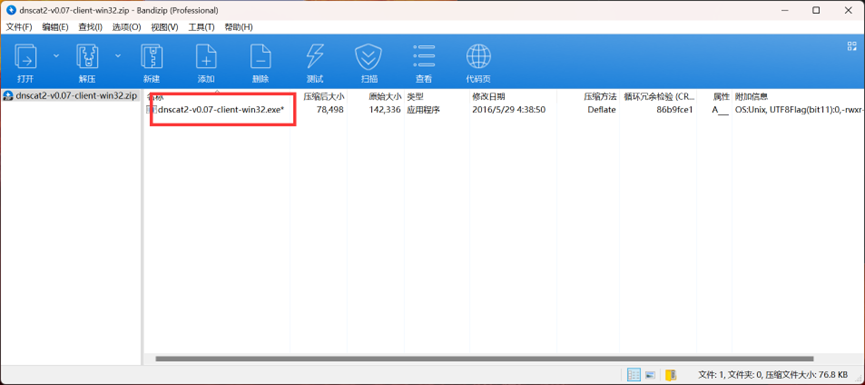
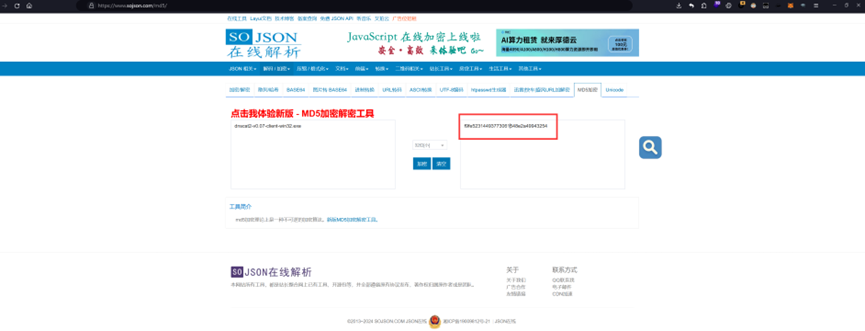
最后再md5加密一下,套上ISCC{}即可得到最后的flag:ISCC{f9fe52314493773061548e2a49943254}
 Lunatic
Lunatic